ファイルの読み書きをしてみよう!
ファイルの読み書きをしてみよう!
ここからは、ファイルの読み書きを行うプログラムを作成し、Goへの理解をさらに深めていきましょう。今度はまず以下の作業を行なってください。
リスト26:サンプルプログラムのための準備
cd $GOPATH
mkdir -p src/mycode/operater
cd src/mycode/operater
移動したディレクトリ内に、以下の内容の「operater.go」を作成してください。
リスト27:operater.go
package operater
import (
"fmt"
"log"
"os"
)
// Operaterインターフェースの宣言。
// このインターフェースはWrite, Read, Printの3つのメソッドを持つことを示す。
type Operater interface {
Write(text string)
Read()
Print()
}
//-------------------------------
// ファイルの内容とパスを格納する構造体。
type filedata struct {
contents []byte
path string
}
// ファイルに指定された文字列を5回書き込むメソッド。
func (f *filedata) Write(text string) {
file, err := os.Create(f.path)
if err != nil {
log.Fatal("create error")
return
}
defer file.Close() // 必ずファイルをクローズする。
_, err = file.Write([]byte(text + "\n"))
if err != nil {
log.Fatal("write error : ", err)
return
}
}
// ファイルの内容を読み込んで自分の中に保存するメソッド。
func (f *filedata) Read() {
file, err := os.Open(f.path)
if err != nil {
log.Fatal("open error : ", err)
}
defer file.Close() // 必ずファイルをクローズする。
_, err = file.Read(f.contents)
if err != nil {
log.Fatal("read error :", err)
}
}
// 読み込んだファイルの内容を出力するメソッド。
func (f *filedata) Print() {
fmt.Printf("%s", f.contents)
}
//----------------------------------
// 空の構造体とメソッド
type nildata struct {}
func (f *nildata) Write(text string) {}
func (f *nildata) Read() {}
func (f *nildata) Print() {
fmt.Println("nil")
}
//----------------------------------
// Operaterインターフェースを持つ構造体を返すファクトリメソッド
func New(path string) Operater {
// 引数でファイルパスを指定されていればfiledata構造体を、
// 指定されなければnildata構造体を返す。
// どちらもOperaterインターフェースを実装しているため、
// 戻り値の型はOperaterで良い。
if path != "" {
return &filedata{
path: path,
contents: make([]byte, 1024),
}
}
return &nildata{}
}
また、先ほどの「server.go」や上の「operater.go」とは別のディレクトリの中に、以下の内容の「main.go」を作成してください。
リスト28:main.go
package main
import "mycode/operater"
func main() {
fileData := operater.New("sample.dat")
fileData.Write("hello")
fileData.Read()
fileData.Print() // helloを5回出力
// fmt.Printf("%s", fileData.contents) // <- エラー
fileData = operater.New("")
fileData.Write("hello")
fileData.Read()
fileData.Print() // nilを1回出力
}
ここまで作ったら、以下のようにコマンドを実行してください。
リスト29:main.goを実行する
$ go run main.go
hello
hello
hello
hello
hello
nil
成功すれば、上のように出力され、「main.go」と同じディレクトリの中に「sample.dat」が作られているはずです。
ここからは、新しく出てきた記法について解説します。
構造体
GoにもC/C++と同じように「構造体」という概念が存在します。構造体はフィールド(識別子と型、識別子は省略可能)の集まりを表し、書式は以下のようになります。
リスト30:構造体の書式
struct {
フィールド名 型
型 // 匿名フィールド
:
}
通常は以下のように「type」を使うことで、構造体に識別子を付けて新しい型を作り、扱いやすくします。
type person struct {
今回作ったプログラムでは「filedata」という識別子を付けた構造体の型を定義し、その中に「「[]byte型」のフィールド「contents」」と「「string型」のフィールド「path」」を含めています。
リスト31:filedata型構造体の定義
type filedata struct {
contents []byte
path string
}
この構造体を使うことにより、「ファイルの内容」「ファイルパス」といった複数のデータを
「ファイル情報」という形でひとつにまとめることができます。
ループ
前回も説明しましたが、Goではループを実行するための制御構文は、この「for」のみとなります。書き方としては、以下の4パターンが存在します。
無限ループ
「break」、「return」、「goto」などで抜け出さない限り、永遠に処理内容を実行し続けます。
