今回はPagerDutyをコンテナやマイクロサービスで使う方法と、PagerDuty APIを利用して簡単にSlack経由でインシデントを発生させるやり方をご紹介します。また、実際にインシデントマネジメントをどのように行っているかというスマートニュースの事例もご紹介します。
コンテナ/マイクロサービスでのPagerDuty
実のところコンテナやマイクロサービスだからといって、PagerDuty側でなにか工夫が必要かというとそんな事はありません。むしろ監視ツール側をどうするか、というほうが問題になってきます。
コンテナの監視をする場合、以下の2種類の方法があります。
- コンテナのホストにエージェントをインストールする
- モニタリング用のエージェントコンテナを起動する
1の場合は単純に、インスタンスなどが起動するときのスクリプトでエージェントのインストールと設定が行われるようにしておけばよいです。弊社の場合はAWSのECSでコンテナを起動していますが、ユーザーデータを使ってコンテナインスタンスごとに特定のコンテナが必ず起動するよう設定しており、Datadogのエージェントもそのようになっています。ちなみに必ず起動する特定のコンテナ、というのはConsul / Registrator / fluentd / dd-agentを指定しています。
docker run -d --name dd-agent --restart=always --no-healthcheck \
--hostname $instance_id \
--net=host \
--memory=128m \
--env-file /etc/envfile \
-v /var/run/docker.sock:/var/run/docker.sock:ro \
-v /proc/:/host/proc/:ro \
-v /cgroup/:/host/sys/fs/cgroup:ro \
-v /etc/dd-agent/conf.d:/conf.d:ro \
--log-driver awslogs \
--log-opt awslogs-region=$region \
--log-opt awslogs-group=/aws/ecs/$cluster/dd-agent \
--log-opt awslogs-stream=$instance_id \
--label task_name=dd-agent \
--label task_version=$dd_agent_image_tag \
--label system_container=true \
$dd_agent_image:$dd_agent_image_tag
実際のDatadogのダッシュボードでは以下のように見えています。
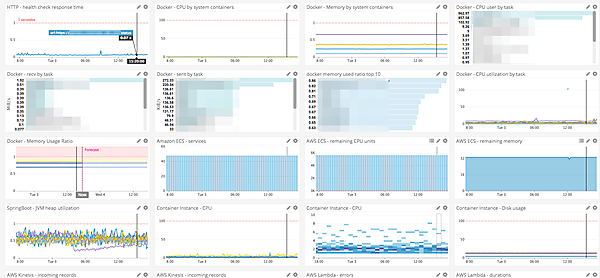
SlackからPagerDutyのAPIを利用して電話を鳴らす
