Rancherコードリーディング入門(3/3)
前回に続き、紙面の都合で「RancherによるKubernetes活用完全ガイド」に掲載されなかったパートをご紹介します。
2020年2月19日 6:00
前回の記事では、Rancher Agent(pkg/agent)とRancher API(pkg/api)がどのように実装されているのか紹介しました。
今回の記事では、Rancherコードリーディング入門の最後として、Rancher Controller(pkg/controllers)に関するコードをどのように読み進めればよいか紹介します。
3回目:Rancher Controller、Rancherの周辺レポジトリについて紹介します
- rancher/rancherレポジトリの歩き方(3/3)
- Rancherのアプリケーションコード
- pkg/controllers
- Rancherのアプリケーションコード
- rancherレポジトリ以外の重要なレポジトリについて
- rancher/types
- rancher/rke
- rancher/kontainer-engine
- rancher/norman
本連載について
本連載では、コードリーディング入門の連載3回目として、Rancher Controller(pkg/controllers)について詳しく紹介していきます。
rancher/rancherレポジトリの歩き方(3/3)
Rancher Controllerについては、事前知識なしでいきなりコードの説明に入ると理解がかなり難しいと思います。そこでRancher Controllerについて「3種類に分けられるRancher Controller」と「Rancher ControllerのベースとなるNorman Generic Controller」のおさらいをしてから、コードの説明に入ります。
3種類に分けられるRancher Controller
Rancher Controllerは、必要に応じてRancherが起動しているKubernetes、Rancherで管理されているKubernetesの両方のリソース(カスタムリソース含む)を監視し、変更があった場合にはその内容に沿って、新しくKubernetesクラスタを構築したり、ノードを追加したり、新しくDeploymentリソースを作成したりします。
現在、40種類以上のControllerがRancher Server内に実装されています。
Rancher Controllerは、ライフサイクルや管理対象によって、下記の3種類に分類されます。
- API Controllers
- 複数台起動した時、Leaderを含むすべてのRancher Serverで起動される
- 1台のコントローラで1つのRancher Serverの状態管理をするため、同一Rancher Server内で複数の同じコントローラは起動されない
- Rancher API Serverの設定や、Rancher API関連の処理に責任を持つ
- Rancherが起動しているKubernetes上のリソースのみを監視する
- Management Controllers
- 複数台起動した時、Leaderに選ばれたRancher Serverでのみ起動される
- 1台のコントローラでRancher Serverクラスタの状態管理をするため、クラスタ全体で同一のコントローラが複数起動されることはない
- 特定のKubernetesクラスタに縛られないRancher Serverクラスタ(同じKubernetes上で起動する複数のRancher Serverを「クラスタ」と一括りで表現している)内の状態に責任を持つ
- Rancherが起動しているKubernetes上のリソースのみを監視する
- User Controllers
- 複数台起動した時、各Kubernetesクラスタに対して、Owner Rancher Serverが決定され、Owner Rancher Serverのみで起動される
- コントローラ1台は、1つのKubernetesクラスタの専属コントローラになるため、複数のKubernetesクラスタを管理している場合は、複数のコントローラが起動される
- Rancherで管理している各Kubernetesクラスタの状態管理と、Kubernetesをより便利に使うための付加機能に責任を持つ
- Rancherが起動しているKubernetes上のリソースとRancherが管理しているKubernetesのリソース、必要に応じて両方を監視する
API Controllersについては、前回の記事のRancher API(pkg/api)の解説のところで、すでに紹介しているため、今回は紹介しません。pkg/controllers配下のコードで実現されているManagement ControllersとUser Controllersについては、後ほど紹介します。
