PagerDutyのエスカレーションポリシーとサービス
連載2回目は、PagerDutyの概要と基本的な使い方について紹介していきます。今回からは実際にPagerDutyを実務で使用しているスマートニュース社の尾形さんに案内人をお願いします。
2018年3月2日 6:00
はじめに
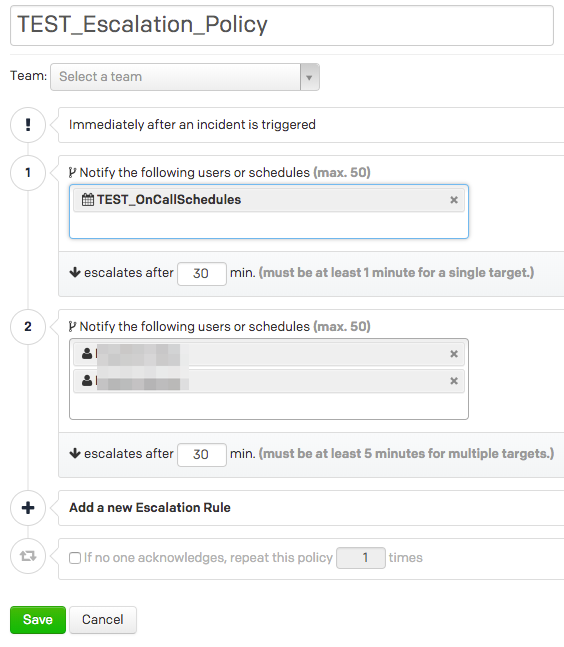
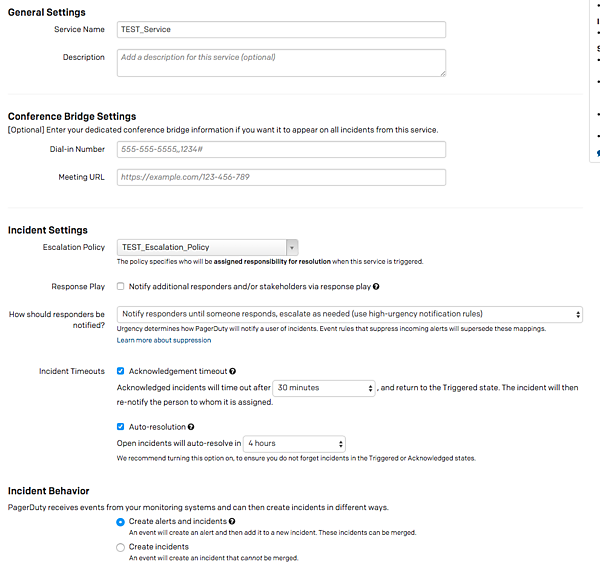
PagerDutyの利用を始めるにあたって、最低限エスカレーションポリシー(Escalation Policy)とサービス(Service)を設定する必要があります。
エスカレーションポリシーは、あるサービスに対するインシデントが発生した場合に、誰にどの順番で通知するかを定義するものです。サービスとはインシデントをアプリケーションやコンポーネントでカテゴリー分けするためのものになります。サービスには必ずエスカレーションポリシーが必要になります。またPagerDuty自体には監視機能はついておらず、インシデントを検知するにはNagiosやDatadogといった他のツールと連携する必要がありますが、その設定もサービス単位で行います。
エスカレーションポリシーの通知対象ユーザー欄で指定できるのはユーザーだけでなく、後述するスケジュールを設定することもできます。詳しくはエスカレーションの節で説明します。
インシデントの状態
PagerDutyのインシデントにはトリガード(Triggered)、確認(Acknowledged)、解決(Resolved)の3つの状態があり、まずはこれを理解する必要があります。
Triggered
現在有効なサービスでインシデントが発生した状態です。この状態になると、エスカレーションポリシーの設定に従って通知が行われます。 サービスにメンテナンスウィンドウが設定されていたり、サービス自体が無効化されている場合は、この状態にはなりません。
Acknowledged
