はじめに
Kubernetesではv1.13でCSI(Container Storage Interface)がGAとなり、ストレージの新機能はCSIで提供されるようになりました。
そこで今回は、CSIとCSIによって提供されているKubernetesにおけるストレージ機能について紹介します。
CSIとは
CSIは、コンテナオーケストレーション向けのストレージインターフェースとして2017年に最初のバージョンがリリースされました。
CSIが登場する以前は、Kubernetesのストレージ関連の実装はin-treeと呼ばれるKubernetes自身のソースコードに直接実装されていました。そのため、ストレージ機能を実装するストレージベンダ等は、Kubernetesのソースコードへアップストリームする必要がありました。
これがCSIの登場でストレージ関連をPlugin化したことにより、ストレージベンダ等が自由に開発しリリースができるようになりました。このCSIはKubernete v1.9でAlphaサポートとなり、v1.13でGAとなっています。将来のバージョンではin-treeのストレージ関連の実装は削除され、全てCSIへ移行される予定です。
そのため、Kubernetesで登場してきているストレージの新機能は全てCSIにて実装されています。代表的な機能を表に示します。
| 名前 | ステータス | Kubernetesの サポートバージョン | 内容 |
|---|---|---|---|
| Volume Expansion | Beta | 1.16以降 | Volumeのサイズ拡張 |
| Raw Block Volume | Beta | 1.14以降 | File SystemでフォーマットしていないVolume |
| Volume Cloning | GA | 1.18以降 | Volumeのクローン(コピー) |
| Volume Snapshot&Restore | Beta | 1.17以降 | VolumeのSnapshotとRestore |
| Topology | GA | 1.17以降 | AZなどのトポロジー指定 |
※この機能は、2020年6月時点での状況です(参照元:Kubernetes CSI Developer Document)。
以降では、この中から代表的な機能について紹介していきます。
Volume Expansion
最初に紹介する機能は、PVC(PersistentVolumeClaim)/PV(PersistentVolume)のサイズを拡張するVolume Expansionです。
まず、以下のManifestを使って10GのサイズのPVCを作成したとします。PVはDynamic Volume Provisioningにて、自動的に生成されているものとします。
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc1
spec:
storageClassName: standard
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
