インシデント管理とは?
なんでもかんでもWebサービスなしでは動かない現代、24x7でのサーバ運用が当たり前になって久しくなります。絶対落ちないシステムはありえないのに、求められるのはダウンタイムゼロ。ただでさえエンジニア不足がひどい昨今ですが、運用担当者の負担は増えるばかりです。
DevOpsでのアジャイル開発で、できるだけ早くサービスを投入しようという流れの中、どうしても完璧なテストを実行するのが難しくなってきており、バグ発生の頻度も高くなる傾向にあります。
加えて、最近はオンプレミスとクラウド、プライベートクラウドとパブリッククラウドのハイブリッド運用が急増し、サーバ構成もたくさんのマイクロサービスを組み合わせる構造となるなど、非常に複雑化しています。
当然、それぞれのインフラ、サ―ビスにはNagios、Zabbix、Mackerelなどの障害検知、運用監視ツールが組み込まれています。どの監視ツールを使うかはOS、監視対象サービス、監視ルールの内容、担当エンジニアの好みなどにも左右されて、1つの大きなシステムに複数の監視ツールが使われていることもままあります。
この状態で何か大きな不具合が生じると、色々な監視ツールからのアラートが別々に発せられて、運用エンジニアにメールが届くことになります。大きなシステムでは運用エンジニアは複数いるでしょうから、誰がどう対応すべきか、すでに対応済みなのかなど、現場は大混乱になりかねません。
そこで、色々な監視ツールから送られるアラートを1カ所で集約して管理できるようにするのがインシデント管理ソリューションです。ちなみにインシデントとはシステムダウンやアプリケーションのバグ、パフォーマンスの低下などの兆候が一定基準を超えた際に監視ツールから発せられるアラートをもとに、対応すべき事態としてインシデント管理サービスが認定、生成する状況のことです。
インシデント管理ソリューションとしてはWaker、VictorOps、PagerDutyなどいくつかありますが、今回はその中でも機能の高いPagerDutyをご紹介します。
PagerDutyでできること
今回紹介するインシデント管理サービスPagerDutyには次のような機能があります。
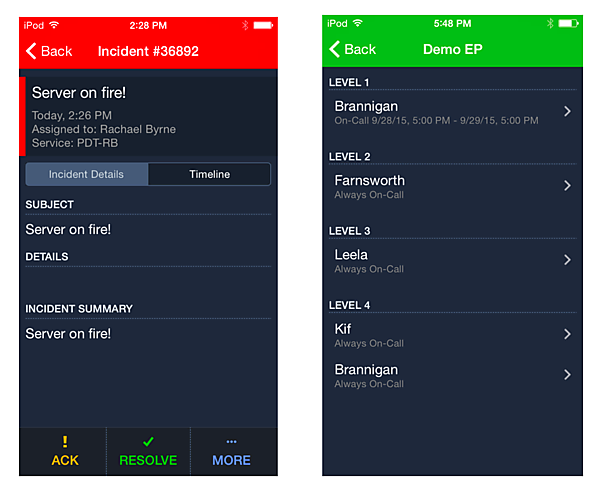
- 複数のアラートを集約して担当者に通知する。もし担当者が決められた時間以内に通知確認をしなければ、あらかじめ決められた順番で他の担当者に通知する(エスカレーション)。通知の手段は音声電話、SMS、Slackなどのチャット、メールなど、インシデントの重要度に従って設定できる。インシデントの重要度はあらかじめ閾値を決めておく。
- 簡単に連携できる監視ツールは200種類、REST APIでのアラートも受け付ける。1つのインシデントについてたくさんのアラートが発せられても、それらをグループ化し、抑制することにより「アラートの嵐」を避けることができる。監視ツールごとに違うアラートのフォーマットを正規化することも可能。
