「Longhorn」で分散ブロックストレージを簡単に管理する
第11回の今回は、Kubernetes向けの分散ブロックストレージ「Longhorn」の特徴と導入方法、バックアップ・リストアの手順について紹介します。
2025年2月7日 6:30
はじめに
3-shakeの山本直矢(@melanmeg)です。今回は、ブロックストレージの提供が可能な CNCFの「Incubating Projects」である「Longhorn」について紹介します。
Kubernetesのストレージを構築するツールの代表例としては、以下のようなものが挙げられます。
- Rook Ceph
- OpenEBS
- Longhorn
- Cinder
- TopoLVM
- GlusterFS
- Minio
- nfs-subdir-external-provisioner
- local-path-provisioner
私がLonghornを選定した理由として3つあります。①自宅サーバーに導入する際、設定が簡単で管理の負担が少ない分散ストレージを求めていました。また、②既存環境ではMinioを利用したオブジェクトストレージを用意していましたが、新たにブロックストレージも導入しようと考えていました。そして、③Longhornのロゴデザイン(牛)がかっこよくて気に入っているからです。
Kubernetesにおける分散ストレージとは
なぜ分散ストレージか
分散ストレージを利用すると、以下のようなメリットがあります。
- データを複数のノードに分散できるため、オンプレからクラウドに移行がしやすい
- ノードを追加するだけでスケールアウトができる
- 耐障害性が高い
もし、冗長性のないストレージサーバーを運用している場合、以下のような問題が起こる危険があります。
- コンポーネントがダウンすればKubernetes上のサービス全体に影響が出る
- I/Oの負荷分散が行えないため、一台のストレージがボトルネックになると全体のパフォーマンスに影響する
これらの理由から、Kubernetesの運用においてストレージのツール選定が重要になります。
専用ディスクについて
分散ストレージを構築する際、ノードごとに割り当てるストレージ領域は、システムディスク内に割り当てるのではなく、一般的に専用ディスクへ割り当てることが推奨されています。
Longhornのベストプラクティスにも推奨する記載があります(※CephやOpenEBSなどでも専用ディスクを推奨する設計が一般的です)。
専用ディスクを用意すべき理由としては、主に以下のような観点が挙げられます。
- 性能向上
専用ディスクを使用することで、システムディスクとの負荷分離が可能 - 耐障害性
システムディスク故障時のデータ損失リスクが低減。逆にシステムディスク内に用意した場合には、予期せぬ圧迫による故障が考えられる - 容量の確保
システムディスクはOSやログファイル用に利用されるため、専用ディスクを用意することでストレージの競合を避けられる
Longhornについて
LonghornはKubernetes向けの軽量で信頼性が高く、使いやすい分散ブロックストレージシステムです。特にシンプルさを売りにしています。
Longhornの特徴
Longhornには、以下のような特徴があります。
- 複数ノード・データセンターを跨いだ構築が可能
- 任意のノードが故障しても他のノードから復旧が可能
- ボリューム・システムバックアップは、S3などのオブジェクトストアまたはNFS サーバーに保存可能
※オブジェクト ストアは、一般的に信頼性が向上するため推奨される - 既存クラスタが壊れた場合、新しいクラスタでバックアップターゲットを同じNFSに設定すれば、ボリュームとシステムバックアップが検出され、復元が可能
- ボリュームを利用したままでLonghornのアップグレードが可能
- 定期的なスナップショットが可能
- 任意のノードが壊れた場合でも運用可能
- UI付属
Longhornにおけるボリュームとは、Kubernetesにおけるpersistent volumes(PV)とpersistent volume claims(PVC)に対応します。
システムバックアップの対象リソースには、以下が含まれます。
- BackingImages
- ClusterRoles
- ClusterRoleBindings
- ConfigMaps
- CustomResourceDefinitions
- DaemonSets
- Deployments
- EngineImages
- PersistentVolumes
- PersistentVolumeClaims
- RecurringJobs
- Roles
- RoleBindings
- Settings
- Services
- ServiceAccounts
- StorageClasses
- Volumes
Longhornで管理されるリソースのほとんどをバックアップしますが、ボリュームのスナップショットはローカルのLonghornクラスタ内に保存されているため、バックアップされません。
その他ツールとの比較
以下の3つのツールを中心に、ツールの比較調査をしてみました。
- Rook Ceph
- Longhorn
- OpenEBS
Longhornを採用する一番の理由は、導入と管理のシンプルさにあると思います。対してデメリットを挙げると、ストレージタイプの対応がブロックストレージのみであることです。
【特徴比較の参考文献】
- Compare RookCeph Vs Longhorn vs OpenEBS
- Kubernetes Storage Capabilities & Performance Analysis: Longhorn, Rook, OpenEBS, Portworx, and IOMesh Compared
パフォーマンス面においては、下記2つの文献によるとRook Ceph、Longhorn、OpenEBSの順でパフォーマンスが高く、Longhornは十分な性能を持つようです。
【パフォーマンス比較の参考文献
- Kubernetesのストレージ: OpenEBS vs Rook (Ceph) vs Rancher Longhorn vs StorageOS vs Robin vs Portworx vs Linstor
- Performance Benchmarking Cloud Native Storage Solutions for Kubernetes
基本的な使い方
まず、HelmでLonghornをインストールします(※ドキュメントにはArgoCDでインストールする手順も用意されています)。今回用意したvalues.yamlはこちらです。/mnt/longhorn-xfs/がデータディスクになります。
backupTarget: nfs://192.168.11.12:/mnt/nfsshare/k8s/share
# When this setting is disabled, Longhorn creates a default disk on each node that is added to the cluster.
createDefaultDiskLabeledNodes: false
defaultDataPath: /mnt/longhorn-xfs/
replicaSoftAntiAffinity: true
storageOverProvisioningPercentage: 1000
storageMinimalAvailablePercentage: 5
upgradeChecker: true
# Set the default replica count to “2” to achieve data availability with better disk space usage or less impact to system performance.