作成した当初は10Gのサイズで良かったPVC/PVも、利用し続けていくとサイズ不足になる場合もあります。Volume Expansionでは、.spec.resources.requests.storageの値を変更することでPVC/PVのサイズを拡張できます。ただし、縮小はサポートしていません。
$ kubectl patch pvc pvc1 -p "{\"spec\":{\"resources\":{\"requests\":{\"storage\": \"15Gi\"}}}}"なお、Volume ExpansionにはPodにマウントしたままでも拡張できるOnlineとPodを一度削除する必要のあるOfflineがあります。どちらをサポートしているかは利用するストレージ次第なので、詳細は利用するストレージのドキュメントをご参照ください。
Raw Block Volume
次に紹介する機能は、File SystemのフォーマットをしていないVolumeであるRaw Block Volumeです。上記のPVC(pvc1)のManifestを改良し、Raw Block Volumeを生成するManifestを以下に示します。
@@ -6,6 +6,7 @@ spec:
storageClassName: standard
accessModes:
- ReadWriteOnce
+ volumeMode: Block
resources:
requests:
storage: 10Gi
.spec.volumeModeにBlockを設定したPVCのManifestをデプロイすることで、Raw Block Volumeを作成できます。
注意点したいのは、Raw Block VolumeはFile Systemでフォーマットされていないことです。そのため、通常のVolume(フォーマットされたVolume)のようにマウントできません。
DBMSによっては独自のFile Systemを特徴としたものがあり、Raw Block Volumeが使われます。理由はFile SystemのジャーナルログなどによりI/Oパフォーマンスを落とさないようにするなど様々です。
2020年現在では、SSDやNVMeの進化により従来のFile System(XFS、ext4など)を介さずにI/Oを処理する技術も登場してきています。これらを使うことで、I/O性能をチューニングしたい場合の選択肢としてもRaw Block Volumeを利用できます。
Volume Cloning
3つ目に紹介する機能は、PVC/PVのクローン(コピー)を作成するVolume Cloningです(図1)。Volume CloningではPVCの.spec.dataSourceにクローン元のPVCを指定して作成します。
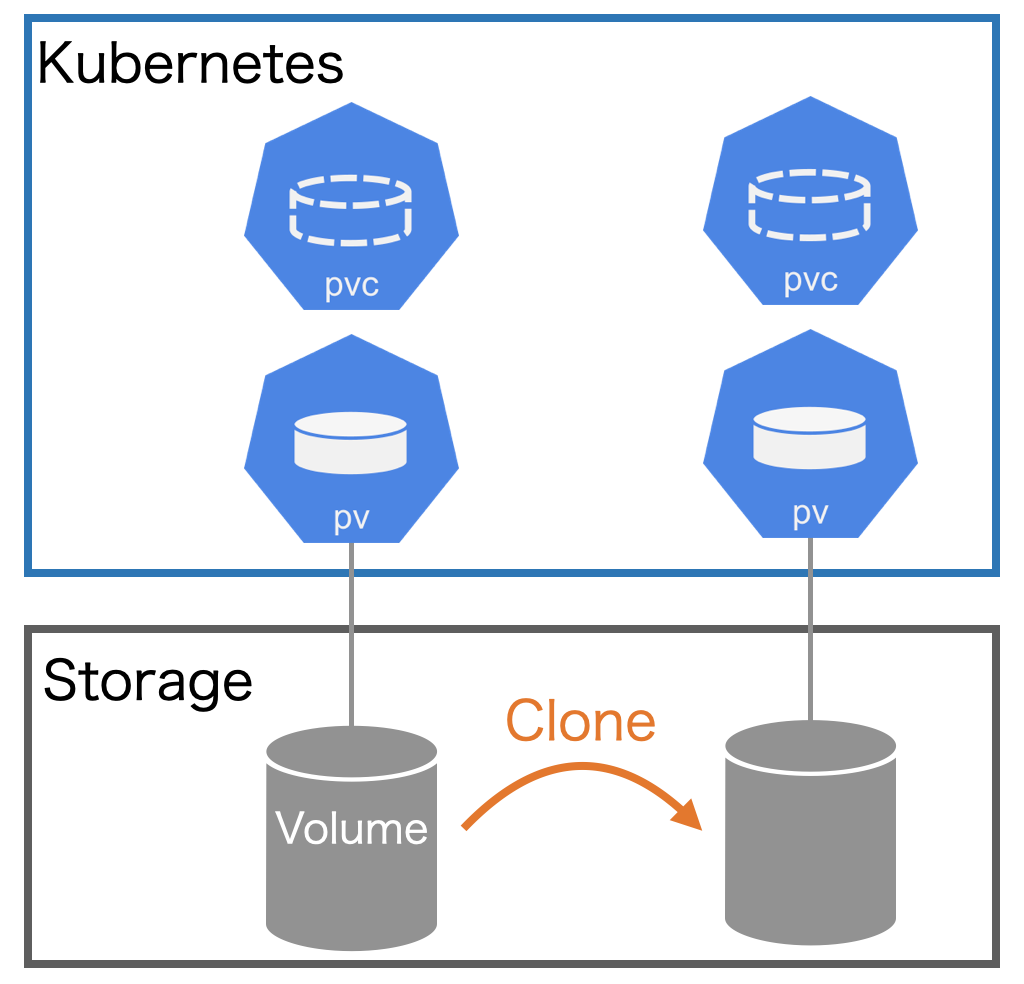
図1:Volume Clone
以下に、PVC(pvc1)のクローンであるPVC(clone-of-pvc1)のManifestの例を示します。
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: clone-of-pvc1
spec:
accessModes:
- ReadWriteOnce
