情報爆発時代に必要なインフラは?
情報爆発時代に必要なインフラは?
OracleやDB2を代表とするリレーショナル・データベース管理システム(RDBMS)は、現代のさまざまな情報サービスを支える基幹システムとして活用されています。多様なデータを扱うための手段をSQL言語として標準化し、さまざまな複雑なデータ処理をブラック・ボックス化して簡単に利用できるようにしている点において、RDBMSはまさに現代の情報サービスのためのインフラと呼んで差し支えないでしょう。
ところで、全世界を流通している情報量は、5年につき10倍のペースで増大していると言われています。米IDCのレポートでは、2007年にはデジタル化されたデータ量は280エクサバイト、つまり2800億ギガバイトにも達していると推計しています。
近年は、ブログやTwitterなど、一般の利用者によって作られるCGM(Consumer Generated Media)と呼ばれるコンテンツ情報が著しく増大しています。さらに、日夜休みなくデータを生み出し続けるCCD(電荷結合素子)カメラやGPS(衛星利用測位システム)などのセンサーが爆発的に普及しつつあり、センサーから収集されるデータ量は爆発的に増え続けています。私たちは、まさに情報爆発の時代に生きているといえます。
爆発的に増大しつづけるデータを活用して価値のある情報を発見することが、厳しい市場競争を勝ち抜くための必須条件になったことは、広く認識されつつあります。現在では、1ペタバイト(約100万ギガバイト)を超える規模のデータを蓄積している企業も珍しくありません。
しかしながら、従来の情報システムの主要部分を占めていたRDBMSは、ペタバイト規模のデータを想定しているわけではありません。ペタバイト規模のデータを活用するためには、RDBMSとは根本的に異なる発想が必要とされます。
情報爆発時代に必要とされるインフラは、以下の要件を備えていなければなりません。
- スケール・アウトが可能であること
- データの規模が大きくなるたびにシステムを高性能のものにリプレースするスケール・アップの考え方は、情報爆発の状況ではコスト面ですぐに限界に達してしまいます。コンピュータの台数を増やすことで性能を段階的に増強できるスケール・アウトの考え方に基づいている必要があります。
- ハードウエア障害が発生しても動き続けること
- コンピュータの台数が増えると、必然的にシステムのどこかでハードウエア障害が発生する確率が大きくなります。ハードウエア障害が発生してもデータが失われることなく処理を続行することができる仕組みが必要とされます。
- データ入出力のスループットを大きくできること
- 日々生み出され続ける膨大なデータを受け入れ、それをフル活用できるだけの処理能力が要求されます。
Hadoopは、これらの要件を満たすことを目標として開発されているソフトウエアです。Hadoopは、多数の安価なPCを束ねて1つの巨大なバッチ処理クラスタを構成する機能を備えています。
- ハードウエア障害が起きても動き続けるための複雑な仕組みを備えています
- Hadoopの構成を図2に示します。Hadoopは、HDFSと呼ばれる専用の分散ファイル・システムを持っていて、クラスタを構成する一部のPCが故障してもデータが失われない状態が維持されるようになっています。バッチ処理はMapReduceというフレームワークにより小さなタスクに分割されて並列実行される仕組みになっており、バッチ処理の実行途中に故障が発生しても動き続けるようになっています。また、クラスタ全体の処理性能が台数にできるだけ比例する(スケール・アウトする)ための工夫がなされています。
|
|
| 図2: Hadoopの構成(クリックで拡大) |
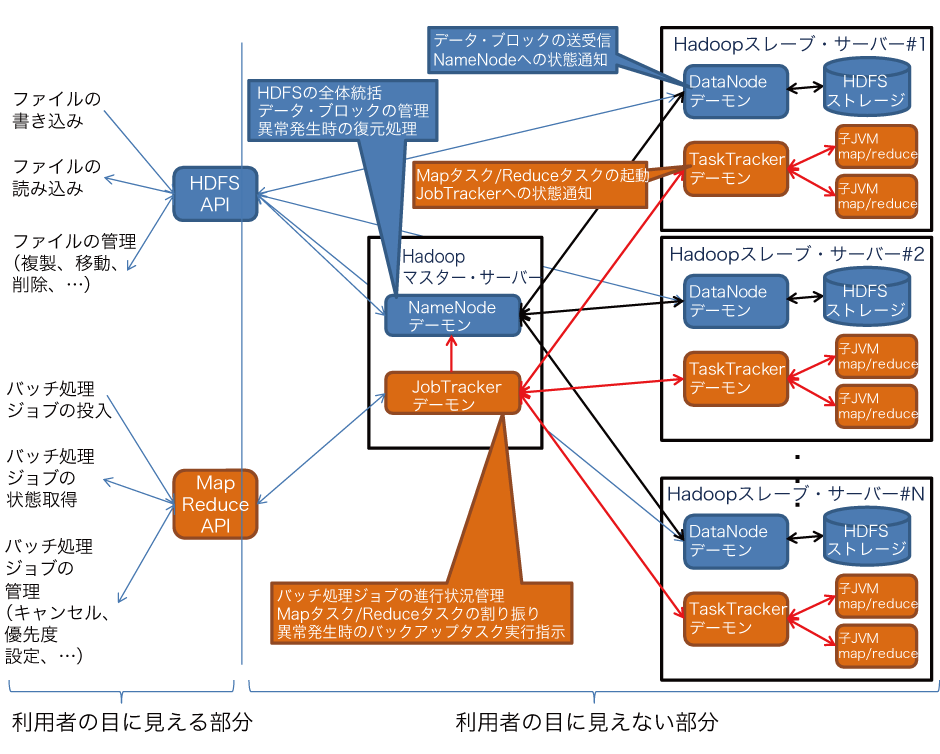
- Hadoopは、Apacheプロジェクトのオープンソース・ソフトウエアとして開発されています
- 上に述べた複雑な仕組みを実装するためには多数の開発者の参加が不可欠ですが、Hadoopプロジェクトには米Yahoo!や米Facebookなど、大規模なHadoopクラスタを運用している企業の開発者が多数参加することで、開発コミュニティが維持されています。見方を変えると、一企業単独では実現が難しい複雑なシステムの実装コストを、オープンソース・モデルを活用して他社と分担していると見ることができます。
- ファイル・システムを利用したり、ジョブを実行したりするための各種APIが整備されています
- APIは、Hadoopの中の複雑な仕組みを利用者の目から隠ぺいし、ブラック・ボックス化する役割を果たしています。APIを利用することで、複雑な仕組みを意識することなく、耐障害性やスケール・アウトなどのHadoopの御利益を享受することができます。
このように、Hadoopは「複雑な仕組みを持っている」「莫大(ばくだい)な維持コストを分担する仕組みがある」「ブラック・ボックス化されている」というインフラの性質を備えています。情報爆発時代の新たなインフラとなる可能性を秘めているといえるでしょう。
- この記事のキーワード
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