誰かが該当インシデントの発生を確認し、対応を行っている状態です。Acknowledgedになるとサービスで設定されるAcknowledgement timeoutの時間が経過するまでは、再び通知が飛ぶことはありません。逆に言うと、この時間が経過するまでAcknowledgedのままだとTriggeredに戻ってしまい、再度通知が行われます。
Resolved
インシデントへの対応が完了した状態です。一度この状態になったインシデントは、再度通知が行われることはありませんし、ステータスを変えることもできません。
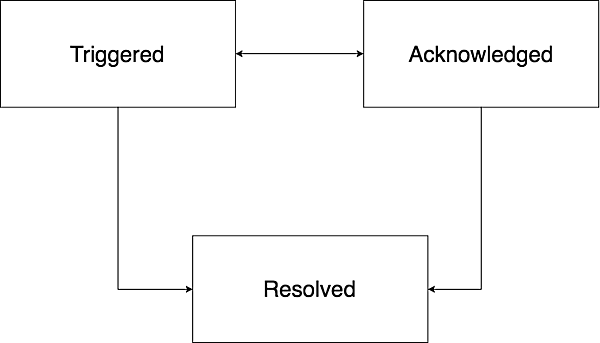
遷移としてはTriggeredから始まりResolvedで終わるのが基本で、TriggeredとAcknowledgedはどの状態へも遷移可能です。つまり、Triggered状態からAcknowledgedを経由せずにResolvedになることもあり得ます。例えば、一時的に高負荷になりインシデントがトリガーされたが、一瞬で収まったためすぐResolvedになるような場合です。
手動でインシデントを作成する
障害対応の訓練や、監視対象ではない部分での障害発生時などに、他のツールと連動せずに手動でインシデントを作成することもできます。PagerDutyにWebブラウザでログインすると右上にNew Incidentボタンがあり、そこから任意のサービスに対するインシデントを作成できます。特定のユーザーやエスカレーションポリシーを追加することもできます。設定してCreate Incidentを押すと即時インシデントが作成されて、Triggeredな状態になります。
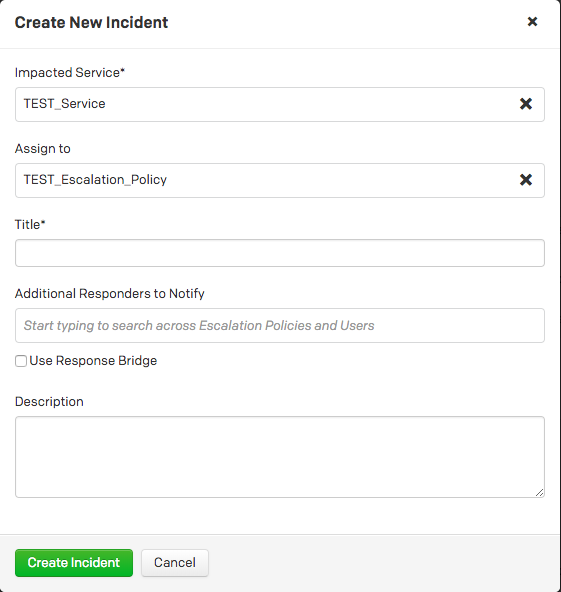
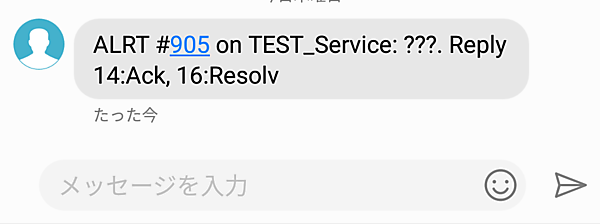
