VMwareは2019年8月に開催されたVMworldにおいて、KubernetesをvSphere上でネイティブ動作させるプロジェクト「Project Pacific」を発表した。Kubernetesのオリジナルのデベロッパーの一人で、VMwareに買収されたHeptioのCEOだったJoe Beda氏と、VMwareのCEOであるPat Gelsinger氏がキーノートで発表したものだ。今回は、より詳細な動画を参照しつつ、技術的な解説を行ってみたい。
初日のGeneral Sessionとして行われたものの一部として、VMware Tanzuとその中核となるProject Pacificが発表された。公式動画は以下を参照していただきたいが、肝心のパートはJoe Beda氏が登壇した33分ごろから始まる。

VMware Tanzuの説明
VMworld 2019 US Day 1 General Session
ここでGelsinger氏は、Joe Beda氏をKubernetesの最初のコミッターであり、すでにKubernetes界のセレブリティの一人として紹介した。そして、デベロッパーと運用管理という2つの利用者にとって、レガシーなシステムとクラウドネイティブなシステムの双方をサポートすることの重要性を説明することから始めた。VMwareのCEOであるGelsinger氏がクラウドネイティブだけではなく、レガシーなシステムも管理運用する重要性を語るのは当たり前だろう。なぜなら、VMwareのメインストリームのビジネスは仮想マシンであるからだ。クラウドネイティブなコンピューティングスタイルから見れば、仮想マシン自体がすでにレガシーという扱いだが、VMwareにとっては無視できない存在である。
Gelsinger氏が紹介した「VMware Tanzu」と名付けられた製品(もしくはコンセプト)は「Build Modern Apps」「Run Enterprise Kubernetes」「Manage Kubernetes for Developers and IT」という3つの柱から構成されている。
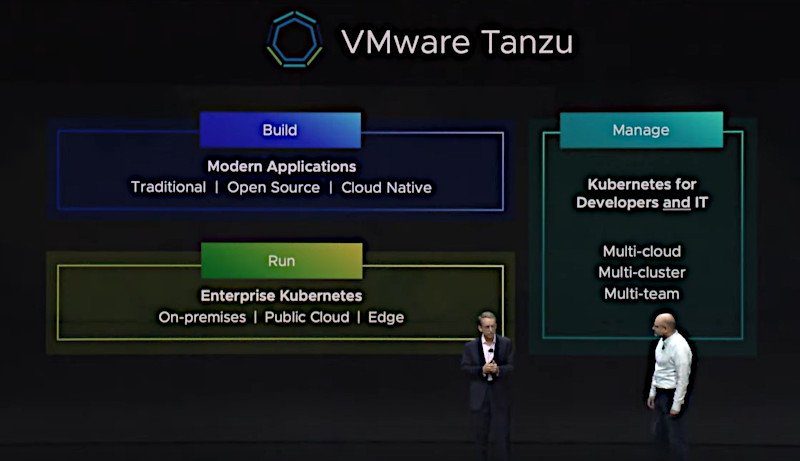
Tanzuは日本語の「箪笥」からきているらしい
そのうちのBuild Modern Appsの部分を担うのは、2019年5月にVMwareが買収したBitnamiと8月に買収を発表したPivotalだ。BitnamiはKubernetesのアプリケーションカタログであるKubeappsを開発するベンチャーだ。一方PivotalはCloud Foundryの開発をリードする企業であり、同時に12ファクターアプリケーションの提唱とアジャイル開発の方法論であるペアプログラミングを推進するコンサルティングを提供するPivotal Labsを持つ企業でもある。
その2つを訴求するだけでは、クラウドネイティブなアプリケーションしか対応しないように聞こえるだろうが、仮想マシンのパイオニアであるVMwareにとっては既存の仮想マシンをヘビーに使う顧客に対する回答としては不十分だろう。そこで登場したのがProject Pacificだ。

Project Pacificの紹介
特徴的なのは、Kubernetesに対応するために仮想マシンを実行するコアとなるESXiというVMwareの誇るハイパーバイザーの上で、ネイティブにKubernetesを実行できることだろう。
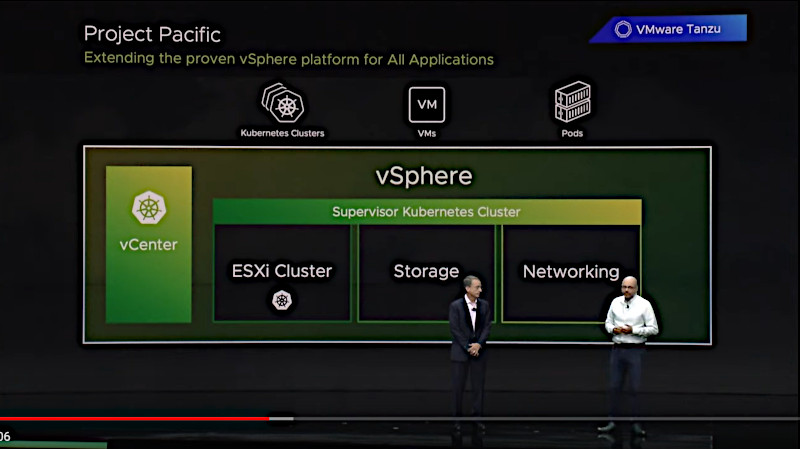