for {
// 処理内容
}
条件ループ
他の言語の「while」と同じく、条件を満たし続けている間ループします。
for flag == true {
// 処理内容
}
回数指定
括弧が存在しない点以外は、C言語などでおなじみの書き方です。以下の例では最大10回処理を繰り返して終了します。
for i:=0; i < 10; i++ {
// 処理内容
}
範囲走査
配列、スライス、マップ、チャネルなど、複数のデータを持つ型の内容を一通り抜き出す形でループします。以下の例では変数「numbers」の内容に合わせて3回処理を実行して終了します。
numbers := []int{1,2,3}
for i, n := range numbers {
// i : スライスのインデックス(0~2)
// n : スライスの要素(1~3)
// 処理内容
}
メソッド
Goは、最近の多くの言語が備えている、オブジェクト指向の「型継承」の仕組みを言語仕様として持っていません。 そのため、Goを使っていく中で「クラス」や「継承」といった言葉は通常出てきません。 しかし「メソッド」の概念は存在し、「自パッケージ内で「type」で定義した型」に紐づいた関数として定義することができます。 以下は「filedata」構造体に対して「Writeメソッド」を持たせています。
リスト35:メソッドの定義例
func (f *filedata) Write(text string) {
メソッドの定義と関数定義との違いは、「func」の後ろに「(f *filedata)」がある点です。この「f」を「レシーバ」と呼び、メソッドと紐づいている型と、その識別子を示しています。関数の中で引数を扱えるのと同じように、メソッドの中では「レシーバ」も扱うことができます。
また、メソッドは上に書いた通り「自パッケージ内でtypeで定義した型」に紐付けることができるため、
構造体以外の型に対してもメソッドを持たせることができます。以下では、string型変数のsに対して「Print」メソッドを持たせています。
type Str string
func (s Str) Print() {
fmt.Printf("str = %s\n", s)
}
なお、「自パッケージ内でtypeで定義した型」以外にメソッドを紐づけようとすると、以下のようなエラーが発生します。注意してください。
./main.go:9: cannot define new methods on non-local type string // stringをレシーバに指定した場合
アクセス
Goの識別子には以下のルールが存在します。
- 先頭が大文字で定義されているものは、他のパッケージからアクセス可能
- 先頭が小文字で定義されているものは、他のパッケージからアクセス不可能
このアクセスの概念は、オブジェクト指向の「カプセル化」と同等のものです。外部に見せる必要のない変数やメソッドは、先頭を小文字にすることで隠しましょう。
リスト37:メソッド名のルール
func main() {
:
(略)
// fmt.Printf("%s", fileData.contents) // <- エラー
上の「fileData.contents」は、「filedata」の変数「contents」に直接アクセスしようとしていますが、最初の「c」が小文字のため、アクセスすることができません。そのため、この行のコメントを外して実行しようとすると、エラーになります。
インターフェース
Goの最大の特徴のひとつとも言えるのが、このインターフェースです。以下はインターフェースの書式です。
リスト38:インターフェースの書式
interface {
メソッド名([引数]) [返り値]
:
}
構造体と同じく、通常は以下のようにtypeを使うことで識別子を付け、扱いやすくします。
type Writer interface {
構造体の書式とよく似ていますが、「struct」の代わりに「interface」である点と、中に書かれているのがメソッドである点が異なります。今回のプログラムでは以下のように「Write」、「Read」、「Print」という3つのメソッドを持つ「Operater」というインターフェースを宣言しています。
リスト39:インターフェースの宣言例
type Operater interface {
Write(text string)
Read()
Print()
}
このインターフェースという概念の利点はどこにあるのでしょうか? それは、インターフェースで定義されているメソッド全てを型に持たせると、型やメソッドの具体的な中身が違っていても、使う側は同じ型とみなして扱うことができることです。イメージが難しいと思いますので、ここでもう一度「main.go」の内容を見てみましょう。
リスト40:main.go(再掲)
func main() {
fileData := operater.New("sample.dat")
fileData.Write("hello")
fileData.Read()
fileData.Print() // helloを5回出力
:
fileData = operater.New("")
fileData.Write("hello")
fileData.Read()
fileData.Print() // nilを1回出力
}
最初の「operater.New()」では「filedata」の構造体が返されています(「operater.go」の「New関数」を参照)。それに対し、2回目の「operater.New」では「nildata」の構造体が返されています。この2つは、実際には別の型です。
しかし、どちらも同じように「fileData」変数に格納できており、その後のメソッド呼び出しも全く同じようにできています。もちろん、メソッドの中身は異なるため、実行結果は異なります。この時、「fileData」変数は「Operaterインターフェース型」となっています。なので、Operaterインターフェースが示すメソッドを一通り持たせている型であれば、何でも代入することができるのです。
このようにすれば、operaterパッケージ使う側は、パッケージの内容がどうなっているかNewの結果として具体的に何の型が返ってくるのか、一切を気にする必要がなくなり、ブラックボックスとして扱えます。すなわち、パッケージ間が疎結合になり、より堅牢なプログラムを作ることができます。
なお、もしインターフェースの実装が不十分だったなら、どのような実行結果になるのでしょうか。以下は「nildata」から「Readメソッド」を削除した状態で「go run」を実行した結果です。