このときエスカレーションポリシーで設定したユーザーに通知が行きますが、通知の受け取り方はユーザーごとに自分で設定を変えることができます。My ProfileからNotification Rules画面へ行き、そこで通知の順序などを設定できます。選べるのはメール、電話、SMS、Push通知で、インシデント発生から分単位で時差をつけて通知を受けることができます。筆者はSMSでの受け取りを0分後(つまり即時)、電話での受け取りを1分後に設定しています。なおTitleは日本語対応していないため、もし日本語を使うと ??? と表示されてしまうため注意が必要です。
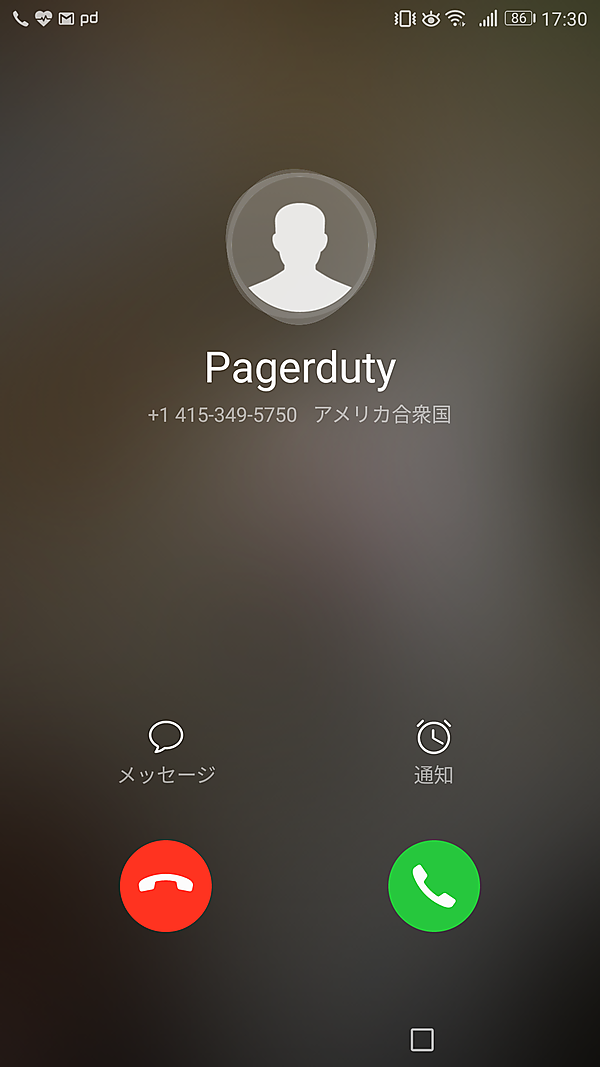
電話はサンフランシスコからかかってくる
電話はサンフランシスコからかかってきますのでびっくりしないように。Descriptionに書いたことを自動音声で読み上げてくれますが、こちらも残念ながら日本語には対応していません。かなり早口の英語で聞き取りやすいものではないため、あくまで通知のためだと割り切って使うのが良いのではないかと思います。電話に出て、テンキーから数字を入力することでAcknowledgedになります。電話に出ただけではAcknowledgedにはならないので注意が必要です。
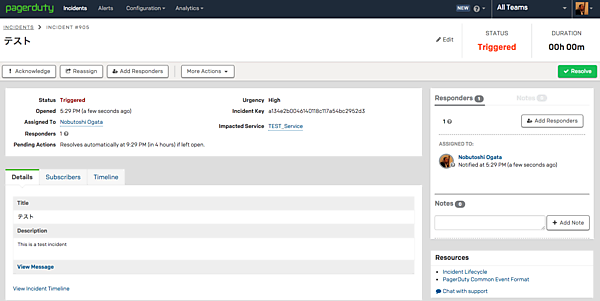
インシデントの通知を受け取ったら、まずは「自分が対応しますよ」ということを宣言します。これをAcknowledge(単にAckということもあります)といいます。Ackするとそのインシデントの状態がAcknowledgedに変わり、Ackした人と時間が記録されます。
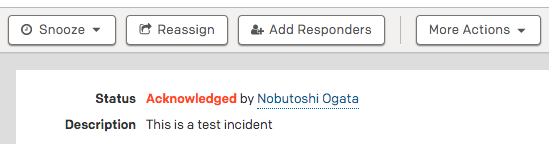
AckはSMSでも電話でも、あるいはWebからでも可能です。PagerDutyはiOSとAndroidのアプリもありますので、そちらを使うのもお勧めです。
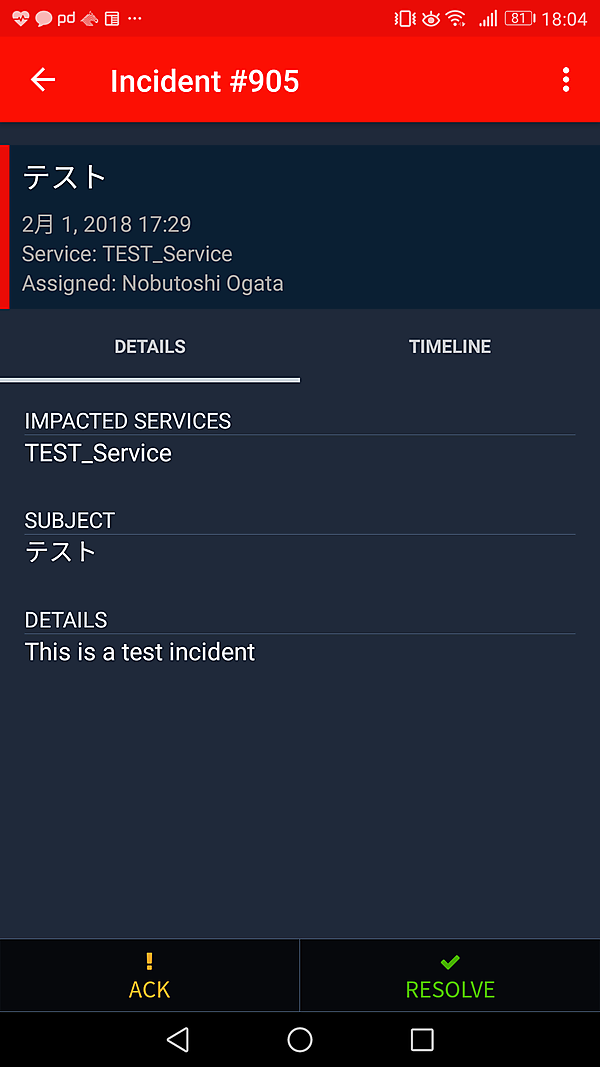
Ackしたら実際に対応を開始します。対応が終わったら、Ackと同様の方法でResolved状態にします。前述の通りAcknowledgement timeoutが設定されている場合、一定時間経過でまた通知が飛んでしまいます。対応が長引いている場合、Snooze機能を使って一定時間再通知を止めるといいでしょう。