defaultReplicaCount: 2
defaultDataLocality: disabled
priorityClass: high-priority
autoSalvage: true
disableSchedulingOnCordonedNode: false
replicaZoneSoftAntiAffinity: true
replicaDiskSoftAntiAffinity: true
# ref: https://longhorn.github.io/longhorn-tests/manual/pre-release/node/improve-node-failure-handling/
nodeDownPodDeletionPolicy: do-nothing
guaranteedInstanceManagerCpu: 20
orphanAutoDeletion: true特に私が気になった設定値は、以下の3つです。
- createDefaultDiskLabeledNodes
trueにすると“node.longhorn.io/create-default-disk=true”というラベルを持つノードにのみデフォルトディスクを自動的に作成するようにする設定。
初期導入時には、値をfalseにしないとディスクが作成されないため注意 - defaultReplicaCount
「2」に設定することでディスク領域の使用率を向上させ、システムパフォーマンスへの影響を抑えながらデータの可用性を実現できる
https://longhorn.io/docs/1.7.2/best-practices/#volume-performance-optimization:~:text=the root disk.-,Replica count,-%3A Set the default - nodeDownPodDeletionPolicy
この設定値を変更すると、ダウンしたノード上のStatefulSet/Deploymentの終了ポッドを自動的に強制削除することでノード障害処理の改善が可能になる
https://longhorn.github.io/longhorn-tests/manual/pre-release/node/improve-node-failure-handling/