Pacificの概念的な構造
ここで注目するべきはvCenterという管理コンソール、vSphere配下のストレージ、ネットワークというお馴染みのスタックの上に、「Supervisor Kubernetes Cluster」という新たなレイヤーが差し込まれていることだ。そしてそのSupervisor Kubernetes Clusterの上で、さまざまなアプリケーションが稼働するという部分だろう。それはそのレイヤーのさらに上に、Kubernetesのクラスターと仮想マシン、KubernetesのPodが稼働する単位として描かれていることでも理解できる。
このシステムの構造に関する話は後半の別の解説動画をベースに詳しく説明を行うが、この段階でGelsinger氏とBeda氏が強調したのは、Linuxの仮想マシンの上で稼働させたKubernetesクラスターと比べて30%高速になったこと、さらにベアメタルの上で稼働させたKubernetesクラスターよりも8%高速に稼働したという部分だ。これはvSphereの上で仮想マシンを使わずにKubernetesクラスターを実行することで、Linuxのオーバーヘッドがなくなったこと、そしてベアメタルサーバーにLinuxだけを載せてその上でKubernetesを動かした場合よりも高い性能を叩き出したというメッセージだ。
これが第3者による検証可能なベンチマーク結果であるかどうかは、今後、ブログなどにおける見解を待ちたいと思うが、VMworldに集まったvSphereユーザーからすれば、仮想マシンのパイオニアのVMwareがKubernetesをハックして高速化を行ったという離れ技に見えただろう。

Linuxホストよりも30%高速、ベアメタルよりも8%高速
ちなみに30%、8%高速という部分に関してはこのブログ記事がソースであろう。
Project Pacific ? Technical Overview
そして3つ目の柱であるマネージメントの部分は、「Tanzu Mission Control」という製品が担うことも発表された。Mission Controlは一つの管理コンソール(ここはもちろんvCenterだろう)からすべてのKubernetesクラスターが管理できることを目指しているという。

Tanzu Mission Controlの紹介
ここまでの発表では、VMware Tanzuというブランドを立ち上げ、PivotalのManaged KubernetesサービスであるPKSやJavaの開発環境であるSpringBootを将来的にKubernetesに対応させること、クラウドネイティブなアプリケーションにはBitnamiのKubeAppsを組み合わせて提供すること、実行の部分ではVMwareの既存顧客が信頼を寄せるvSphereにネイティブなKubernetesを載せたこと、さらにMission Controlで3大パブリッククラウドベンダーのプラットフォームに加えてオンプレミスのKubernetesを管理できること、以上の点が伝えられたという理解で良いだろう。
ではその中核となるProject Pacificとは何か? について詳しく説明したい。これについては、VMworldのセッション、Project Pacific Technical Overviewの動画をベースにしている。
元となったVMwareのブログ記事は以下を参照されたい。
以下の動画はTech Field Dayというメディアがブリーフィングの内容として公開されているもので、動画そのものはVMware公式ではないが、VMwareのプロダクト責任者がプレゼンテーションを行っていることから内容としては「公式見解」と言えるだろう。