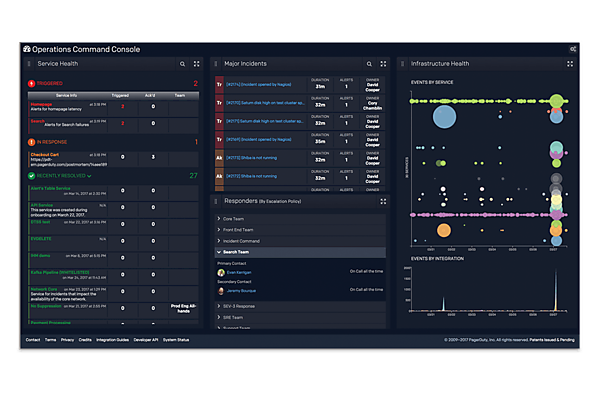
- インシデントの状況を対応チーム全員がダッシュボードで確認できる。メールベースのレポートでは混乱が避けられないが、ダッシュボードならリアルタイムで状況が確認できる。ユーザーサポートや営業部門などのエンジニア以外のメンバーも閲覧できる。モバイル端末での確認、サーバのリブートなどもできる。
- チャットサービスとの連携やWeb会議などでチームでコミュニケーションをとりながら対応に当たることができる。
- インシデント対応をあらかじめワークフロー化しておける。これにより素早く間違いのない障害対応が可能になる。
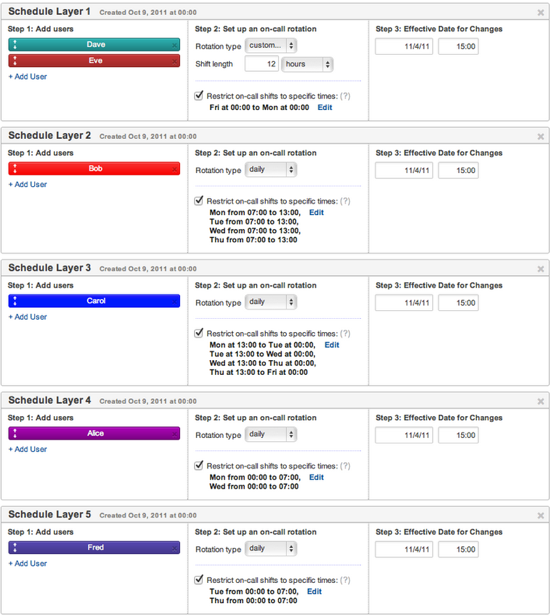
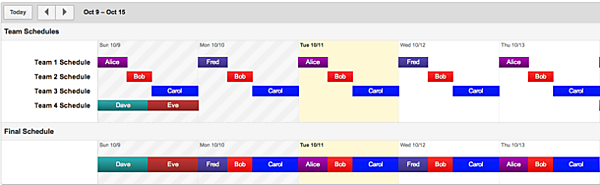
- オンコールエンジニアのスケジューリングを簡単に行える。時間、曜日、週などでのローテーションをビジュアルに組むことができ、突発的な変更にも素早く対処できる。時差を考慮したグローバルなサービスにも対応。
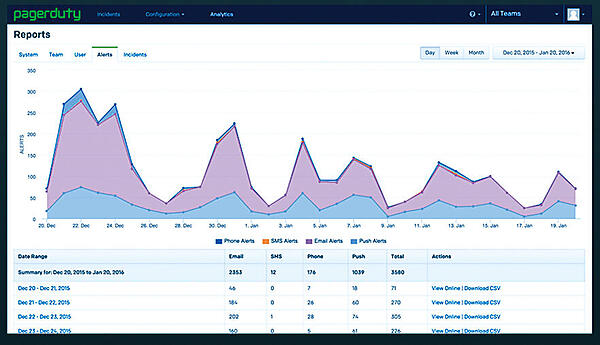
- システムのヘルスレポート、チーム、スタッフの負荷などを表示。
- インシデント解決後のレポート作成機能により、将来のインシデントに備えることができる。

インシデント管理サービス導入のメリット
このように、PagerDutyは高い機能を持っていますが、導入のメリットとしては以下のようことが考えられます。
- 確実かつ迅速なインシデント対応ができるため、ダウンタイムによる損失を防ぎユーザーエクスペリエンスを向上できる。
- オンコールエンジニアが合理的なローテーションで勤務できるため、働き方改革が実現できる。その結果として、エンジニアの福祉のほかに人手不足の折のエンジニア引き止め、新規募集への効果も期待できる。
- NOC(Network Operation Center)など、アラート管理の外注化から自社運用に切り替えることによるコストダウン。
ここまでをまとめると、次のようになります。
| 旧世代のインシデント対応 | デジタル化したインシデント対応 | |
|---|---|---|
| アラート処理 | たくさんの監視ツールからのアラートメールがバラバラに届く。それぞれの監視ツールの画面で確認 | 1つのダッシュボードで全てのインシデントを確認、対応できる。対応する必要のないアラート、重複したアラートはグループ化、抑制する |
| エンジニアの呼び出し | 担当者がスプレッドシートなどで担当者を確認し電話連絡する。エスカレーションは手動 | アラートはスケジュールに従って自動的に担当者に通知される。エスカレーションは自動的に行われる。インシデントの種類によって呼び出すエンジニアを変えたりと、ワークフローを設定できる |
