分散型データストアApache Kuduの特徴とユースケース
2019年3月29日 6:30
はじめに
ネットワークに接続されたデバイスの普及により、さまざまな機器が大量のデータを生成するIoT(Internet of Things)が進展しています。また、AI・機械学習技術の発展により、この大量のデータを活用したデータ分析が注目を集めています。
このような背景から、情報システムが収集・蓄積すべきデータ量は急激に増加しており、かつ蓄積した大量のデータを効率よく分析することが求められています。Apache Kudu(以降、Kudu)はこのようなビッグデータの蓄積と分析に使用するデータストアとして注目を集めています。
Kuduとは
Kuduは高いスケーラビリティを持つ分散型のデータストアであり、多数のマシンでクラスタを構成することで大量のデータを扱うことができます。KuduはCloudera社によって開発され、2015年にOSSとして公開されました。
Kuduはクラスタを構成するマシンの台数を増やせば増やすほど、容量と性能がスケールアウトします。Cloudera社によると設計上は最大で1,000ノード超、数十PBまでスケールでき、秒間数百万のリード/ライトが可能になるそうです(参考:Apache Kuduを使った分析システムの裏側)。また、Kuduは高い可用性を持ち、一部のマシンに障害が発生してもデータを失うことなく稼働し続けることができます。
ビッグデータ関連データストアにおけるKuduの位置づけ
ビッグデータの格納に使用される主要なデータストアの位置づけを図1に示します。
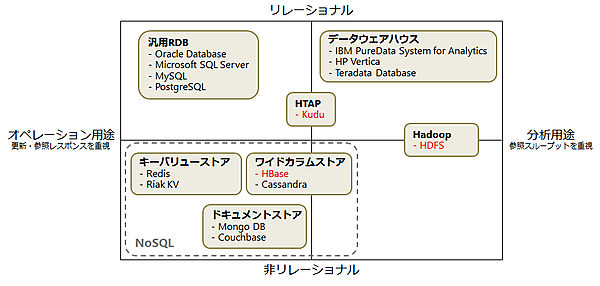
一般的に、高頻度の格納・参照が必要なオペレーション用途では、汎用RDBやNoSQLが適しています。大量データの参照が必要な分析用途では、データウェアハウスやHadoop(で使用する分散ファイルシステムのHDFS)が適しています。Kuduは表形式のデータを扱い、高頻度の格納・参照と大量データの参照の両方の処理に優れているHTAP(Hybrid Transactional/Analytic Processing)という分野のデータストアです。
ビッグデータ処理の分野ではHadoopを中心としたOSSがデファクトスタンダードとなっており、KuduもHadoopエコシステム(Hadoopと組み合わせて使用することが多いOSSを指す)に適合するように設計されたデータストアです。そのため、Hadoopで使用されるHDFSやHBaseとどう使い分けるかが重要となります。
HDFS / HBase / Kudu の比較
Hadoop向けのデータストアである、HDFS、HBase、Kuduの比較を以下に示します。
機能面の比較
まずは機能面の比較を表1に示します。
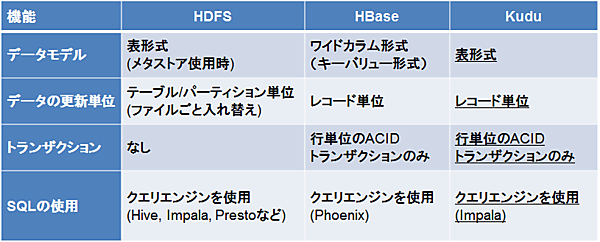
データモデル
HDFS自体はただの分散ファイルシステムですが、スキーマを管理するHiveメタストアを導入することで、HDFS上のCSVファイルなどを表形式で扱うことができます。また、列指向のファイルフォーマットであるParquetやORCを導入することで、DWHのように大量のデータを高速に参照することが可能です。HBaseのワイドカラム形式は一見すると表形式のようにも見えますが、実際はキーとバリューで構成されるキーバリューストアです。Kuduのデータモデルは表形式であり、HDFSにHiveメタストアを導入した場合と似ています。
データの更新単位
HDFSはファイルシステムなので、データを更新するときはHDFSのディレクトリ内のファイルをまるごと入れ替える必要があります。Hiveのトランザクショナルテーブル機能を有効にすれば、レコード単位の追加・更新・削除も可能となりますが、いくつかの制限があるため現状ではあまり使用されていません。一方HBaseとKuduはレコード1行ごとの更新や削除が可能です。