※UIへのアクセスはlonghorn-ui Podにkubectl port-forwardやServiceを作成してアクセスすることで確認できます。ボリューム管理するために必要なストレージクラスmy-longhorn-scをLonghornに設定した例は以下のとおりです。
kind: StorageClass
metadata:
name: my-longhorn-sc
provisioner: driver.longhorn.io
allowVolumeExpansion: true
reclaimPolicy: Delete
volumeBindingMode: Immediate
parameters:
numberOfReplicas: "3"
replicaAutoBalance: "best-effort" # Replica Auto Balance
staleReplicaTimeout: "1440" # 24 hours in minutes
fromBackup: ""
fsType: ext4
$ kubectl get sc my-longhorn-sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
my-longhorn-sc driver.longhorn.io Delete Immediate trueストレージタグについて
各ノード、ディスクにタグを付けることで、ボリュームに使用可能なノード、ディスクを制限できるようになります。以下に設定方法を示します。
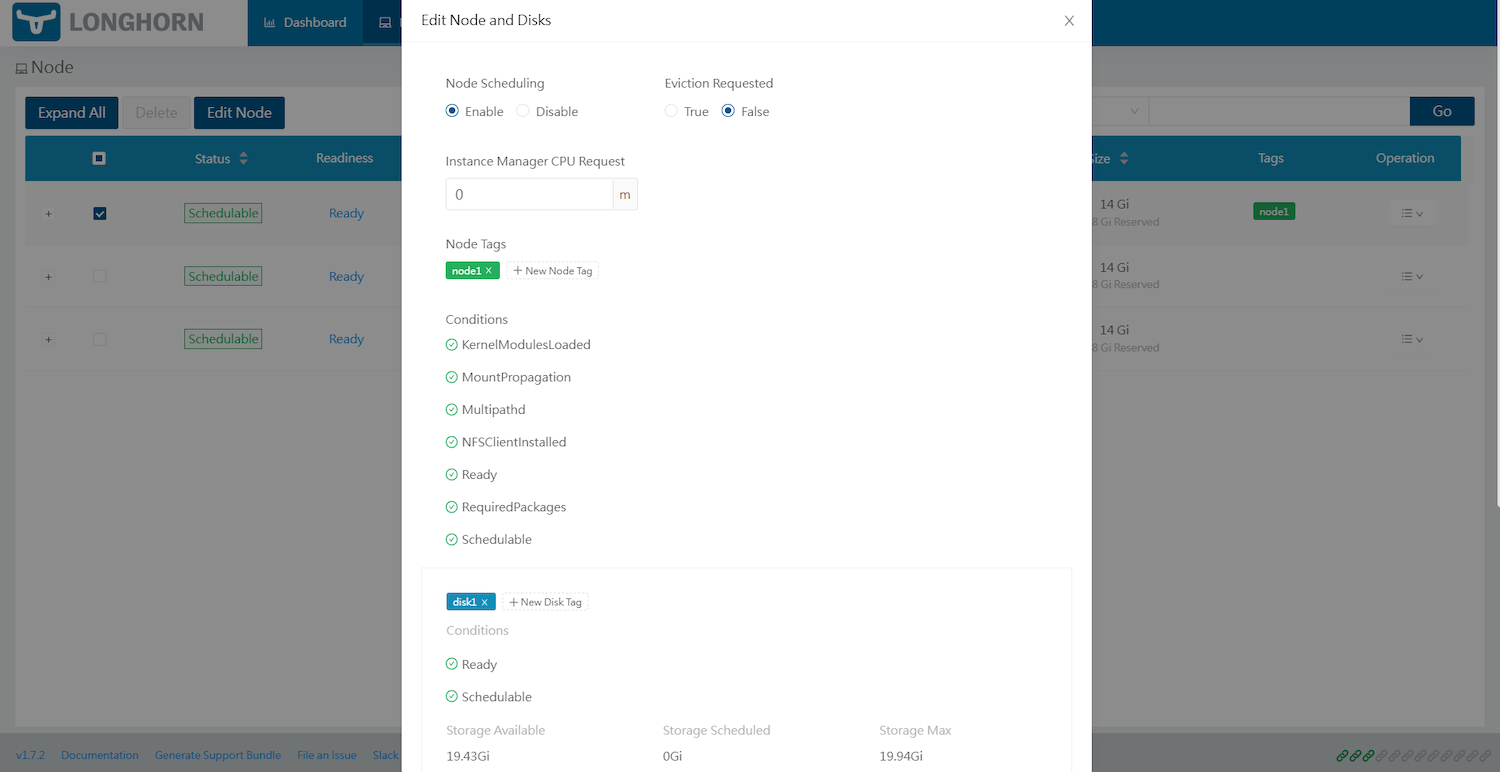
- ブラウザのVolumeタブから対象ノード(今回はtest-k8s-wk-1とする)の「Edit Node and Disks」画面を開きます。
- [+ New Node Tag]をnode1に、[+ New Disk Tag]をdisk1に設定します。
- ストレージクラスにdiskSelector、nodeSelectorを加えます。
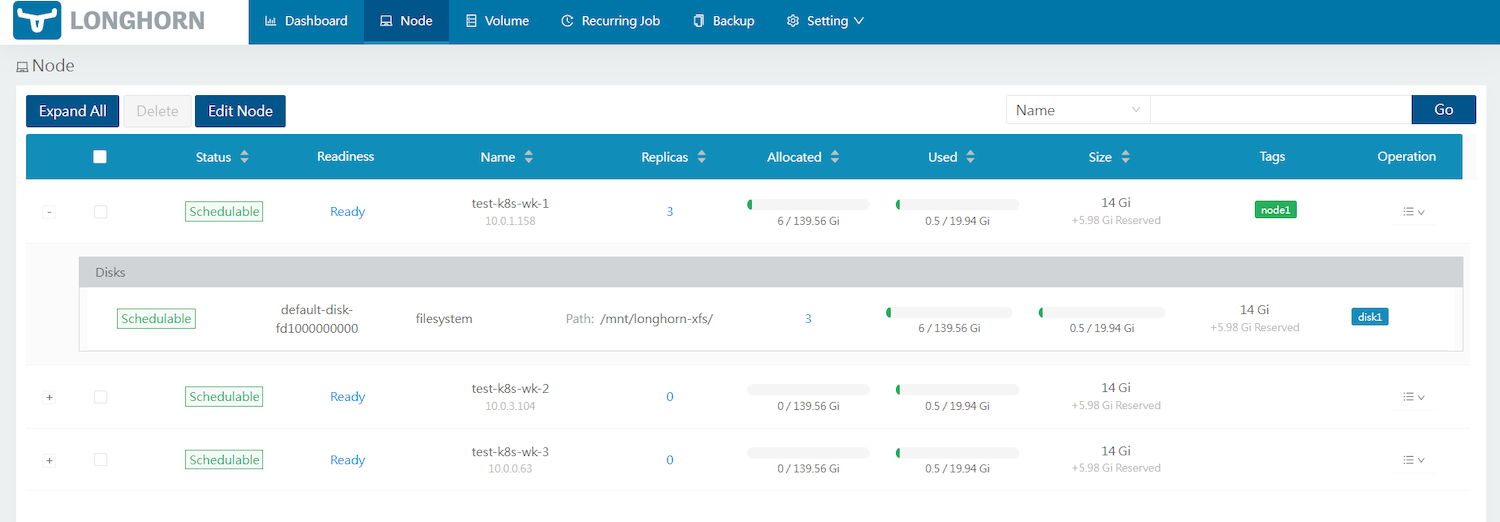