リスト41:インターフェース実装が不完全な場合
$ go run main.go
# mycode/operater
operater/operater.go:71: cannot use nildata literal (type *nildata) as type
Operater in return argument:
*nildata does not implement Operater (missing Read method)
エラーメッセージの中に、「*nildata does not implement Operater (missing Read method)」(nildata構造体がOperaterインターフェースを実装していない (Readメソッドが見つからない))と出力されているのが分かります。このようにインターフェースが正しく実装されているかどうかも、Goコンパイラがちゃんとチェックしてくれます。
また、Goでは「interface{}」という表現がよく出てきます。
これは実装すべきメソッドが何も無いインターフェースを表しています。
実装しないといけないメソッドが何も無いということは、逆説的に言えば、Goに存在するあらゆる型は「「interface{}」というインターフェースを実装している」と言えます。
そのため、「interface{}」型の変数には、どのような内容でも代入することが可能となります。
ポインタ
ここまでのプログラムの中で、型の前に「「&」」や「「*」」といった記号が登場することがありました。
リスト42:記号「*」の使用例
func (f *filedata) Read() {
リスト43:記号「&」の仕様例
return &filedata{
これは「C/C++」をご存知の方ならおなじみの「ポインタ」です。ご存知ない方のために、簡単な概要図を書いておきます。
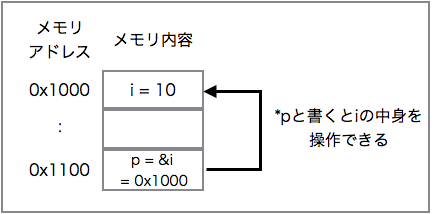
ポインタの概念図
プログラムはコンピュータのメモリ内で動作するものなので、変数はメモリのどこかの位置(アドレスと呼びます)に割り当てられ、その位置に値が格納されます。そしてポインタとは、その『変数の位置(アドレス)』を表します。
上の図において「i」は変数であり、アドレス0x1000に割り当てられ、中に10という値が入っています。それに対し「p」は「i」の位置を示すポインタであり、アドレス0x1100に割り当てられ、中に0x1000という値が入っています。
説明だけでは分かりづらいと思いますので、以下のような簡単なプログラムを作って動かしてみましょう。
リスト44:ポインタの例
func sum1(a int, b int) {
a += b
}
func sum2(a *int, b int) {
*a += b
}
func main() {
a := 1
b := 2
sum1(a, b)
fmt.Printf("a = %d\n", a) // 結果は1
sum2(&a, b)
fmt.Printf("a = %d\n", a) // 結果は3
fmt.Printf("&a = %x\n", &a) // 結果は?
}
リスト45:実行例
$ go run main.go
a = 1
a = 3
&a = c42000a2d0 # 環境によって結果が変わります。
最後の「&a」のように「&」を変数名の前につけることで、ポインタを表します。その「&a」の内容は大きな桁数の16進数となっていますが、これは変数aがメモリの「c4200a2d0」というアドレスにあるということを示しています。このポインタを使うことで、関数に対して、引数にした変数の「アドレス」を渡すことができるようになります。関数側は、引数の型の前に「*」をつけることで、そのアドレスを受け取れます。この渡し方を便宜的に「ポインタ渡し」と呼びます。
この「ポインタ渡し」について、もう少し掘り下げて説明します。Goでは、関数の引数は「値渡し」と呼ばれる方法で渡されます。これは変数の内容を、メモリ内の別のアドレスに丸々コピーし、関数の中ではコピーした方を使うことを意味しています。コピーしているわけなので、関数内で引数に対して何をしようが、呼び出し元の変数には一切影響を与えません。ここで上のプログラムを見てください。sum1は関数の引数として、変数そのものを渡されています。そして変数aに変数bを加えていますが、main関数の変数aは"1"のままです。それは、「main関数の変数a」と「sum1関数の引数a」が別の存在だからです。
それに対し、ポインタを渡した場合、関数の中からポインタを介して呼び出し元の変数を見ることができるため、呼び出し元の変数を書き換える処理ができるようになります。例として、上のプログラムのsum2は、引数としてポインタを渡されています。そして変数*aにbを加えた結果、main関数の変数aが"3"に変わります。*aの「*」には「ポインタが示す場所を操作する」という意味があり、「デリファレンス」と呼びます。「デリファレンス」することで、「main関数の変数a」と「sum2関数の変数a」が全く同じ存在となり、sum2の中で変数aを操作した結果がmain関数に影響します。
ポインタ渡しをする意味は、大きく以下の2つがあります。
- 引数が巨大なデータの場合に、それをコピーしなくて済む。(メモリの節約とパフォーマンスの向上)
- 呼び出し元の変数を関数の中で操作できる。
特に最初のメリットが大きいため、構造体を使う場合はポインタ渡しを用います。また、3.4項で説明した変数のうち、「スライス」「マップ」「チャネル」のいわゆる「参照型」と呼ばれる変数は、
「&」や「*」といった記号を使わずとも、 自動的に参照渡しになります。
これも「参照型」の変数は、いずれも大きいデータ量を扱うことが多いためと考えられます。
おわりに
いかがでしたでしょうか。
本章では簡単なプログラムを2つ作成しつつ、Goの文法基礎を説明しました。次回からは、Goの有名なWebフレームワークであるRevelを使い、本格的なWebアプリを作っていきましょう。
(編注:2017年7月21日15時20分更新)記事公開当初の内容に誤植と技術的な誤りがありました、お詫びして訂正致します(解説を大幅に追加しました)。今回の修正と第3回以降の記事では外部監修者によるチェック体制を強化しております。
バックナンバー
この記事の筆者

Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