Rancherのコントローラ実装のベースとなるGeneric Controllerの仕組み
Rancherのすべてのコントローラは、NormanのGeneric Controllerをベースに実装されているため、Rancher Controller(pkg/controllers)の実装を読み解いていく前に、NormanのGeneric Controllerについて理解する必要があります。
Generic Controllerは、下記のような構造になっています。
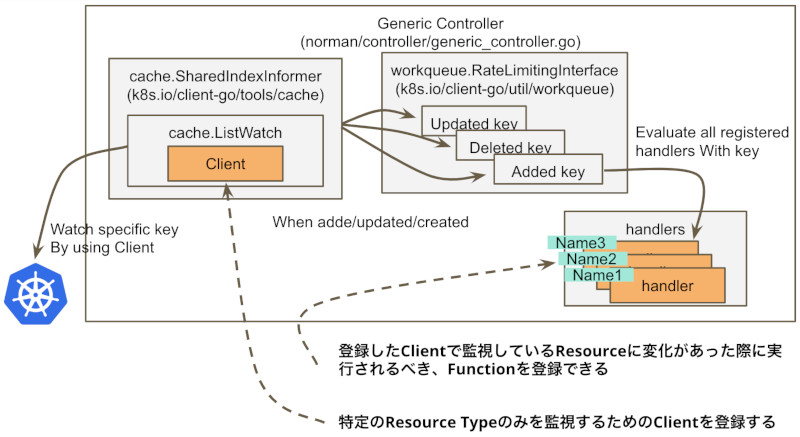
Generic Controllerの構造
SharedIndexInformerは、Kubernetesのclient-goライブラリ内の構造体です。Generic Controllerは、初期化時に渡されるKubernetes Clientを利用して、SharedIndexInformerを初期化しています。
SharedIndexInformerは、Index機能付きの共有キャッシュストレージで、初期化時に渡されたKubernetes Clientを利用して、取得できるKubernetesのリソースをオンメモリにキャッシュします。Index機能を持っているため、リソースが新しく検知された時に評価されるIndex Functionも複数登録することができます。Index Functionは、リソースを引数に取り、文字列の配列を返り値とする必要があり、この返り値でリソースを検索可能にします。
また、このSharedIndexInformerは、共有キャッシュストレージに対する追加、変更、削除のEventでトリガーされるFunctionを、cache.ResourceEventHandlerFuncs(k8s.io/client-go/tools/cache)として登録することができます。
Generic Controllerではcache.ResourceEventHandlerFuncsで、すべてのEventを同じくclient-goライブラリのRate Limit機能付きのQueueに伝搬しています。抽象的にEventと表現していますが、実際には変更のあったObjectが伝搬されています。
Generic Controllerは、このQueueからひたすらEvent(変更のあったObject)を取得し、そのEventに対して特定の処理を実施するためのHandlerを実行するgoroutineを複数起動しています。この時Handlerの実行に失敗すると、該当のEventは再度Queueに戻されます。
Generic Controllerを使うと、このKubernetes ClientとHandler部分だけを用途ごとに差し替えるだけで、簡単にKubernetesのコントローラを実装できます。
Rancherは、コントローラを通じて監視したいリソースタイプ(Node、Cluster、Catalog……)ごとに、1つのGeneric Controllerを作成しています。そのGeneric Controllerに対して、様々なHandlerを登録する形で、Rancherに必要なコントローラの実装をしています。
Rancherの実装では、1つのGeneric Controllerに複数の意味を持つHandlerが登録されることになるので、Generic Controllerとは言いつつも、コントローラとして考えると何を実現するためのコントローラなのか理解が難しくなります。そのため、「pkg/api/controllersの配下のディレクトリ名」「pkg/controllers/managementの配下のディレクトリ名」「pkg/controllers/userの配下のディレクトリ名」をコントローラとして捉える対象とみなすと、理解しやすいでしょう。
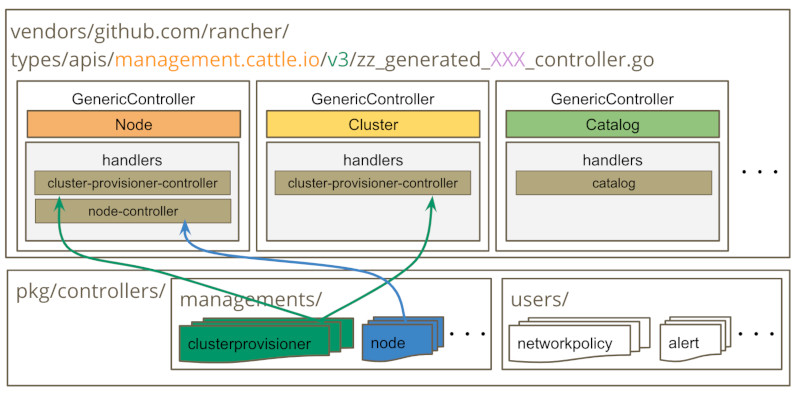
Generic ControllerとHandler
これらのディレクトリは、意味のある単位で分けられています。例えば、pkg/controllers/management/clusterprovisionerは、Kubernetesクラスタの構築に責任を持ち、NodeリソースのGeneric ControllerとClusterリソースのGeneric Controllerに、node-controllerという名前のHandlerを登録しています。
リスト1:pkg/controllers/management/clusterprovisioner/provisioner.go
44 func Register(management *config.ManagementContext) {
~省略~
53
54 // Add handlers
55 p.Clusters.AddLifecycle("cluster-provisioner-controller", p)