kind: StorageClass metadata: name: my-longhorn-sc provisioner: driver.longhorn.io allowVolumeExpansion: true reclaimPolicy: Delete volumeBindingMode: Immediate parameters: numberOfReplicas: "3" replicaAutoBalance: "best-effort" # Replica Auto Balance staleReplicaTimeout: "1440" # 24 hours in minutes fromBackup: "" fsType: ext4 diskSelector: "disk1" nodeSelector: "node1" --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: my-longhorn-pvc spec: accessModes: - ReadWriteOnce storageClassName: my-longhorn-sc resources: requests: storage: 2Gi - 対象ノード「test-k8s-wk-1」のみが使用されていることが分かります。
このように、特定のノード、ディスクのみにボリュームを割り当てたい場合、例えば「このボリュームにはSSDの高速なディスクを割り当てたい」といったときに役立てることができます。
この機能の注意点として、設定方法がUIから設定する方法しかないことです。HelmやManifestから自動設定する方法はないため、使用可能なノード、ディスクの制御が必要となる場合は選定時の懸念となる場合がありそうです。
バックアップ・リストアを試してみる
Longhornにおけるバックアップの種類として、ボリュームバックアップ、ボリュームのスナップショット、システムバックアップの3つがあります。今回は、これらについて紹介します。
- ボリュームバックアップ
KubernetesにおけるPV、PVCのバックアップ - ボリュームのスナップショット
KubernetesにおけるPV、PVCのスナップショット - システムバックアップ
全体のバックアップ
バックアップターゲットの設定
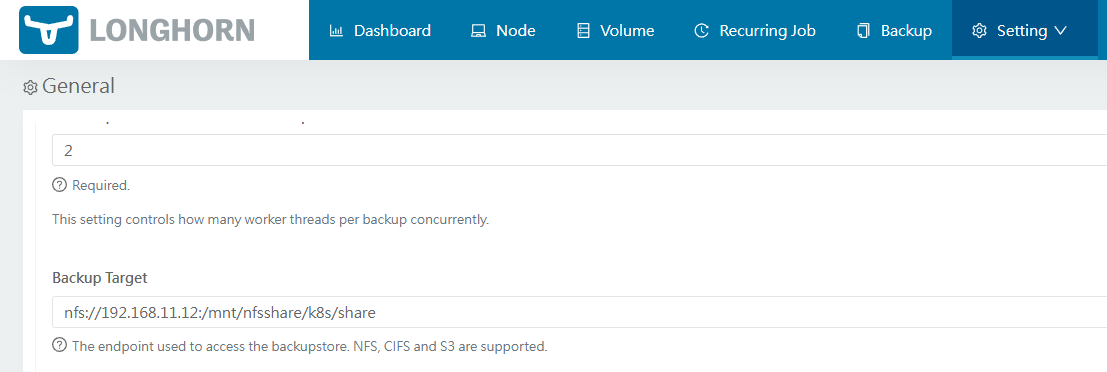
バックアップ用にNFSサーバー(IP:192.168.11.12)が用意されていることを前提とします。values.yamlのdefaultSettings.backupTargetでターゲット設定をしています。