storageClassName: standard
resources:
requests:
storage: 10Gi
dataSource:
kind: PersistentVolumeClaim
name: pvc1
これにより、ストレージのコピー機能を使ってPVC(pvc1)のVolumeをクローンしたVolumeがPVC(clone-of-pvc1)として生成されます。
Volume Cloningのメリットは、ストレージのコピー機能を使うことで、KubernetesのノードのCPU/Memory/Networkの負荷を軽減できることです。巨大なデータが格納されたVolumeをコピーしたい場合に便利です。
注意点としては、必ずクローン元のPVC(pvc1)のサイズ以上のサイズを.spec.resources.requests.storageに指定する必要があることです。
Volume Snapshot & Restore
続いて紹介する機能は、実行した時点のデータを保持するVolume Snapshotです。Volume Snapshotでは、新たに追加された以下の3つのリソースを利用します。これらのリソースは、CRD(Custom Resource Definition)により定義されています。
- VolumeSnapshot
Snapshotの要求仕様 - VolumeSnapshotContent
Snapshotのコンテンツ(変更差分) - VolumeSnapshotClass
Snapshot用のStoragePool(Snapshotのコンテンツの格納領域)
また、Volume Snapshotを利用するには、上記以外にSnapshotを処理するコントローラ(snapshot-controller)をセットアップする必要があります。snapshot-controllerのセットアップは利用するストレージにより異なるため、利用するストレージのドキュメントをご参照ください。
Volume Snapshotは、VolumeSnapshotのリソースを作成することで、その時点のデータのSnapshotを取得できます(図2)。
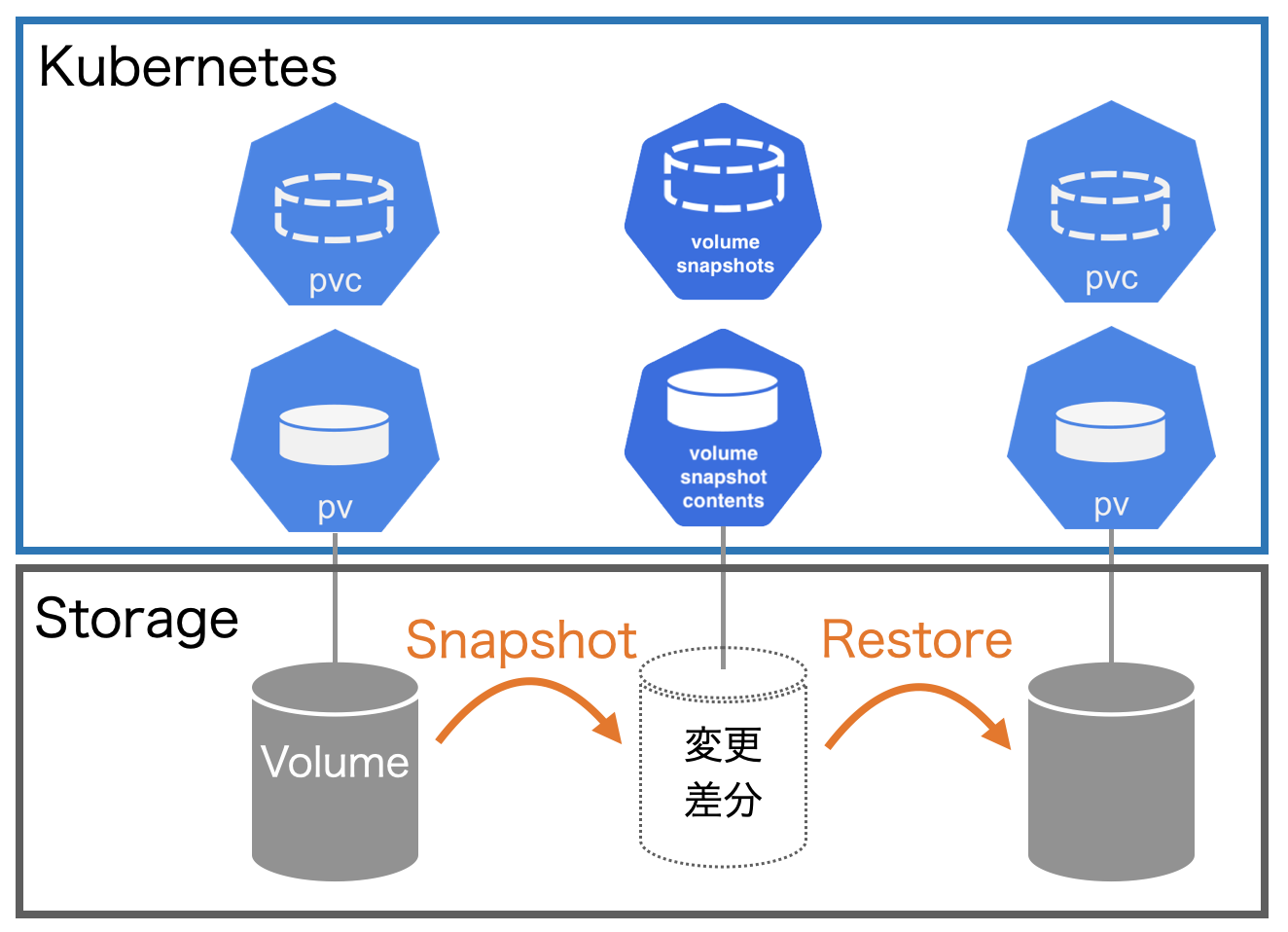
図2:Volume Snapshot
以下に、VolumeSnapshotのManifestの例を示します。
apiVersion: snapshot.storage.k8s.io/v1beta1
kind: VolumeSnapshot
metadata:
name: snapshot-pvc1-202006221300
spec:
volumeSnapshotClassName: csi-snapshot
source:
persistentVolumeClaimName: pvc1
.spec.volumeSnapshotClassNameには、使用するVolumeSnapshotClassの名前を指定します。.spec.source.persistentVolumeClaimNameには、Snapshot対象のPVCの名前を指定します。VolumeSnapshotのManifestをデプロイすると、VolumeSnapshotと共にVolumeSnapshotContentのリソースが生成されます。
