はじめに
今回は前回にひき続き、午後Ⅰ試験対策として、SQLの設計に関する問題の解き方を、平成26年度午後Ⅰ試験問3の解説と併せて紹介します。SQLに関する出題も毎年行われており、業務上の問題を解決するためのデータベースアクセスプログラムの設計スキルが問われていることがわかります。この内容は午前Ⅱ試験の解答にも役立つので、しっかりと身につけましょう。
表データの探索(SELECT文)
ここでは、代表的なSQLの基本構文の概略を紹介します。
【構文】
SELECT [ ALL|DISTINCT ] 列指定 [ [AS] 別名] [, …]
FROM 表名 [, …]
[WHERE 探索条件]
[GROUP BY 列指定 [, …] ]
[HAVING グループの選択条件]
[ORDER BY {列指定|列の相対番号} [ASC|DESC] ]
(補足)
・[ ]は必要に応じて記述する箇所
・{ | }はどちらか一方を記述する箇所
- DISTINCTは重複データを削除した探索結果を返す
- 別名を指定した場合、以降の列指定には元の列指定ではなく別名を使用する必要がある
- GROUP BYを指定した場合、SELECT句の後ろの列指定はGROUP BYで指定した列指定または集合関数のみである
- ORDER BYの後ろのASCは昇順、DESCは降順で、省略時は昇順となる
探索条件
WHERE句で表データの探索条件を記載するには、以下の方法があります。
- 比較述語
比較演算子(=、>、>=、<、<=、<>)を用いて、条件を満たすデータのみ抽出します。【構文】
WHERE 値式1 比較演算子 値式2 - BETWEEN述語
値式1以上かつ値式2以下のデータのみ抽出します。【構文】
WHERE 値式 [NOT] BETWEEN 値式1 AND 値式2 - IN述語
指定した値のいずれかと一致するデータのみ抽出します。【構文】
WHERE 値式 [NOT] IN (値 [, …]) - LIKE述語
パターン文字列に%(任意の長さの文字列)と_(任意の1文字)文字列を指定し、文字列と部分的に一致するデータのみ抽出します。【構文】
WHERE 列指定 [NOT] LIKE パターン文字列 [ESCAPE エスケープ文字] - NULL述語
列値がNULLのデータのみ抽出します。【構文】
WHERE 列指定 IS [NOT] NULL
副問合せ
以下に示す構文で、括弧で囲んだSELECT文(副問合せ)の実行結果を基にデータを探索します。
- 比較述語
比較演算子を用い、条件を満たすデータのみ抽出します。【構文】
WHERE 値式1 比較演算子 ( SELECT文 ) - IN述語
指定した値のいずれかと一致するデータのみ抽出します。【構文】
WHERE 値式 [NOT] IN ( SELECT文 ) - 限定子
副問合せの実行結果が複数件あった場合の処理方法を指定します。【説明】【構文】
WHERE 値式 比較演算子 限定子 ( SELECT文 )
ANY(SOME):副問合せと比較した結果、1件以上該当するデータを抽出する
ALL:副問合せと比較した結果、全件と該当するデータのみ抽出する - EXISTS述語
副問合せ中に含まれる探索条件の結果が存在する(NOT EXISTSの場合は存在しない)データを抽出します。【構文】
WHERE [NOT] EXISTS ( SELECT文 )
集合関数
探索した結果を集計する関数で、多くの場合GROUP BY句と組み合わせて使用します。
【構文】
SUM(列指定):合計を求める
AVG(列指定):平均を求める
MAX(列指定):最大値を求める
MIN(列指定):最小値を求める
COUNT(列指定):データ件数(NULLを除く)を求める
表結合の代表的な構文
表結合を用いて複数の表を組み合わせ、データを抽出します。
- 単純結合
結合条件を満たすデータのみ抽出します。【構文】
SELECT 列指定 [ , …]
FROM 表名1 [相関名] ,表名2 [相関名] [ , …]
WHERE 結合条件 - 内部結合
結合条件を満たすデータのみ抽出します。【構文】
SELECT 列指定 [ , …]
FROM 表名1
[INNER] JOIN 表名2 ON 結合条件 - 外部結合
単純結合で抽出するデータに加え、一方の表に結合対象となるデータが存在しないものを抽出します。【説明】【構文】
SELECT 列指定 [ , …]
FROM 表名1
[ LEFT|RIGHT|FULL] [OUTER] JOIN 表名2 ON 結合条件- 左外部結合(LEFT OUTER JOIN)
表名2に該当するデータがない表名1のデータを抽出する - 右外部結合(RIGHT OUTER JOIN)
表名1に該当するデータがない表名2のデータを抽出する - 完全外部結合(FULL OUTER JOIN)
表名2に該当するデータがない表名1のデータ、および表名1に該当するデータがない表名2のデータを抽出する
- 左外部結合(LEFT OUTER JOIN)
複数のSELECT文の結果の組み合わせ
複数のSELECT文の実行結果を組み合わせ、データを抽出します。
- 和演算
2つのSELECT文の実行結果を足し合わせて返します。ALLをつけなかった場合は重複データを削除し、ALLを付けた場合は重複した結果を返します。【構文】
SELECT文1
UNION [ALL]
SELECT文2
SELECT文以外のSQL
- 表へのデータの挿入
既存の表にデータを挿入します。【構文】
INSERT INTO 表名 [(列名 [, ...])]