VMware Introduction to Project Pacific
解説を行っているのはJared Roseff氏で、肩書はSenior Director Product Managementである。Roseff氏はデベロッパーと運用管理者はそれぞれのニーズを持ち、それは相反する場合が多いということを解説。つまりデベロッパーはクラウドネイティブなアプリケーションを開発したら、すぐにでも実行したいが、一方で運用管理者はクラウドネイティブなアプリケーションだけではなくデータベースなどのステートフルなアプリケーションやレガシーなアプリケーションも運用する必要があり、何よりも安定を望んでいる。これらの対立する2つのニーズを満たすために、接点が必要だと語る。
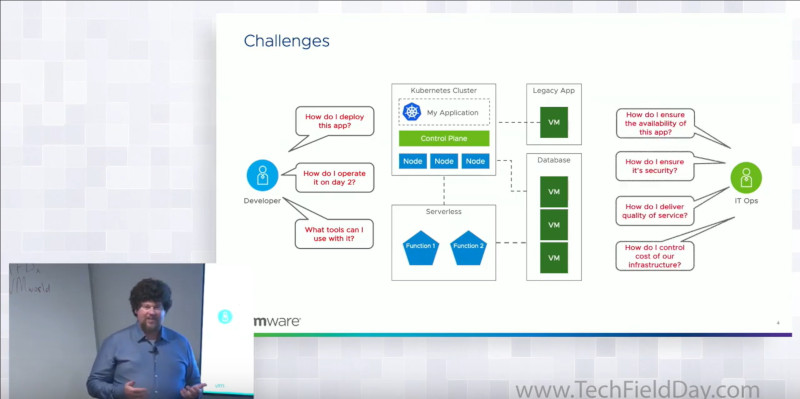
デベロッパーと運用管理者のニーズの違い
そこでVMwareが選択したのはvSphere上でSupervisor Kubernetes Clusterを稼働させる、つまりLinuxではなくESXi上でKubernetesに必要な各種サーバーを動かすというものだ。つまり通常のKubernetesであればLinuxカーネルがベースにあるが、それをESXiに置き換えたものになる。
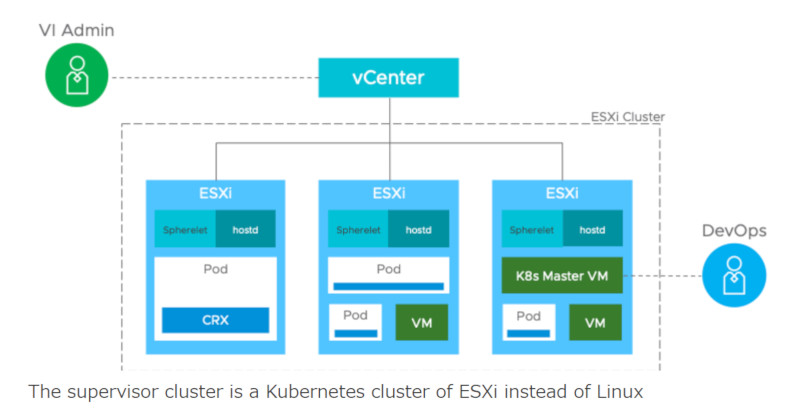
Linuxの代わりにESXiがホストとしてKubernetesを実行
そしてその上で通常のKubernetesクラスターや仮想マシンなどを稼働させるという構造になる。また管理は、Kubernetesに合わせてネームスペースを使う。
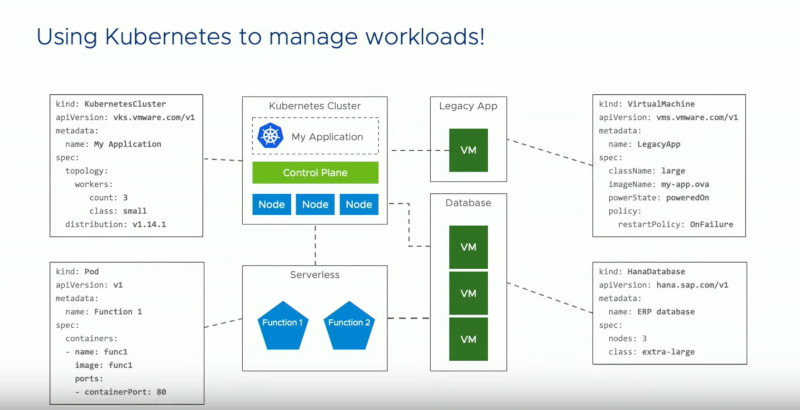
Kubernetesがすべてのワークロードを管理する方法へ
このスライドではKubernetesクラスターが管理する対象として、Kubernetes Cluster、Pod、VirtualMachine、HanaDatabaseが例として挙げられている。ここで注意が必要なのは、Kubernetes自体を使ってKubernetesをコントロールする対象にする、というアプローチだ。これはAlibabaが提唱するKubernetesのマルチテナンシーの実装方法、Kubernetes on Kubernetesに通じるものと言えるだろう。Supervisor Kubernetes ClusterはESXiの上で稼働し、ESXiの上で通常の仮想マシンやデータベース、レガシーアプリケーション、さらに別のKubernetesクラスターを管理するという発想だ。
それをさらに拡張することで、Podだけではなくサーバーレスにも適用できる。これはKubernetesのサーバーレス実装であるKnativeにも通じる発想で、デベロッパーに直接Kubernetesを触らせずに抽象化することを目指しているというのは、IBMのDoug Davis氏のインタビューでも何度も語られた内容だ。Knativeも目指すのはサーバーレスだけではなく、仮想マシンもPodもKubectlを操作せずに容易に実行することがゴールであるという。
そして管理についても、これまでのVMwareのスタイルではなくあくまでもKubernetes由来の手法であるNamespaceを使うことで、管理対象となるオブジェクト(VMwareの管理コンソールであるvCenterから管理できる仮想マシン、ネットワーク、ストレージなど)に対しても統一的なビューを提供できるという。