| エンジニアのスケジューリング | スケジュールはスプレッドシートなどで管理。作業が煩雑で間違いが起きやすい。スケジュール変更も大変 | Web画面上で簡単にスケジューリングができる。変更も容易。チームメンバーはいつでもスケジュールを閲覧できる |
| 組織全体への対処 | ユーザーサポートや営業関係者へのレポートは手動で事後になる | エンジニア以外のメンバーも事態の推移をリアルタイムで確認できる |
以上、駆け足でPagerDutyの概要をご説明しました。連載の2回以降では色々な機能を具体的に解説する予定です。ご期待ください。
PagerDutyは世界の約1万社で使われており、日本になじみのあるところとしては、巨大なデータベースシステムを構築してビッグデータの利用基盤を提供するTreasure Data(https://www.treasuredata.co.jp/)がある。PagerDutyとFluentdや Datadog、Google Duo、Slackなどと連携したシステムでインシデント発生に対処している。開発リソースは自社のコアビジネスに特化して、インシデント管理などのコア以外は他社サービスを積極的に活用するという同社のポリシーに従った選択と言えるでしょう。
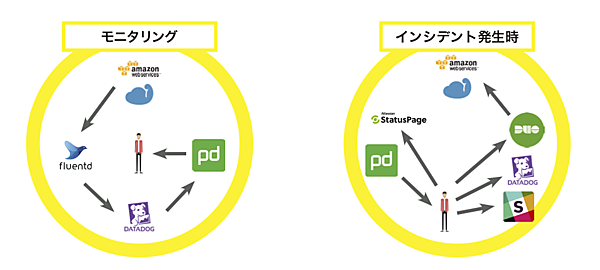
Treasure Dataのシステムでは、クラウドのデータベースのログをFluentdで収集し、Datadogがそのデータからサーバやアプリケーションの状態を示す指標を抽出し、あるレベルを超えるとPagerDutyにアラートを発する。
それを受けたPagerDutyは運用担当者に通知し、担当者はDatadogで何が起きているかを調べ、Slackなどでスタッフに伝えて対応する。AmazonへのログインはGoogle Duoの2段階認証を使い。ビッグデータを預けている顧客はStatusPageでいつでもシステム状況を確認できる。
- この記事のキーワード
この記事をシェアしてください
関連記事
PagerDutyのエスカレーションポリシーとサービス
2018年3月2日 6:00
PagerDutyのアプリ連携(Slack/JIRA/Custom Incident Action)
2018年3月30日 15:54
Dockerコンテナの監視を行うサービス
2016年1月25日 16:10
「AWS Cost Explorer」と「AWS Budgets」でインフラのコストを管理しよう
4月21日 6:30
CloudNative Days Tokyo 2023から、Yahoo! JAPANを支えるKaaS運用の安定化やトイル削減の取り組みを紹介
2024年3月11日 6:00
「AWS Budgets」のアラートをSlackに通知する仕組みを構築してみよう
5月19日 6:30
バックナンバー
この記事の筆者
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