{ VALUES ( 列値 [, …])| AS SELECT文 } - 表データの更新
表に登録済みのデータの値を更新します。【構文】
UPDATE 表名
SET 列名 = 値式 [, …]
[ WHERE 探索条件 ] - 表データの削除
行単位で登録済みのデータを削除します。【構文】
DELETE FROM 表名
[ WHERE 探索条件] - 表の作成
新規に表を作成します。【構文】
CREATE TABLE 表名(
列名 データ型 [, 列制約 [, …] ]
[, 列名 データ型 [, 列制約 [, …] ] ]
[, 表制約 [, …] ]
【説明】- 定義可能な制約の種類
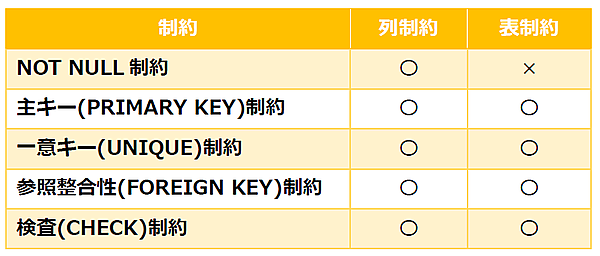
- 定義可能な制約の種類
- ビュー表の作成
仮想的な表であるビュー表を作成します。【構文】
CREATE VIEW ビュー表名 [ ( ビュー列名 [, …])]
AS SELECT文 - 権限の付与
ユーザーやロール(後述)に対して表やビュー表にアクセスする権限を付与します。【構文】
GRANT 権限 ON 表名 TO [ ユーザー名 | ロール名 ][, ] - ロールの作成
ユーザーに対して権限をまとめて管理するためのロールを作成します。【構文】
CREATE ROLE ロール名 - ロールの付与
作成したロールをユーザーや他のロールに付与します。【構文】
GRANT ROLE ロール名 TO [ ユーザー名 | ロール名 ][, …]
午後Ⅰ試験を解くためのポイント
いかがでしたか。これらの構文を理解できていたでしょうか。もし「理解が足りない」と感じた方は、しっかりと覚えてください。その際には実際にDBMSを使ってSQLを記述すると理解度が上がります。また、MySQLをはじめ無料で使えるDBMSもありますので、自分でSQLを書いてSQLの動作を体得するのも効果的です。
平成26年度午後Ⅰ試験問3に挑戦!