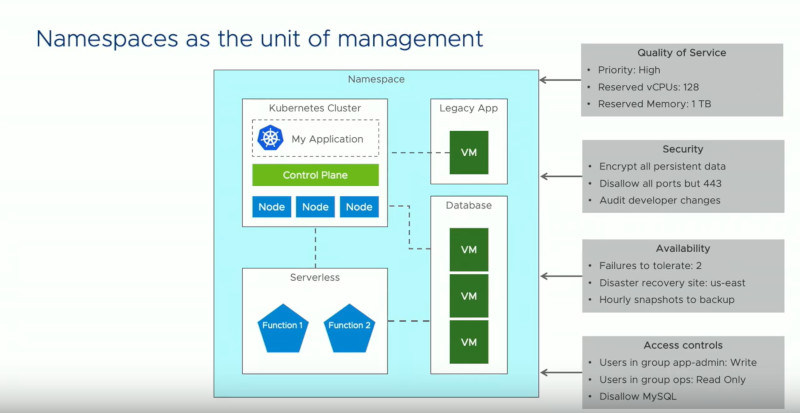
ネームスペースを管理に使う
管理コンソールであるvCenterそのものは変わらないものの、対象にNamespaceというこれまでのVMwareユーザーにとっては新しいコンセプトを導入することで、仮想マシンについてもネームスペースで管理が容易になるという。ここまでを概観すると、仮想マシンベースの管理体系にKubernetesのネームスペースを追加することで、これまでのvCenterユーザーにも利益を与えることができ、同時にKubernetesの管理に慣れたクラウドネイティブなデベロッパーにも新たな学習コストを要求しないコンビネーションを選んだということだろう。
もちろん、このシステムから最大の価値を得るのは、これまでのVMwareユーザーであることはまちがいない。そのための一歩としては上出来と言えるだろう。
ちなみにKubernetesから仮想マシンを立ち上げるという部分に関しては、Operator FrameworkやKubernetesのSIGであるLifecycle SIGが開発するCluster-APIが使われており、新しいオブジェクトなどにはCustom Resource DefinitionとControllerというKubernetesの作法に従った実装が行われていることがわかる。

OperatorとCRDを説明するMichael West氏
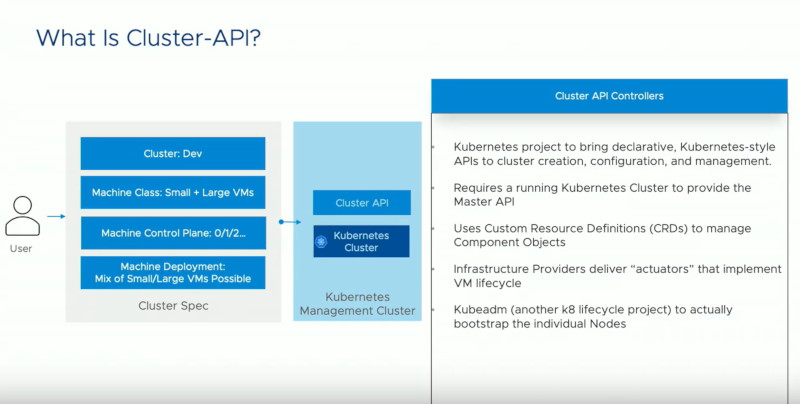
Operatorが利用するCluster-APIの説明
以下のスライドでPacificの全体的な構造を理解することができる。

Pacificの構造
最下層にある「SDDC」というのはVMwareが近年、言い始めた「Software Defined Data Center」の略で、要はESXiの上にすべてのソフトウェアモジュールを載せることで、データセンターをソフトウェアだけで実装できるというコンセプトだ。
その上に今回の中核となるSupervisor Kubernetes Clusterが存在し、その上に管理の概念としてのNamespaceそしてそのNamespaceごとに隔離された仮想マシンやESXiに特化したPodが存在する。さらにその上に、通常のKubernetesクラスターが実装されるという仕組みだ。
Kubernetesのロゴの下のVMというのはこの場合、Linuxになり、その下にManaged Kubernetes Clusterというものが存在する。それを実装するのがCluster-API、MachineDeploymentという標準APIである。
Supervisor Kubernetes ClusterのレベルにKubernetes OperatorとManaged Kubernetes Operatorが存在する理由は簡単で、Managedの方の目的に特化して簡素化された構成情報を与えると、Operatorが実際にKubernetesを操作するために必要なYAMLファイルを生成して、Kubernetes Operatorが実装を担当するという役割であるという。つまり定型化したクラスターであれば、Managed Kubernetes Operatorを使えば良いという発想だ。これはまだKubernetesに慣れていないデベロッパーのためのもので、数十行のYAMLファイルで必要なクラスターが作成可能だという。