VolumeSnapshotContentは、Snapshotにより作成された変更差分(コンテンツ)の格納場所の情報を持っています。また、VolumeSnapshotとVolumeSnapshotContentはreadyToUseとrestoreSizeを持っています。
readyToUseは、Snapshotがリストア可能かを示します。値が`true`の場合にリストアが可能です。restoreSizeはリストアする時のサイズを示します。
以下に、リストア時に利用するMainfestを示します。
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-from-snapshot
spec:
accessModes:
- ReadWriteOnce
storageClassName: standard
resources:
requests:
storage: 10Gi
dataSource:
apiGroup: snapshot.storage.k8s.io
kind: VolumeSnapshot
name: snapshot-pvc1-202006221300
リストアでは、restoreSizeで示されたリストア時のサイズをPVCの.spec.resources.requests.storageに指定します。.spac.dataSourceにはリストアしたいVolumeSnapshotのリソースを指定します。
これらを指定したPVCのManifestをデプロイすることで、VolumeSnapshotのリソースが作成された時点のデータをリストアしたPVC/PVが生成されます。
Volume Snapshotのメリットは、実際に更新されたデータの変更差分のみが保存されるため、消費容量を抑えたバックアップができる点です。ただし、元のVolumeに障害が発生した場合には利用できなくなるため注意が必要です。
Topology
最後に紹介する機能はTopologyです。Kubernetesではv1.18でPod Topology Spread Constraintsが登場しました。これにより、AZ(Availability Zone:電源や空調などに障害が発生した場合でもサービス継続できるように設計された区画)を意識したPodの分散配置が可能になります。
ただし、PodがいくらAZを意識し分散配置しても、PVC/PVの実態であるストレージのVolumeもAZを意識し分散配置しなければ片手落ちとなります。図3の左図にストレージでのAZを考慮しない場合、右図にストレージもAZを考慮した場合について示します。
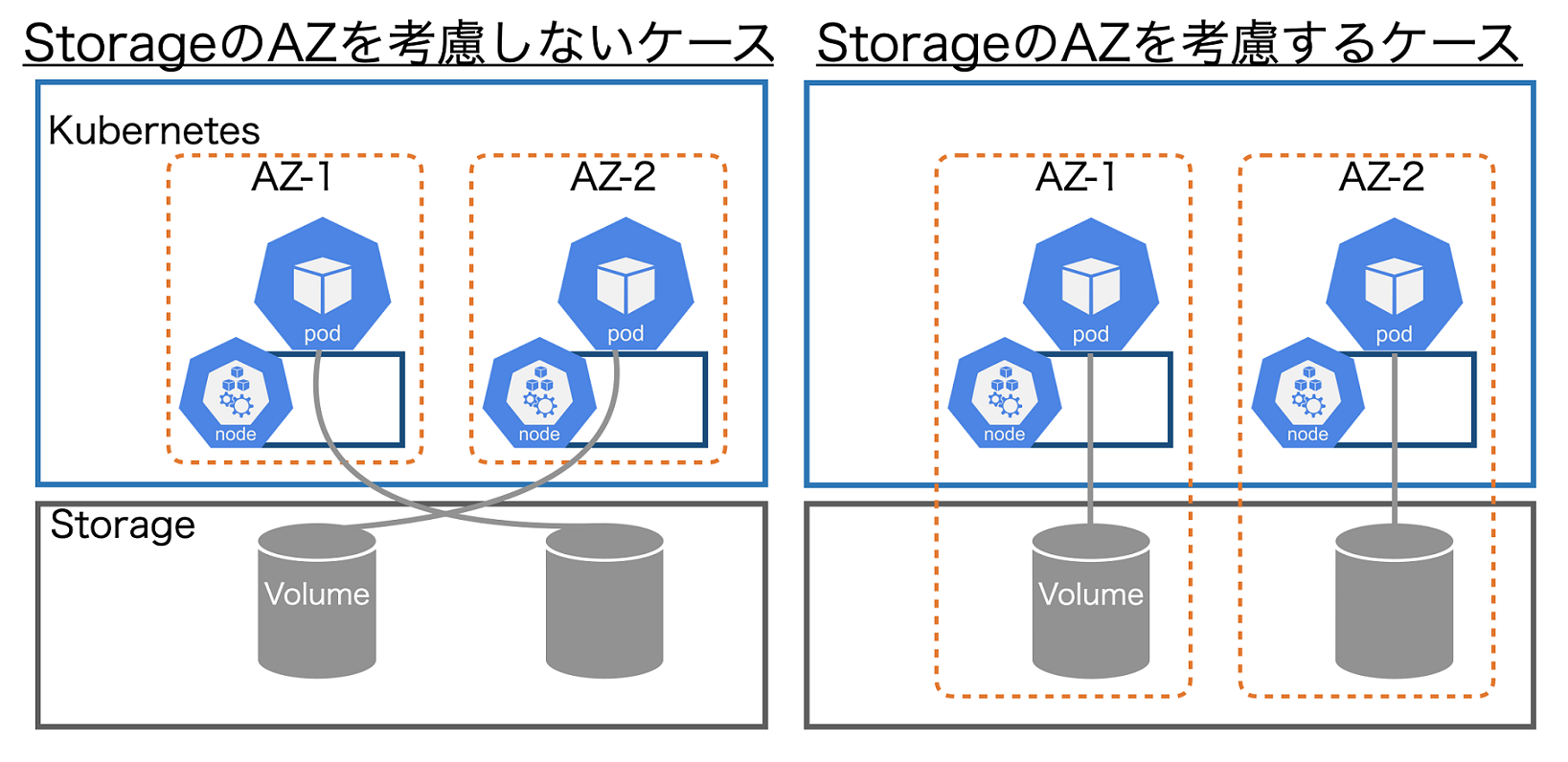
図3:StorageのAZ対応
図3の左図で示すように、ストレージのAZを意識せずにデプロイした場合、VolumeはどのAZに作成されるか分かりません。例えば、AZ-1のPodがAZ-2のVolumeを、AZ-2のPodがAZ-1のVolumeを各々マウントすることもあります。