それでは、平成26年度午後Ⅰ試験問3に挑戦してみましょう。問題文はこちらからダウンロードしてください。また、解答用紙はこちらに用意しました。解答例はこちらをご覧ください。
問題の解答にかける時間は35分を目標にしましょう。
設問1の解説
(1)商品テーブルにUNIQUE制約を定義する列とその目的
〔受注管理システムの要求仕様〕2.注文(2)「表示される順番は,商品全体で重複がないように,商品企画担当者が決めた表示順に基づく。」より、表示順が商品全体で一意な値になるように定義することがわかります。また、目的もこの文章を活かして記入します。例えば、「商品全体で重複がないように、商品の表示順を決めるため」のようにすると良いでしょう。
(2)「単品商品」と「セット商品」に(1)と同じUNIQUE制約を定義するだけでは要求仕様を満たせない理由
案2では、商品データを「単品商品」と「セット商品」の各テーブルに格納します。ところが、〔テーブル設計〕に「受注管理システムに採用する予定のRDBMSのUNIQUE制約は,ユニーク索引を用いて実現される。ユニーク索引は,一つのテーブル内でキー列の一意性を保証するものであり,ユニーク索引を複数のテーブルにまたがって作成することができない。」と記載されており、これが要求仕様を満たせない理由です。したがって、「ユニーク索引を複数のテーブルにまたがって作成できないため」のように解答すればよいでしょう。
(3)外部キーの定義によって起きるおそれがある不都合
- 項番2「セット商品構成」テーブルの列「単品商品番号」に外部キーを設定した場合
案1の場合、「セット商品構成」テーブルの列「単品商品番号」に定義した外部キーによって参照する値は「商品」テーブルの主キーである列「商品番号」の値となります。ところが、「商品」テーブルの列「商品番号」には、単品の商品番号だけでなくセット商品の商品番号も設定できてしまいます。そこで、項番1の記載を参考に「単品商品番号列にセット商品番号を設定できてしまう。」とすればよいでしょう。 - 項番3「在庫」テーブルの列「商品番号」に外部キーを設定した場合
案2の場合、「在庫」テーブルの列「商品番号」に定義した外部キーによって参照する値は「単品商品」テーブルの主キーと「セット商品」テーブルの主キーである必要があります。ところが、1つの外部キーを複数テーブルの主キーに定義することはできません。したがって、「異なるテーブルの主キーを同じ外部キーに入力できない」のように解答すればよいでしょう。
(4)CHECK制約の空欄に入れる適切な述語
表1の列の意味より「社内原価」は単品商品のみに必要な列、「化粧箱番号」「詰合せ日数」はセット商品のみに必要な列であることがわかります。そこで、追加する検査制約は次のように定義します。
- 単品商品の場合、単品商品にだけ関連する列をNOT NULLにし、セット商品にだけ関連する列をNULLにする
- セット商品の場合、セット商品にだけ関連する列をNOT NULLにし、単品商品にだけ関連する列をNULLにする
CHECK ( ( 単品区分 = ‘Y’ AND ① AND 化粧箱番号 IS NULL AND 詰合せ日数 IS NULL )
OR ( 単品区分 = ‘N’ AND 社内原価 IS NULL AND 化粧箱番号 IS NOT NULL ) )
設問2の解説
(1)SQL2及びSQL3の実行結果をSQL1と同じにする
- SQL1
〔テーブル設計〕案1より、「商品」テーブルには単品商品とセット商品のデータを両方とも格納しています。そのため、SQL1は単品商品とセット商品の両方の注文データを返します。 - SQL2
〔テーブル設計〕案2より、単品商品とセット商品のデータを別テーブルに格納しています。SQL2を内部結合した場合、最初のJOIN文で単品商品のみに絞り込まれ、2番目のJOIN文で該当データがなくなります。そこで左外部結合を用いると、最初のJOIN文で単品商品に含まれないセット商品に関するデータも取り出され、2番目のJOIN文でセット商品に含まれない単品商品に関するデータも取り出されます。したがって、(f)は「LEFT OUTER」となります。 - SQL3
SQL3の4行目に「UNION ALL」句があります。そこで、UNION ALLの前のSELECT文は単品商品のみの注文データを抽出するSQLに、UNION ALLの後ろのSELECT文はセット商品のみの注文データを抽出するSQLにする必要があります。これらを実現するためには、2つのSELECT文は内部結合にしなければなりません。したがって、(g)は「INNER」となります。
(2)注文されたセット商品を構成する単品商品の合計を求めるSQL
SQL4とSQL5の両方とも単品商品番号でグループ化しているので、セット商品の注文数にセット商品を構成する単品商品の構成数を掛ければ導出できます。したがって、解答は「M.注文数*K.構成数」となります。
(3)SQL4のWHERE句にANDで追加すべき述語