実際には、このOperatorは書かれたYAMLファイルから実装に必要となる数百行のYAMLファイルを生成し、それをKubernetes Operatorに渡すという処理になるという。Cluster-APIは非常にパワフルで何でもできてしまうので、それをすべてのデベロッパーに開放するのではなく、抽象化するためのものであるという。同じKubernetesのクラスターでもSupervisor Kubernetes Clusterは運用チームが使うもの、あまり更新もせずに安定した稼働をさせるためのもの、マネージメントレイヤーのコンポーネントであるという。
ESXiの上でKubernetesを直接稼働させることになったのか? について、より詳細な解説を知りたい場合は以下の動画を参照して欲しい。
TechFieldDayのプレゼンテーション:VMware How Project Pacific Was Created for vSphere
Project Pacificにより、VMwareは既存の仮想マシンベースの顧客に同じ管理ツールからKubernetesを使う選択肢を与えた。もちろん、先端的な顧客はすでにUpstreamなKubernetesの検証や本番環境への適用も進めているだろうが、これまでのvCenterベースで管理が可能というのは大きな利点だろう。
ただWorker NodeのエージェントであるKubeletをSphereletとして再実装、PodのランタイムもLinux Kernelを用いてCRXとして実装するなど、言わば「魔改造」を行っていることが今後のKubernetesのコミュニティからどう評価されるのか、興味をもって注視したい。
- この記事のキーワード
関連記事
CNCFのサンドボックスプロジェクト、カオスエンジニアリングのLitmus Chaosを紹介
2021年7月1日 7:29
NetAppがクラウドネイティブなワークロードにも対応したハイパーコンバージドインフラの新製品を紹介
2019年3月22日 6:00
KubeCon Seattleと併催のOpenShift Commons Gatheringレポート
2019年1月22日 6:00
Kubernetesをサービスメッシュ化するIstioとは?
2018年3月6日 6:00
KubeCon EU 2022からバッチシステムをKubernetesで実装するVolcanoを紹介
2022年9月15日 6:00
IBMとRed Hatが推進するレガシーアプリケーションをKubernetesに移行するためのツールKonveyorを紹介
2022年3月25日 14:05
この記事の筆者

筆者の人気記事
SASEのCato Networks、CEOによるセミナーとインタビューを紹介
2020年4月16日 6:00
Rustのエコシステムの拡がりを感じるデスクトップアプリのためのツールキットTauriを紹介
2022年12月16日 6:00
Zabbix式オープンソースの秘密に迫る
1月31日 6:00
WebAssemblyとRustが作るサーバーレスの未来
2020年4月21日 6:00
エンタープライズLinuxを目指すSUSE、Red Hatとの違いを強調
2015年2月3日 19:00
RustとWASMで開発されKubernetesで実装されたデータストリームシステムFluvioを紹介
2022年12月23日 6:00
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