トランザクション
トランザクション機能については、どのデータストアも貧弱です。HDFSはそもそもトランザクションがなく、Hiveのトランザクショナルテーブル機能でも、複数の操作にまたがるトランザクション(BEGIN、COMMIT、ROLLBACK)はまだ提供していません。HBaseとKuduも現状では1レコード内のトランザクションしかサポートしておらず、テーブル間の関係を強制することもできません。
データの整合性を担保したい場合はアプリケーション側で対処する必要がありますが、MySQLやPostgreSQLなどのRDBと同等のデータ整合性を確保することは非常に困難です。そのため、これらのデータストアは複雑なトランザクション処理が必要となる基幹系システム(金融機関における入出金処理など)におけるRDBの置き換えには適していません。どちらかというと、トランザクション処理があまり必要ないデータ分析用の情報系システムに適しています。
SQLの利用
HDFSやHBase、Kuduはデータの格納と参照のみを担当します。つまり、MySQLのようにSQLでデータを集計したり変換したりする機能はありません。そのため、これらのデータストアを使用する際は、データの集計や変換を行うためのクエリエンジンや並列分散処理フレームワークを組み合わせて使用するのが一般的です。
HDFSではHiveやImpala、Prestoなどのクエリエンジンを組み合わせることでSQLを利用できます。HBaseのデータモデルは表形式ではありませんが、クエリエンジン機能を持つPhoenixというOSSを組み合わせることでSQLを利用できます。
KuduでのSQLの利用にはImpalaを使用するのが一般的です。ImpalaはHadoop向けのクエリエンジンであり、Kuduと同じくCloudera社によって開発され、2012年にOSSとして公開されました。Impalaを使用することで、SQLによるデータアクセスが可能となるほか、BIツールなどからJDBCやODBC経由でKuduのデータにアクセスできるようになります。また、KuduのデータとHDFS(Impalaテーブル)のデータを透過的に結合することも可能です。
性能面の比較
HDFS、HBase、Kuduの最大の違いは、得意とするワークロードです。性能面の比較を表2に示します。
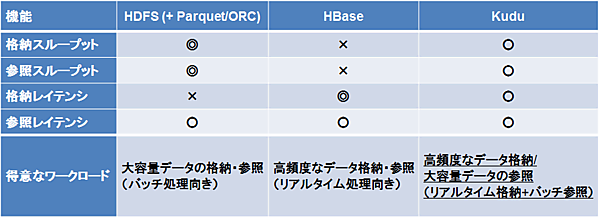
HDFSは大量のデータをファイル単位でまとめて格納および参照することで、高いスループットを発揮します。そのため、あらかじめ蓄積された大量のデータを、まとめてバッチ処理するのに向いています。また、HDFSでは列指向ファイルフォーマット(ParquetやORC)の使用により、ディスクI/O量の削減によるスループット向上だけでなく、検索の高速化による低レイテンシのレコード参照も可能となります。
HBaseは小さなデータを高頻度で読み書きするのが得意です。そのため、ストリームデータ処理で流れてくるデータをリアルタイムに格納したり、レコード単位の細かい参照を大量に行うような処理に向いています。そのため従来のHadoopシステムでは、リアルタイムなデータの書き込みにHBaseを使用し、HBaseに蓄積したデータを定期的にHDFSに移動してバッチ処理やデータ分析に使用するケースが一般的でした。
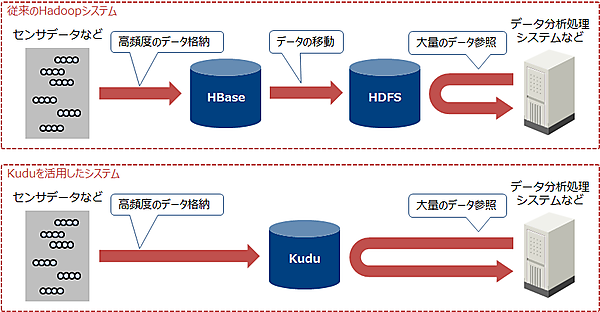
一方、Kuduは高頻度なデータ格納と大量データの参照に適しています。つまりKuduは性能面において、HBaseに近い格納レイテンシ性能と、HDFSに近い参照スループット性能を持ちます。Kuduを使用することで、ストリームデータをリアルタイムに格納しつつ、蓄積した大量のデータを分析用にまとめて参照する、といったシステムを1つのデータストアで構築することが可能となります。(図2)。
Kuduの導入事例