本来は、電源障害などでAZ-1がダウンした場合、AZ-2のPodで継続動作して欲しいところです。しかし、マウントしているVolumeがAZ-1にいるため、全てのPodがダウンしてサービスが停止してしまいます。
このような事態を防ぐため、図3の右図に示したようにPVC/PVで作成されるVolumeも配置先を指定できるようになりました。それがTopology機能です。この機能はStorageClassにVolume作成先のAZの情報を設定することで実現しています。
ただし、注意点したいはTopologyが必要なインフラと不要なインフラが存在することです。多くのエンタープライズのストレージはDR(Disaster Recovery)と呼ばれる障害対策用にストレージ筐体間のミラー機能などを備えています。これらの機能で保護されているインフラの場合、Topologyをあえて設定しなくてもミラー機能によりAZの切り替えが行われます。
また、SDS(Software Defined Storage)では、各AZに配置された複数サーバへデータを分散配置するものもあります。
一方で、多くのパブリッククラウドには、デフォルトでこのような機能は設定されていません。利用するKubernetesのインフラを確認したうえで、安全なTopologyの設計をしてください。ここでは、Topologyの設定方法については割愛しますが、興味のある方は筆者が検証した以下のレポートをご参照ください。
【参考】Kubernetes: Topology Awareなデプロイの検証
おわりに
今回は、CSIと代表的なストレージ機能について紹介しました。CSIの登場で多くのストレージベンダ等からCSI Driverが提供され始めてきたことで、従来ストレージが持っていた機能をKubernetesでも利用できるようになってきました。
さらに、これまでベンダや機種ごとに違っていたストレージの操作も、Kubernetesの抽象化モデルから利用できるようになりました。これらにより、Kubernetesにおけるストレージ機能の活用について敷居が下がってきたと言えるでしょう。
Kubernetes上でステートフルアプリケーションを安全かつ便利に使うためにも、今回紹介したストレージ機能を使ってみてはいかがでしょうか。
- この記事のキーワード
この記事をシェアしてください
関連記事
詳解KubernetesにおけるPersistentVolume
2020年4月22日 6:30
StatefulSetとPersistentVolumeを使ってステートフルアプリケーションを動かす
2021年7月16日 6:30
Oracle Cloud Hangout Cafe Season7 #1「Kubnernetes 超入門」(2023年6月7日開催)
2023年12月14日 6:30
OpenShift:アプリケーションの構成と運用
2019年3月28日 6:00

坂下 幸徳(さかした・ゆきのり)
CNDT2020シリーズ:サイボウズのSREが語る分散ストレージの配置問題を解決するTopoLVMとは
2021年1月13日 17:17
バックナンバー
この記事の筆者

Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
