大量データのバッチ処理を高速化するHadoop
Hadoopというソフトウエアが、いま注目を集めています。米Googleが発表した論文のアイディアをオープンソース・モデルで実装したソフトウエアです。膨大な量のデータを処理する必要に迫られた企業や研究組織が、続々とHadoopを実際に活用しはじめています。私たちの研究グループでは、Wikipedia
2010年6月4日 20:00
Hadoopというソフトウエアが、いま注目を集めています。米Googleが発表した論文のアイディアをオープンソース・モデルで実装したソフトウエアです。膨大な量のデータを処理する必要に迫られた企業や研究組織が、続々とHadoopを実際に活用しはじめています。
私たちの研究グループでは、Wikipediaなどの巨大なテキスト・データを解析するために、2007年頃からHadoopを利用しはじめましたが、日本国内でも2009年あたりからHadoopを使った事例を多く見聞きするようになりました。国内で初めてのHadoop関連イベントが2009年11月に東京で開催され、オライリー・ジャパンから2010年1月にHadoop本の邦訳が出版されるなど、Hadoopが多くの開発者の注目を浴びています。
しかしながら、「Hadoopは何となくすごそうなんだけど、複雑だし、どんなソフトなのかいまいち分からないんだよね」という声も多く聞きます。その理由を考察してみると、Hadoopというソフトウエアは「インフラ」の性質を色濃く持っているという原因にたどり着きます。Hadoopを「インフラ」としてとらえ直すことで、複雑に見えるHadoopをすんなりと理解することができます。
本連載では、膨大なデータ処理のニーズをかかえている方々や、Hadoopを実際に利用することを検討されている方々を対象に、Hadoopを活用したシステム構築をするために必要な基礎知識を解説していきます。今回は、インフラのたとえ話を使って、Hadoopの大まかなイメージをお伝えします。
インフラとは何か?
私たちの生活を支えているさまざまなシステム、例えば道路、鉄道、港湾、航空、水道、ガス、電気、電話、放送、インターネットなどのことを、総称して「インフラストラクチャ」、略して「インフラ」と呼んでいます。
現代生活は、自分一人だけの力では決して成り立ちません。いま皆さんが目にしているPCのディスプレイは、原材料や完成品を運ぶための道路・船舶・飛行機、生産や運搬を支えるエネルギの供給、動作に不可欠な安定した電気の供給、それにインターネットの存在があって初めて、皆さんの役に立っています。どれ一つ欠けても生活に支障をきたす大事な存在、それがインフラです。
インフラがもつ性質は、以下のように整理できます。
- 複雑な仕組みを持っている
- インフラと呼ばれるものはすべて、高度な専門知識によって支えられています。一見ローテクに見える水道システムも、水道工学という専門分野が必要とされるほど複雑な仕組みになっています。例えば、ダムを建設するには、土木工学の知識をはじめ、周辺地域の地質や気候などの綿密な調査がかかせません。
- 莫大(ばくだい)な維持コストを分担する仕組みがある