わざわざWebの画面を開くことなく、いつも使っているSlackのようなチャットツールから、特定の人を緊急で呼び出したいということがままあります。PagerDutyの機能を使えば、コーディング不要でチャットを使って電話をかけることができます。
まず前提条件として、呼び出したい人が含まれているエスカレーションポリシーが作られており、そのエスカレーションポリシーを使っているサービスが必要です。連載2回目の「PagerDutyのエスカレーションポリシーとサービス」を参考に作成してください。
該当サービスの詳細画面にて、IntegrationsタブからNew Integrationボタンをクリックします。
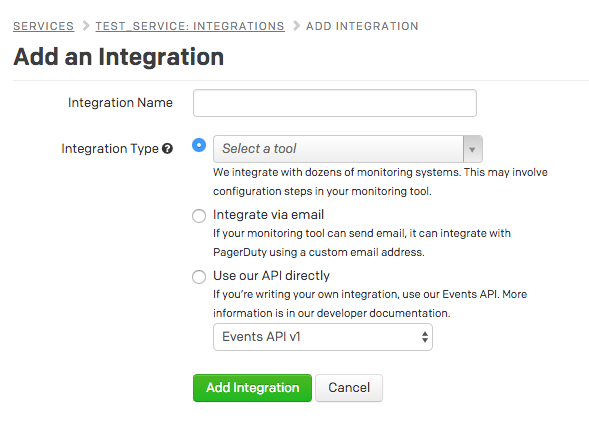
プルダウンに”Slack to PagerDuty”というツールがあるので、それを選択してAdd Integrationボタンをクリックします。一覧から今設定したインテグレーションを選択して詳細画面へ行くと、Integration URLというものが表示されているはずですので、コピーしておいてください。
次にSlackの設定を行います。https://api.slack.com/appsへ行きCreate New Appをクリックします。
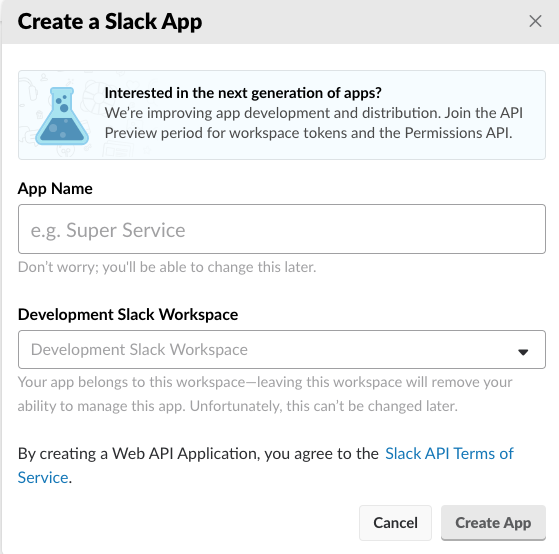
適当なApp Nameを入力し、自分の使っているSlackのワークスペースを選択します。そしてAdd features and functionalityにあるスラッシュコマンドを選択しましょう。
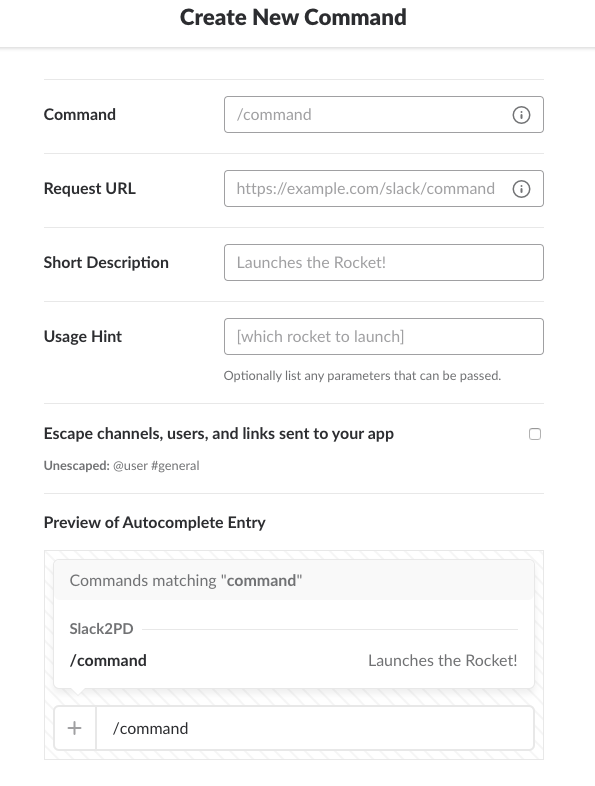
CommandはSlackでこのPagerDuty連携を呼び出すときに使うコマンドを指定します。Request URLには先ほどPagerDuty上でコピーした、Integration URLをペーストしてください。この設定が終わったらInstall your app to your workspaceでOAuthの認可をして終了です。正しく設定が終われば、Slackのチャット欄から先ほど指定したコマンドを入力することでIncidentを起こすことができます。
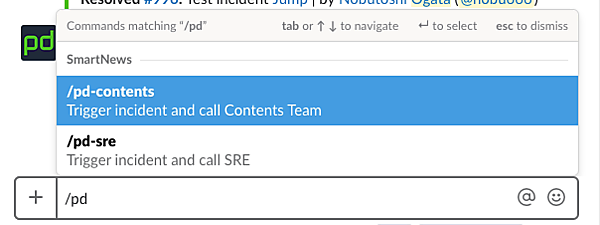
この方法は実装不要でとても楽なのですが、以下の問題点があります。
- コマンド利用可能な人を制限できない
- コマンド利用可能なチャンネルを制限できない
つまり、誰でも、どのチャンネルからでも電話が鳴らせてしまいます。従って、他に使っているスラッシュコマンドと似たような名前をつけてしまうと、誤爆でインシデントが発生してしまう可能性があります。スラッシュコマンドにはサジェスト機能がついていますので、間違って選ばれにくい名前をつけるようにしたほうがよいでしょう。
また、スラッシュコマンドはSlackのチャンネルには自分しか見えないメッセージとして処理されるため、誰がスラッシュコマンドを利用してインシデントをトリガーしたのか知るすべがありません。知りたい場合はPagerDutyの該当インシデントの詳細画面で、Timelineタブを見ることで確認できます。