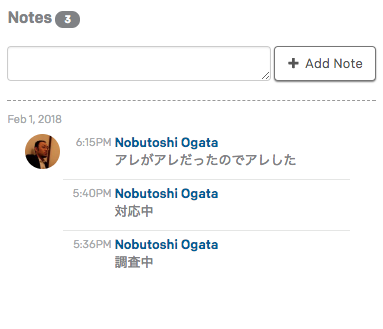
また、インシデント対応の状況を、Notesという機能を使って共有することができます。あとでポストモータム(Postmortem:インシデントの根本原因、一次対応の方法、根本的な対策などをまとめて振り返りをすること)の際に、何時何分に誰が何をしたのか、どういう状況なのかが一カ所にまとまっていると、とても便利です。
オンコールのスケジューリング
インシデント対応者を事前にスケジューリングし、オンコールローテーションを組むことができます。例として「日中4人の対応者が2日ごとにシフトに入り、それ以外の時間帯は3人が1日ごとにシフトに入る」という設定を組むとしましょう(実際にこんなローテーションが回るのかはともかく…)。
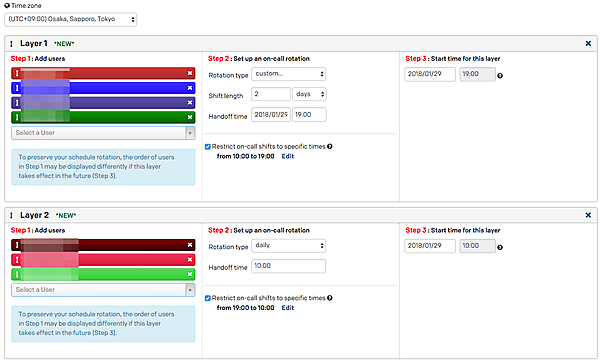
画面左側に担当者をリストアップし、中央でシフトの日にちと終了時間、右にこのシフトの開始日時を指定します。この例ですとLayer1が10時〜19時、Layer2が19時〜10時の設定になります。こうすると最終的にどうなるかというのが下の画面で確認することができます。色の帯は担当者と担当時間を表します。誰も担当者がいない時間帯というのがないことがわかります。
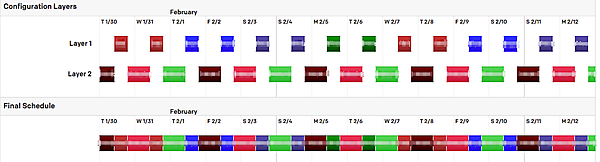
しっかりとしたオンコールローテーションを作成することで、今この時間の担当者は誰と誰なのかが明確になります。しかし何もかもが予定どおりに行くわけではありません。オンコール担当者が急に体調を崩したり休暇になったりすることもあります。そんな時のためにPagerDutyにはオーバーライド(Override)という機能が用意されています。この機能を使って一時的にスケジュールを上書きすることができます。