ブラウザの設定画面から、ターゲットが設定されていることを確認できます。
ボリュームのバックアップ・リストア
先ほどテスト用で作成したストレージクラスmy-longhorn-scを利用して、サンプルのMySQLをデプロイします。
kind: StatefulSet
metadata:
name: mysql
spec:
serviceName: "mysql"
replicas: 2
selector:
matchLabels:
app: mysql
template:
metadata:
labels:
app: mysql
spec:
containers:
- name: mysql
image: mysql:8.0
ports:
- containerPort: 3306
env:
- name: MYSQL_ROOT_PASSWORD
value: "rootpassword"
volumeMounts:
- name: mysql-data
mountPath: /var/lib/mysql
volumeClaimTemplates:
- metadata:
name: mysql-data
spec:
accessModes:
- ReadWriteOnce
storageClassName: my-longhorn-sc
resources:
requests:
storage: 1GiVolumeタブから正常にVolumeがマウントされていることを確認できます(※レプリカ数だけのボリューム管理ができます)。
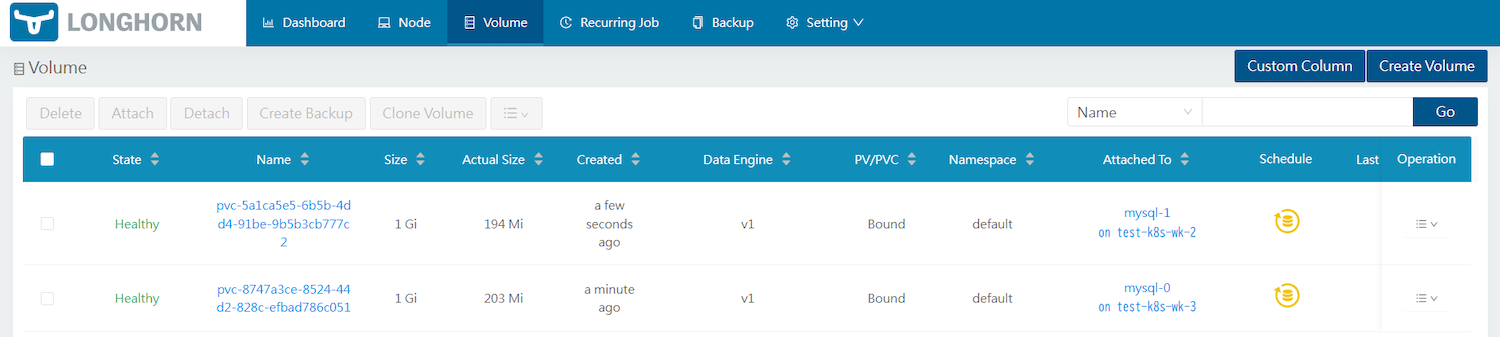
まず、mysql-1のボリュームのバックアップ・リストアを試してみましょう。
- ボリュームを選択して[Create Backup]をクリックします。Backupタブを開くとmysql-1のボリュームのバックアップが作成されています。

- Volumeタブに戻り、mysql-1のボリュームを削除しておきます。再度Backupタブでバックアップしたmysql-1のボリュームをリストアしてみます。
- バックアップしたmysql-1のボリュームを選択して[Restore Latest Backup]からリストアすると、Volumeタブでリストアされていることを確認できました(ここではrestore-mysql-1-pvcという名前でリストアした)。