56 management.Management.Nodes("").AddHandler("cluster-provisioner-controller", p.machineChanged)
57
~省略~
71 }
上記内でp.ClustersはClusterリソースのGeneric Controllerで、management.Management.Nodes("")は、NodeリソースのGeneric Controllerになります。
さて、ここで「LifeCycle」というまだ解説していない概念が出てきました。LifeCycleは、HandlerのためのFrameworkのようなものです。
Handlerは単純なFunctionを登録しますが、LifeCycleの場合はCreate、Finalize、Updatedを実装した構造体を登録します。それぞれ、作成時に評価されるFunction、常に評価されるFunction、削除時に評価されるFunctionであり、リソースのLifeCycleを容易にHandlerとして実装することができます。
またNormanのレイヤでは、Create、Finalize、Updatedを実装した構造体ですが、RancherがLifeCycleの登録をするときは、Create、Remove、Updatedを実装した構造体になっています。内部的に、RancherがLifeCycleオブジェクトを変換しているので、ここの違いは特に意識する必要はありません。
AddLifecycleをすると、最終的にはlifecycle.NewObjectLifecycleAdapter(https://github.com/rancher/norman/tree/master/lifecycle)にCreate、Finalize、Updatedを実装したLifeCycleオブジェクトが渡され、NewObjectLifecycleAdapterの返り値であるobjectLifecycleAdapterのsync関数が、Handlerとして登録されます。

AddLifecycleの流れ
そのため、Generic Controllerで変更を検知した際に呼ばれるHandlerは、objectLifecycleAdapterのsync関数になります。どのように登録したLifeCycleオブジェクトが評価されるのか、どのように作成時、削除時などの判断をしているのか、もう少し詳しく見ていきます。
Handlerに登録されるobjectLifecycleAdapterのsync関数は、次のようになっています
リスト2:vendor/github.com/rancher/norman/lifecycle/object.go
43 func (o *objectLifecycleAdapter) sync(key string, obj runtime.Object) error {
44 if obj == nil {
45 return nil
46 }
47
48 metadata, err := meta.Accessor(obj)
49 if err != nil {
50 return err
51 }
52
53 if cont, err := o.finalize(metadata, obj); err != nil || !cont {
54 return err
55 }
56
57 if cont, err := o.create(metadata, obj); err != nil || !cont {
58 return err
59 }
60
61 copyObj := obj.DeepCopyObject()
62 newObj, err := o.lifecycle.Updated(copyObj)
63 if newObj != nil {
64 o.update(metadata.GetName(), obj, newObj)
65 }
66 return err
67 }
sync関数の中で、o.finalize、o.create、o.updateを呼び出しています。これらの関数を1つずつ紹介していきます。最初に評価されるのは、o.finalize関数です。
リスト3:o.finalize関数
76 func (o *objectLifecycleAdapter) finalize(metadata metav1.Object, obj runtime.Object) (bool, error) {
77 // Check finalize
78 if metadata.GetDeletionTimestamp() == nil {
79 return true, nil
80 }
81
82 if !slice.ContainsString(metadata.GetFinalizers(), o.constructFinalizerKey()) {