- 複雑な仕組みを維持するためには莫大(ばくだい)なコストがかかりますので、コストを分担する仕組みはかかせません。水道であれば水道料金が課金されますし、一般道路は税金によって維持管理されています。中には一部の図書館や病院のように、慈善家の寄付によって維持されているインフラもあります。
- ブラック・ボックス化されている
- 複雑な仕組みを持っているにもかかわらず、利用者にはそれが見えにくくなっているのも大きな特徴です。例えば水道システムであれば、利用者から目に見える部分は「蛇口」「流し」「料金の請求書」くらいです。極めて簡単ですよね。ブラック・ボックス化は、インフラを誰にでも簡単に使えるようにする上で、極めて重要なものです。利用者の目に触れないようになっていることの当然の帰結として、利用者はふだんインフラの存在を意識することはありません。水道の蛇口をひねるたびに、裏に隠れている複雑な仕組みに想いを馳せる人はいないでしょう。また、利用することによってどれだけコストがかかるかも意識させません。
インフラの一例として、水道システム(上水道・下水道)の仕組みを図1に示します。水道システムがいかに複雑な仕組みで成り立っているか、それにもかかわらず利用者から見ると非常に単純に見えることがお分かりいただけるかと思います。
|
| 図1: 水道システム(上水道・下水道)の仕組み(クリックで拡大) |
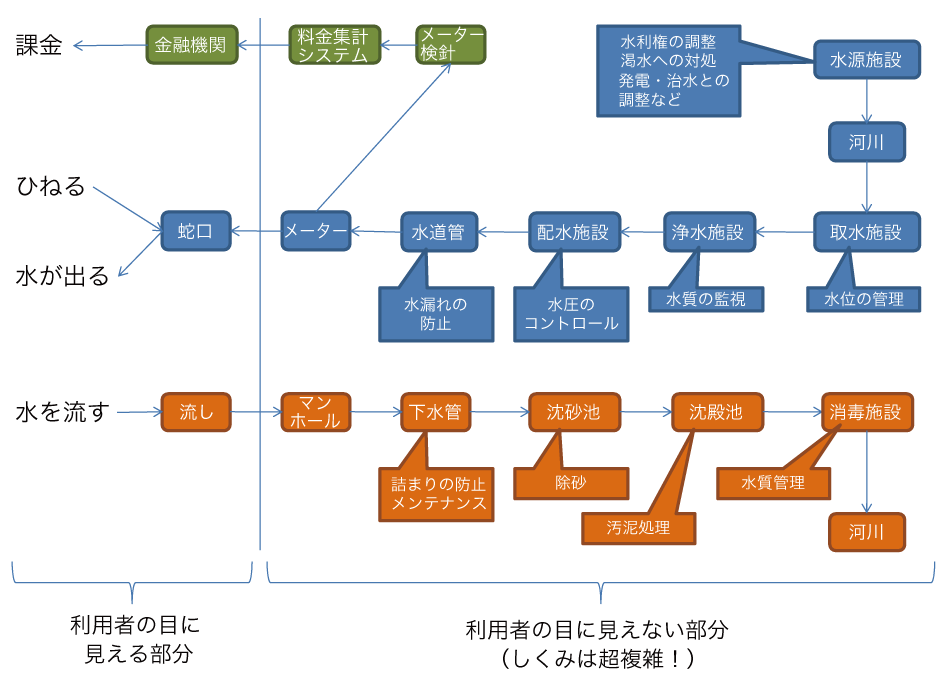
ふだん慣れ親しんでいる水道や電気といったインフラは、その複雑な仕組みをすべて理解している人はほとんどいないにもかかわらず、それが何なのかという疑問を抱くことはありません。
しかし、新しく登場したインフラについては、必ずしもそうではありません。例えば1990年代後半に一般に普及し始めたインターネットは、当時の多くの人々にはよく分からない存在でした。家電量販店の店頭でおじさんが「インターネットください」と店員に言った、という笑い話もあったくらいです。
新しく登場したインフラが分かりにくくなってしまう原因は、インフラのもつ「複雑な仕組み」と、「複雑な仕組みを見えないようにする性質」にあるといえます。
例えば、Google AppsやSalesforceなどを代表とする「クラウド」は、現代のインフラになりつつあります。いろいろなクラウド・サービスを調査してみると、どのサービスも裏側のシステムは極めて複雑になっていること、一方でシンプルに利用できるように、裏側が見えないように工夫が凝らされていることが分かります。だからこそ、「クラウドとはいったい何なのか」が一般の人々には分かりにくくなっていると考えられます。
実は、Hadoopも上に挙げたインフラと同じような性質を備えています。それでは、いったいHadoopはどんなインフラなのでしょうか?私は、「情報爆発時代のバッチ処理インフラ」であるととらえています。どういうことかを、これから示していきます。
- この記事のキーワード
この記事をシェアしてください
関連記事

バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