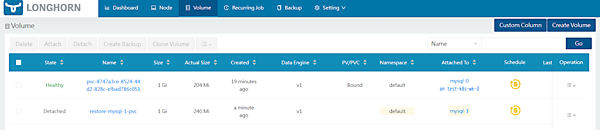
- この状態ではまだボリュームがアタッチされていないため、restore-mysql-1-pvcボリュームを選択して[Attach]をすることでStateはHealthyとなります。

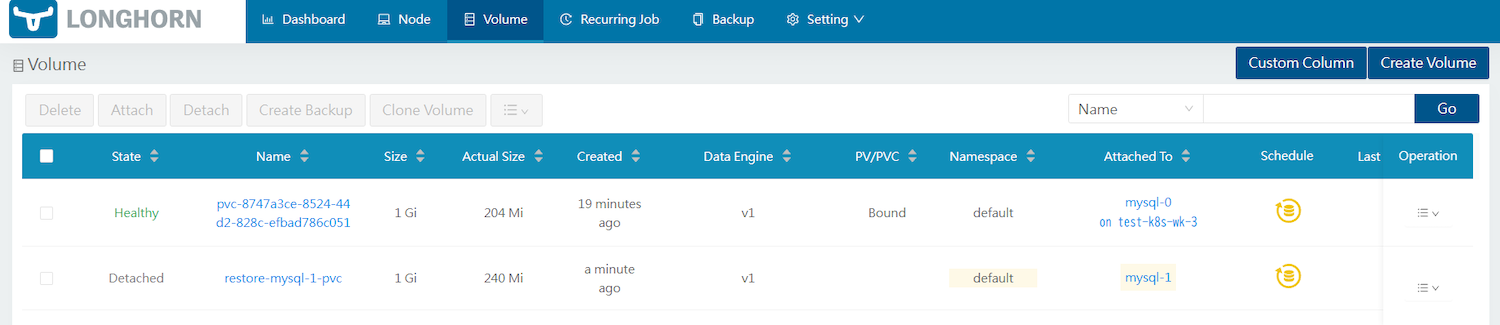
ボリュームのスナップショットを作成
ボリュームのバックアップとの違いは、特定の時点におけるKubernetesボリュームの状態を保存していることです。そのため、バックアップに比べてスナップショット作成・復元は高速です。
現在のボリュームの状態は以下のようになっています。
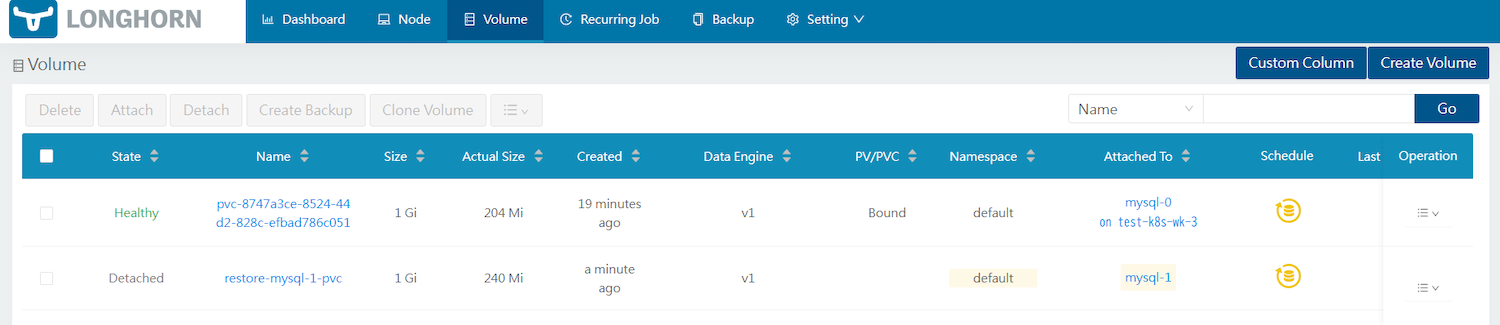
mysql-0ボリュームにある“Name”のリンク先で[Take Snapshot]をクリックすると、スナップショットが作成されます。
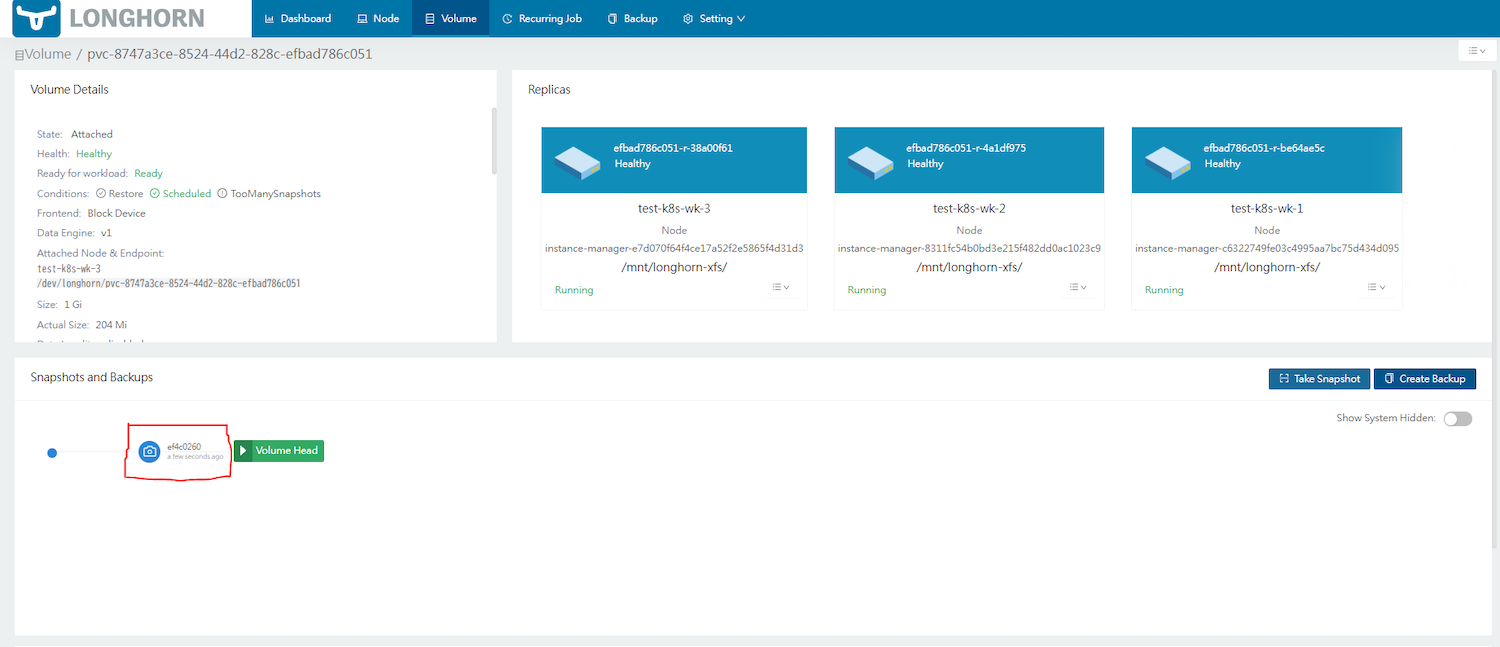
※もしRevertしたい場合は、一度ボリュームをデタッチしてから、メンテナンスモードでアタッチする必要があります。
システムのバックアップ・リストア
まず、システム全体のバックアップを実施します。現在のボリュームの状況は以下のようになっています。
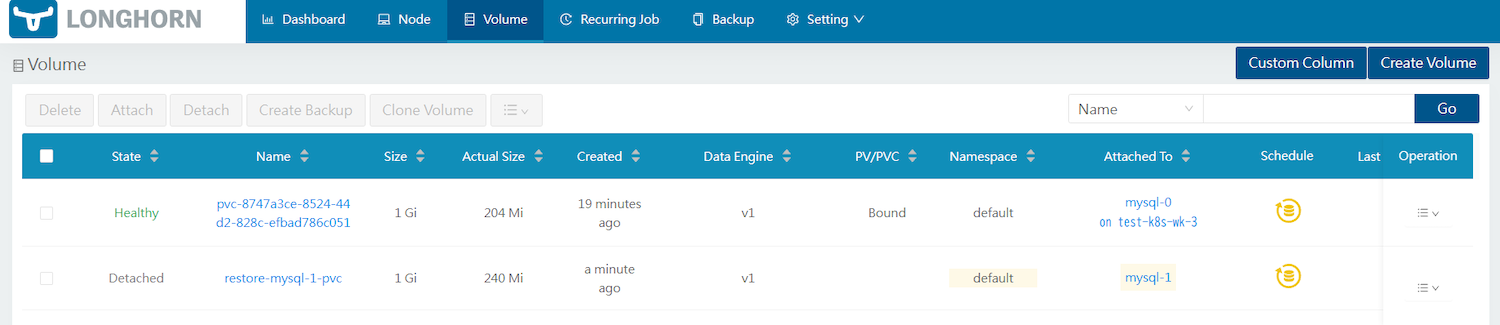
バックアップをするには、上部のSettingsタブから[System Backup]を選択します。左上にある[Create]をクリック後、ポップアップに適宜入力するとシステムバックアップが開始されます(ここではバックアップ名をtest-system-backupとした)。StateがReadyとなれば成功です。

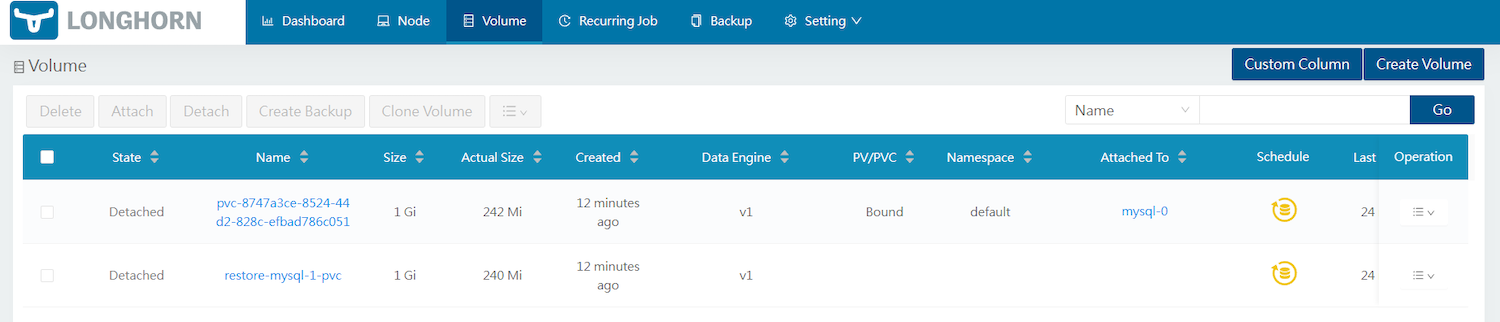
試しに、今あるボリュームをすべて(mysql-0のボリューム、mysql-1のボリューム)を削除します。その後、System Backup画面に戻り、先ほどバックアップしたtest-system-backupの[Operation]から[Restore]を実行してシステムバックアップを復元し、StateがCompletedとなれば成功です。