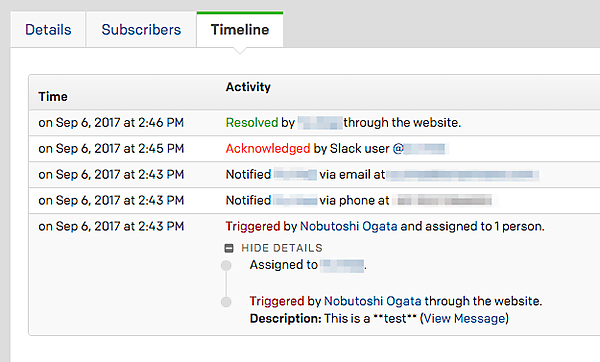
使えるチャンネルやユーザーを制限したい場合はこの方法では実現できません。連載第4回「PagerDutyのアプリ連携(Slack/JIRA/Custom Incident Action)」のCustom Incident Actionの部分で軽く触れましたが、こちらもGoogle Apps ScriptをWebアプリケーションとして公開し、doPost関数を実装するというやり方が一番簡単なのではないかと思います。スラッシュコマンドのRequest URLでGoogle Apps Scriptの公開URLを指定し、スクリプト内でChannel IDやUser IDをフィルタしてからPagerDutyのIncident Creation APIを利用するのが柔軟ではないでしょうか。
インシデントマネジメント
弊社ではDatadogによるサービスメトリックのモニタリング、Runscopeによる外形監視をメインのモニタリングツールとして使用し、即座に対応が必要なものについてはPagerDutyでインシデントをトリガーしています。そこで、インシデント発生時やその後の対応をどのように行っているかをご紹介します。
インシデント対応
開発担当者とSRE(Site Reliability Engineer)で一次対応を行いますが、インシデント対応専用のチャットルームを用意して「誰が何をするか」「結果どうだったか」などを逐次共有するようにしています。以前ご紹介したようにPagerDutyでもインシデントにNoteを書いていけるのですが、画像を貼り付けたりしたいこともよくあるし、コマンドの実行結果などが見やすいように弊社ではすべてチャットにしています。日中の勤務時間帯であれば1カ所に集まって口頭でやりとりしながら対応しますが、同時にチャットにも記録を残すようにしています。あとでインシデントリポートを作る際に必要になるからです。
インシデント用のチャットは、対応中はどんどん情報が流れていってしまうだけでなく、専門用語が飛び交うためにエンジニアでないと何が起きているのか把握することができません。そのため、エンジニアではないステークホルダーが情報を把握するため、別途ステータス共有チャンネルを作っています。
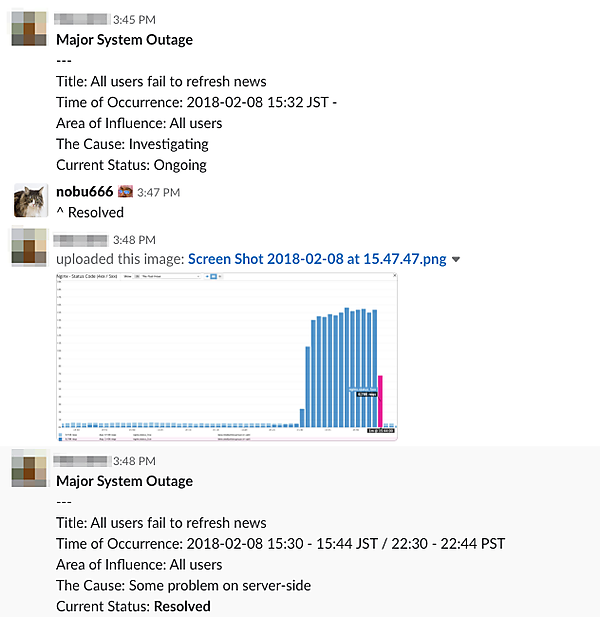
実際に手を動かして対応する人とは別に、コミュニケーションする人を分けることで対応者の負荷を減らしながら、正しく、かつ素早く情報共有ができるように工夫しています。
インシデントレポート
一次対応が終わったら、なるべく時間を開けずにレポートを作成しています。PagerDutyでもAnalyticsメニューのPostmortemsから作ることができます。PagerDutyのデフォルトのテンプレートは次のようになっています。
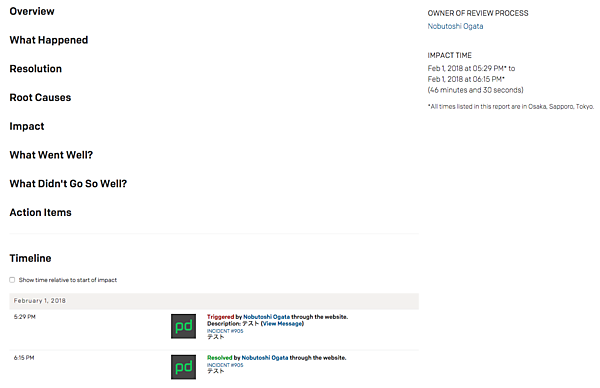
弊社でも項目はほとんど同じですが、インシデントレポートを作る負荷をなるべく下げるため以下の項目だけを必須項目として書いてもらっています。