Kuduの主な導入事例を以下に示します。
Comcast(アメリカ)
Comcastはアメリカのケーブルテレビ会社で、テレビ視聴データのリアルタイム分析およびバッチ分析にKuduを使用しています(参考:Real-time analytics using Kudu at petabyte scale)。Comcastでは410ノードのKuduクラスタに3年分のアーカイブデータとして6,000億レコード(1レコードあたり平均2KB)を蓄積しており、さらに毎日5億レコードを格納しているそうです。
Comcastのデータ分析システムでは、リアルタイムに発生したデータをまずメッセージキューであるKafkaでキューイングして、それをストリームデータ処理フレームワークであるSpark Streamingで処理してからKuduに格納しています。Kuduに格納したデータはMapReduceでバッチ処理したり、分析のためBIツールからImpala経由で参照しています。
Xiaomi(中国)
Xiaomiは中国のスマートフォンメーカーであり、モバイルアプリとバックエンドサービスから取得したデータをKuduに格納して、サービスのモニタリングやトラブルシューティングに利用しています(参考:Spark Summit EU talk by Mike Percy)。
Xiaomiでは元々、HBaseとHDFSを組み合わせたデータ分析パイプラインを構築していました。このパイプラインでは、データを一旦HBase(リアルタイムな書き込みが得意)に格納しておき、HBaseに蓄積したデータを定期的なバッチ処理でHDFS(大量データの参照が得意)にコピーして、分析に使用していました。しかし、このパイプラインではデータのコピーが必要なため、リアルタイムなデータ分析ができていませんでした。
そこで、Xiaomiはリアルタイムなデータ分析を行うために、リアルタイムな書き込みと大量データの参照が可能なKuduを導入しました。このパイプラインでは、リアルタイムに発生したデータを直接Kuduに格納するか、Kafkaでキューイング後にストリームデータ処理フレームワークであるStormで処理してからKuduに格納しています。Kuduクラスタには毎日200億以上のレコードがリアルタイムに格納され、格納したデータは分析のためImpalaなどを用いて参照されます。
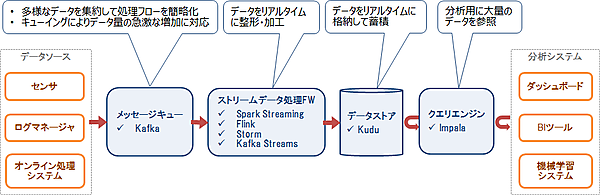
Kuduの典型的なシステム構成
上記の導入事例はいずれも、リアルタイムに発生するデータを蓄積して分析するシステムです。Kuduはこのようなシステムにおいてデータをリアルタイムに格納し、データ分析用にまとめて参照する用途に使用されています。
このようなシステムは他のOSSと組み合わせて構築されることが多く、特にメッセージキューであるKafka、ストリームデータ処理フレームワークであるSpark StreamingやStorm、低レイテンシのクエリエンジンであるImpalaがよく使用されています。図3にKuduの典型的なシステム構成を示します。
おわりに
今回はHadoop向けのデータストアであるKudu、HBase、HDFSの比較と、Kuduに適したユースケースを紹介しました。Kuduは高いスケーラビリティを持つ分散型のデータストアであり、Hadoopエコシステムに適合するように設計されたOSSです。Kuduは表形式のデータを扱い、高頻度のデータ格納と大量データの参照の両方の処理に優れており、主にデータ分析用システムで活用されています。
次回はKuduの具体的なシステム構成と主要な機能、およびKuduが大量のデータを処理する仕組みを紹介します。
- この記事のキーワード
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者
筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