削除したすべてのボリュームが復元されていることも確認できました。
ノード障害テストをしてみる
まず、先に利用していたMySQLのStatefulsetのspec.replicasを1にしてデプロイしておきます。現在の状態は、mysql-0のボリュームが1台目のワーカーノード「test-k8s-wk-2」に紐づいています。

ボリュームを選択してレプリカの詳細を見ると、3台のワーカーノードに分散されていることが分かります。
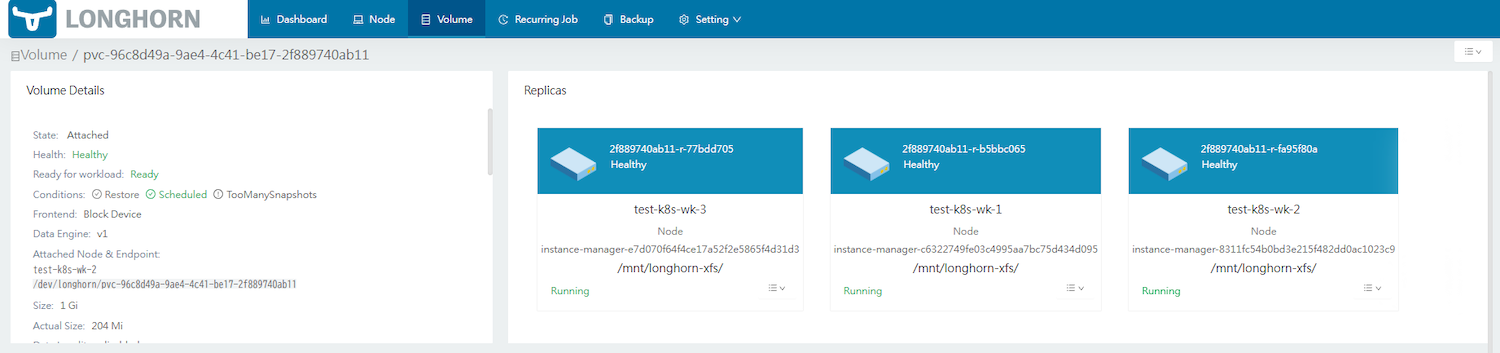
この状態でmysqlがアタッチされていない3台目のワーカーノード「test-k8s-wk-3」を停止してみます。
※StatefulSetでは、特定のPVCと密接に結びついているためPodが割り当てられたノードが停止された場合、デフォルトでは別のノードで自動的に立ち上がりません。
再度ボリュームを確認すると、3台目のワーカーノード「test-k8s-wk-3」のレプリカがstoppedとなり、一時的にボリュームがHealth: degradedとなります。
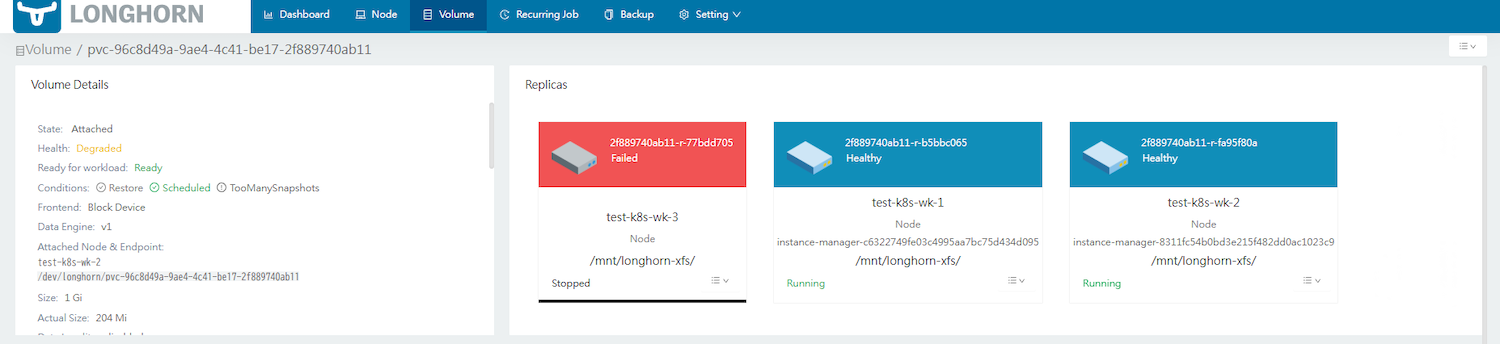
また、Longhornでは数十分待つとレプリカが3台目のワーカーノード以外(test-k8s-wk-1)にレプリカが立ち上がり、ボリュームがHealth: Healthyに保つように動作するようです。
※3台目のワーカーノード「test-k8s-wk-3」に割り当てられていたPVCは、ストレージクラス設定のparameters.staleReplicaTimeoutの値により時間経過でクリーンアップされます。
【参考】
・The orphaned data cleanup mechanism does not clean up a stale replica, also known as an error replica. Instead, the stale replica is cleaned up according to the staleReplicaTimeout setting.

3台目のワーカーノード「test-k8s-wk-3」を起動してみます。
数分待ってボリュームを確認すると、レプリカはリバランスされて3台のワーカーノードに分散配置されるように戻ることを確認できました。このとき、1台目のワーカーノード「test-k8s-wk-1」に2つあったレプリカのうち1つは削除されます。