- Description
- Area of Influence
- Timeline
もちろん最終的には根本原因や再発防止のためのAction Itemsもまとめるのですが、それは別途インシデントレビューというミーティングを設けて、そこで議論しながらまとめるようにしています。
インシデントレビュー
関係者を集めて30分から1時間程度でレビューを行います。「振り返り」「Postmortem」「Retrospective」などとも呼ばれます。ここで重要なのは、このレビューは誰かの責任を追求するものではないということです。主な目的は根本原因の究明、障害検知や対応プロセスの分析、再発防止のためのアクションアイテムの策定です。根本原因というのは「コードにバグがあった」などというものであってはいけません。コードレビューは行われていたのか、その観点はどのようなものであったか、テストのやり方はどうか、仕様の周知は十分だったか、などを議論して本当の根本原因を特定します。
また、アクションアイテムは必ず担当者を明示的に指名し、さらに期限を切ってタスク化します。インシデントレポートと関連付けて、実行状況を追跡可能な状態にしておくことで、結局根本対応されないまま放置されてしまうということが起きないよう、JIRAでダッシュボードを作って定期的に確認するようにしています。
まとめ
コンテナの監視、コーディングなしでのAPI利用例、インシデントマネジメントの事例についてご紹介させていただきました。インシデントマネジメントについては、各社様々なやり方があると思いますが、あくまでも「スマートニュースではこうしている」とい1つの例として、インシデントマネジメントを考える上での参考にしていただければと思います。
PagerDutyはインシデント管理だけでなくユーザーサポートなどにも応用可能なシステムですが、200種類近い各種ツールとの連携はここでは書ききれません。連携についての日本語の解説はこちらで参照できます。
- この記事のキーワード
この記事をシェアしてください
関連記事
モニタリングシステム連携とインシデントの抑制
2018年3月16日 10:07
NGINX Ingress Controllerの柔軟なアプリケーション制御、具体的なユースケースと設定方法を理解する
2021年9月22日 22:01
「kube-bench」でKubernetesクラスタのCISベンチマーク準拠を確認する
2025年7月2日 6:30
FirebaseプログラムをCompute Engineにディプロイする
2016年5月9日 8:40
CoreOS&Docker環境においてOracle Database 11g Release 2をインストールするためのポイント
2016年3月23日 12:09
RancherでKubernetesクラスタを作る
2019年3月13日 6:00
バックナンバー
この記事の筆者
筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