83 return false, nil
84 }
85
86 copyObj := obj.DeepCopyObject()
87 if newObj, err := o.lifecycle.Finalize(copyObj); err != nil {
88 if newObj != nil {
89 o.update(metadata.GetName(), obj, newObj)
90 }
91 return false, err
92 } else if newObj != nil {
93 copyObj = newObj
94 }
95
96 return false, o.removeFinalizer(o.constructFinalizerKey(), copyObj)
97 }
この関数は、クリーンナップ処理に責任を持ち、リソースにDeletionTimestampが設定されている場合のみlifecycle.Finalizeを評価します。そしてlifecycle.Finalizeがerrを返さなかった場合のみ、Finalizerから自分のLifecycleに対応するFinalizerを削除します。
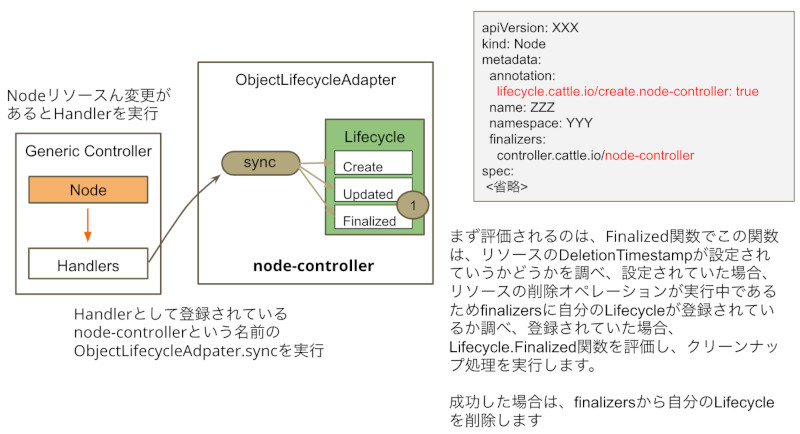
Finzlizer削除の流れ(o.finalize)
続いて評価される関数は、o.create関数です。
リスト4:o.create関数
147 func (o *objectLifecycleAdapter) create(metadata metav1.Object, obj runtime.Object) (bool, error) {
148 if o.isInitialized(metadata) {
149 return true, nil
150 }
151
152 copyObj := obj.DeepCopyObject()
153 copyObj, err := o.addFinalizer(copyObj)
154 if err != nil {
155 return false, err
156 }
157
158 if newObj, err := o.lifecycle.Create(copyObj); err != nil {
159 o.update(metadata.GetName(), obj, newObj)
160 return false, err
161 } else if newObj != nil {
162 copyObj = newObj
163 }
164
165 return false, o.setInitialized(copyObj)
166 }
この関数は、Annotation(lifecycle.cattle.io/create.<LifeCycleの名前>)をべースに、すでにlifecycle.Create関数の処理に成功しているかどうかを調べます。もし、lifecycle.cattle.io/create.<LifeCycleの名前>: trueのAnnotationが存在した場合、lifecycle.Create関数は評価されません。Annotationが見つからなかった場合はlifecycle.Create関数を実行し、リソースの初期化処理を実施します。
また、この関数は、リソースの削除前にlifecycle.Finalizeでリソースクリーンナップ処理が実施できるように、自分のLifeCycleに対応するFinalizer(controller.cattle.io/<LifeCycleの名前>)を追加します。
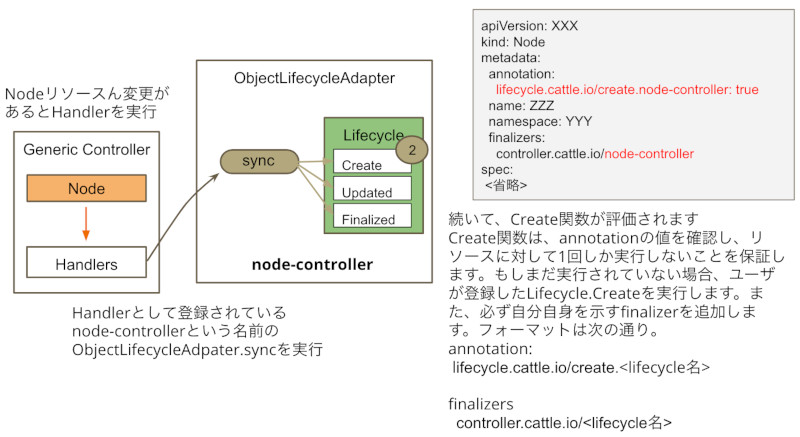
Finalizer追加(o.create)
最後に評価されるのは、o.updateになります。これはsync関数から直接実行され、状況に関わらず常に実行されます。
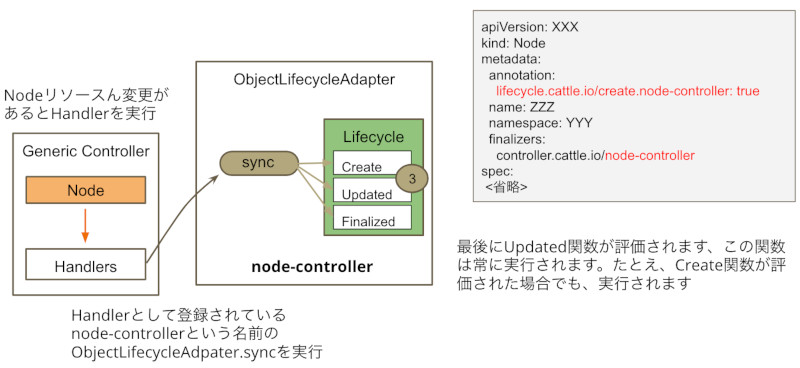
o.updateの実行
LifeCycleを利用すると、ここまで紹介したように、Finalizerや初期化処理のロジックを意識せずHandlerを実装することができます。
Rancherは、このLifeCycleとHandlerをうまく組み合わせて利用しています。一度だけ成功するまで実行したい初期化処理、リソース削除前に必ず実施したいクリーンナップ処理がある場合はLifeCycle、シンプルなロジックの場合はHandlerと使い分けをしています。
このようにRancherは、NormanのGeneric Controllerという仕組みをうまく使うことで、rancher/rancher側のコードでは、ビジネスロジックの実装に集中できるようにしています。
- この記事のキーワード
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