※ストレージクラスのparameters.replicaAutoBalanceで、ボリューム分散を維持させる設定があります。best-effortに設定すると、ベストエフォートに従って冗長性を均等にするために自動でレプリカが再調整されます。

今後期待される機能
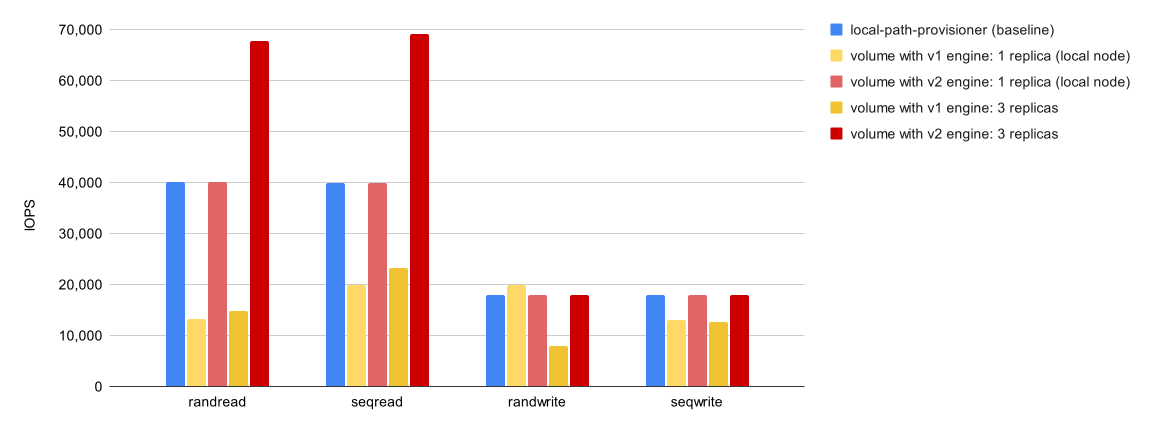
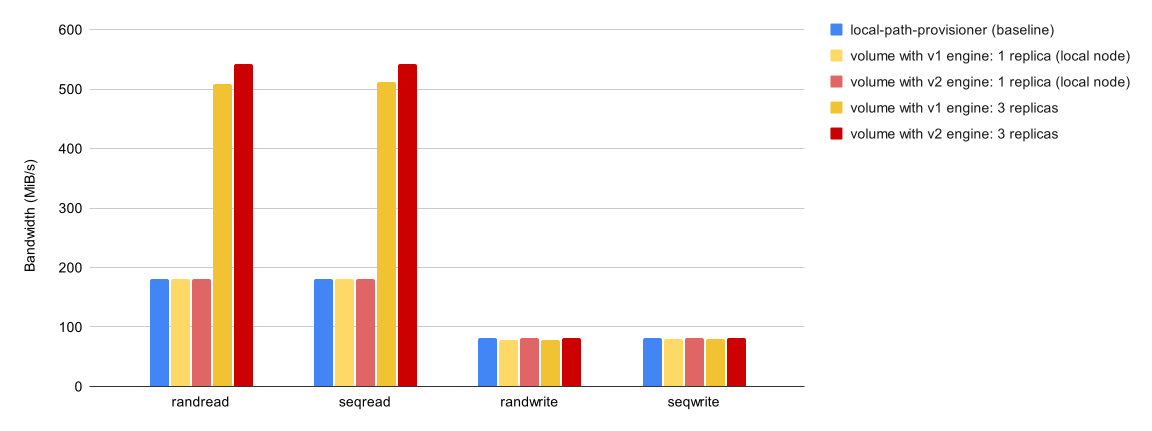
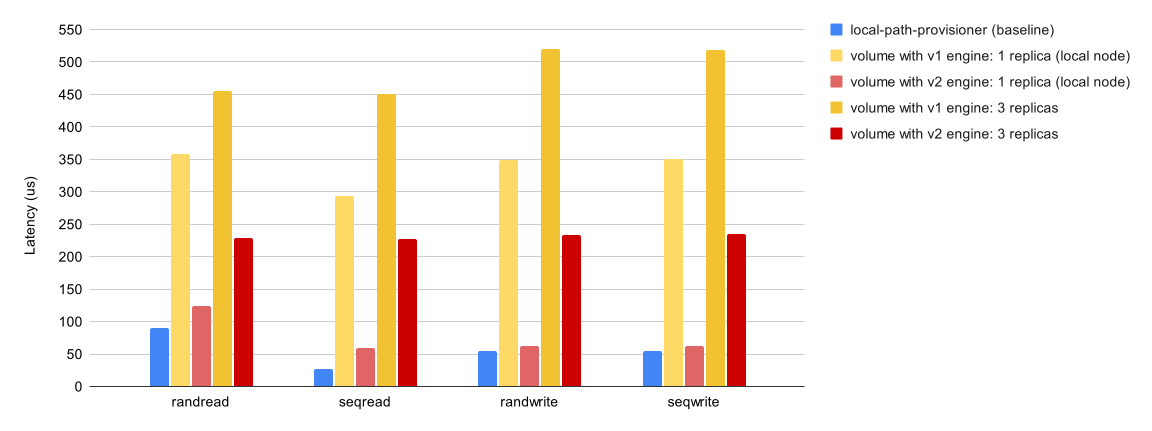
現在はプレビュー機能である「V2データエンジン」機能があります。実稼働環境での使用は推奨されていませんが、V2データエンジンを利用することでパフォーマンスが向上します。ストレージパフォーマンス開発キット(SPDK)を活用して全体的なパフォーマンスを向上させています。
IOPSの計測では特に読み込み性能が高くなることが見込まれ、レイテンシの計測に関してはV1データエンジンよりも全体的に大幅の性能向上が見込まれています。
【引用】Performance
- IOPSを比較計測した結果
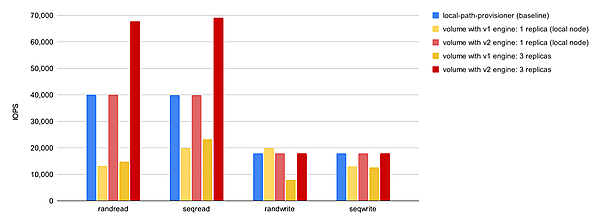
- Bandwidth(MiB/s)

- Latency(us)を比較計測した結果
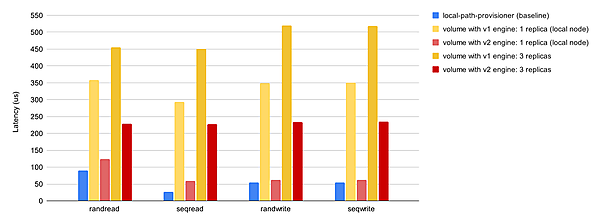
おわりに
Longhornの調査・構築をして感じたことは、導入がシンプルなことです。Rook CephやOpenEBSを構築した経験はありませんが、おおよそ手順はシンプルだったのではないでしょうか。また、ドキュメントが丁寧でよくまとまっていることは素晴らしく感じました。
ただし、Rook Cephと比較すると、コミュニティの活発度や参考文献の検索ヒット数に関しては、やや物足りない印象はありました。しかし、シンプルさを求めている場面では有力候補になると考えます。今後は、LonghornのアーキテクチャやV2エンジンについても少し気になっています。
ご一読いただき、ありがとうございました。
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