アクセスパスは、SQLの処理効率に大きな影響を与えます。そのため、テーブルデータや索引データに対するアクセス回数を減らすことで処理効率を上げます。SQL4は単品商品とセット商品の両方のデータを含む「商品」テーブルを用いています。「注文明細」テーブルには単品商品とセット商品の両方の注文データを含むことから、「注文明細」テーブルと「商品」テーブルを結合した結果には単品商品とセット商品の両方のデータを含んでいます。したがって、単品商品とセット商品を合わせた回数だけ「セット商品構成」テーブルの主索引にアクセスします。そこで、探索条件にセット商品のみを抽出するための「AND P.単品区分 = ‘N’」を追加することで、「セット商品構成」テーブルの主索引に対するアクセス回数を減らせます。設問には「SQL4のWHERE句にANDで追加すべき述語を一つ答えよ」と記載されていることから、解答は「P.単品区分 = ‘N’」となります。
設問3の解説
(1)デットロックが起きる可能性の有無
〔注文トランザクションの設計〕から、以下の内容が明らかになります。
- (1)より、注文単位でトランザクションをコミットする
- (2)~(4)より、「注文」→「注文明細」→「在庫」テーブルの順で排他ロックを掛ける
- (3)より、「在庫」テーブルのデータに表示順に排他ロックを掛ける
- 〔受注管理システムの要求仕様〕2.(4)より、単品商品が不足することはないため、単品商品に関する注文明細の更新処理においては該当する単品商品の在庫データのみに排他ロックを掛ける
- (3)より、セット商品の注文明細について引当可能な場合は、該当するセット商品の在庫データのみに排他ロックを掛ける
- (4)と図4のセット商品構成テーブルの構造より、セット商品の注文明細について在庫不足の場合は該当するセット商品の在庫データに排他ロックを掛けた後、セット商品を構成する単品商品番号の順番で該当単品商品の在庫データに排他ロックを掛ける
- セット商品Xは商品AとB各1個ずつから構成されている
- セット商品Yは商品AとBとC各1個ずつから構成されている
- 商品の表示順はY→X→C→B→Aとする
- セット商品構成テーブルから在庫テーブルの単品商品にアクセス順はA→B→Cとする
TR1では単品商品BとAを、TR2ではセット商品Xと単品商品Aを注文したとします。このとき、以下の通り在庫データに対する処理を実行した場合の排他ロックの獲得可否を記載します。
- TR2で在庫データXの行に排他ロック → 〇
- 1.でXが在庫不足の場合、TR2で在庫データAの行に排他ロック → 〇
- TR1で在庫データBの行に排他ロック → 〇
- TR2で在庫データBの行に排他ロック → 3.により× (=ロック解除待ち)
- TR1で在庫データAの行に排他ロック → 2.により× (=デッドロック発生)
以上のことから、デッドロックが起きる恐れがあるため、(ウ)は×となります。
TR1では単品商品BとAを、TR3ではセット商品Xを注文したとします。このとき、以下の通り在庫データに対する処理を実行した場合の排他ロックの獲得可否を記載します。
- TR3で在庫データXの行に排他ロック → 〇
- 1.でXが在庫不足の場合、TR3で在庫データAの行に排他ロック → 〇
- TR1で在庫データBの行に排他ロック → 〇
- TR3で在庫データBの行に排他ロック → 3.により× (=ロック解除待ち)
- TR1で在庫データAの行に排他ロック → 2.により× (=デッドロック発生)
以上のことから、デッドロックが起きる恐れがあるため、(エ)は×となります。
セット商品1個ずつを注文する場合、在庫データへのアクセスはセット商品の行→セット商品を構成する単品商品(昇順)となり、在庫データへの排他ロック制御順が一定となります。したがって、デッドロックは起きないことになり、(オ)は〇となります。
TR3ではセット商品Xを、TR4ではセット商品YとXを注文したとします。このとき、以下の通り在庫データに対する処理を実行した場合の排他ロック獲得の可否を記載します。
- TR4で在庫データYの行に排他ロック → 〇
- 1.でYが在庫不足の場合、TR4で在庫データCの行に排他ロック → 〇
- TR4で在庫データBの行に排他ロック → 〇
- TR4で在庫データAの行に排他ロック → 〇
- TR3で在庫データXの行に排他ロック → 〇
- TR3で在庫データBの行に排他ロック → 3.により× (=ロック解除待ち)
- TR4で在庫データXの行に排他ロック → 5.により× (=デッドロック発生)
以上のことから、デッドロックが起きる恐れがあるため、(カ)は×となります。
(2)デッドロックを防ぐための更新順
デッドロックを防ぐために、すべてのトランザクションにおいて在庫テーブルへのアクセス順を統一します。「セット商品構成」テーブル経由で「在庫」テーブルにアクセスする場合は商品番号順となるので、「注文明細」テーブルから「在庫」テーブルへのアクセス順も表示順から商品番号順にすればデッドロックが発生しなくなります。
おわりに
今回は、午後Ⅰ試験の頻出内容からSQLに関する問題の解き方を紹介しました。この問題では、単にSQLを書かせるだけでなく、設問2(3)にあるような処理性能に関する問題や、設問3の同時実行制御に関する内容も含んでいます。これらの知識もデータベーススペシャリストとして必須なので、併せて理解してください。次回は、午後Ⅱ試験の頻出問題の解き方を紹介します。
- この記事のキーワード
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