また作成したスケジュールはGoogle CalendarやiCal、Confluenceといった他のツールに取り込むことができるようになっています。これにより今日のオンコール担当は誰なのかということを簡単に共有することができます。
エスカレーション
通知を受け取る順番を設定するエスカレーションポリシーでは、通知を受けるユーザーを最大で20まで階層化することができます。1階層に入れることができるユーザー数は契約形態で違い、ライトとベーシックライセンスが10人まで、スタンダードとエンタープライズライセンスの場合は50人までですが、責任の所在が曖昧になったり混乱が起こりやすいという理由から、あまり多くの人を入れることは推奨されていません。また、ユーザーではなく先ほど設定したようなオンコールスケジュールを指定することもできます。1番上の階層に設定されたユーザーやスケジュールに対してまず通知が行きますが、指定時間内に反応がなかった(AcknowledgedやResolvedにならなかった)場合は、次の階層のユーザー、スケジュールへ自動的にエスカレーションされます。オンコールスケジュールを1次受けにし、2次受け以降に特定のユーザーを設定していくのが一般的な使い方ではないかと思います。
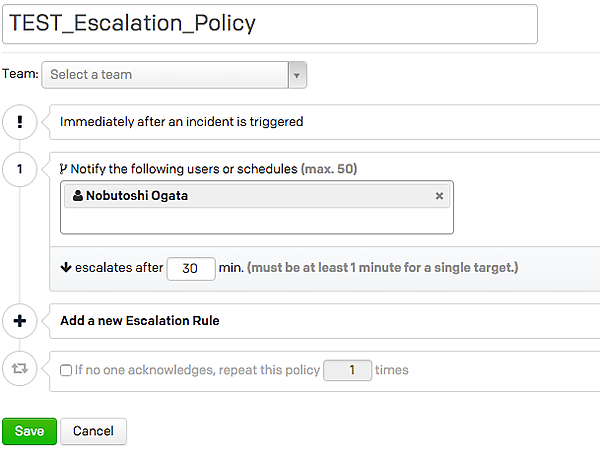
再アサイン
Acknowledgedにしたものの、自分だけでは問題を解決できないという場合もあり得ます。そういうときは再アサイン(Reassign)機能を使って手動でエスカレーションを起こすことができます。
これはエスカレーションポリシーに設定されていないユーザーに対しても使えます。特に深夜や休日に1人だけで行うインシデント対応はプレッシャーがかかります。自分で判断がつかない場合は、専門家へエスカレーションして助けてもらいましょう。よくわからないまま余計なことをして、二次災害を引き起こさないことが重要です。
- この記事のキーワード
この記事をシェアしてください
バックナンバー
この記事の筆者
筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
