詳解KubernetesにおけるPersistentVolume
2020年4月22日 6:30
はじめに
コンテナはデータを持つアプリケーション(ステートフルアプリケーション)には不向きと言われてきました。しかし、Kubernetesの進化に伴い、ステートフルアプリケーションも動作できるようになってきました。
そこで本記事では、ステートフルアプリケーションをKubernetesで動作させるために重要となるストレージについて解説します。
ストレージのモデル
Kubernetesは、データを永続化するためのストレージを抽象度の高いモデルで表現しています。これにより、ユーザはストレージの詳細を知らなくても、Pod内のコンテナにボリュームを割り当てて使うことができます。
PersistentVolumeClaim, PersistentVolume, StorageClass
Kubernetesではストレージの基本モデルとして、次の3つのリソースがあります。
- PersistnetVolumeClaim(ショートネーム:pvc)
ユーザがボリュームを作成する際に利用する要求仕様を表すリソース - PersistentVolume(ショートネーム:pv)
ボリュームを示すリソース - StorageClass(ショートネーム:sc)
ボリュームの生成元となるストレージを示すリソース
StorageClassは、ストレージと通信をするためのProvisionerを備えています。このProvisionerを通じて、ストレージにボリューム(PersistentVolumeの実体)の作成・削除などの命令を実行します。
リソースの範囲と権限
Kubernetesでは、管理者とユーザの役割を考慮してストレージのモデルが設計されています。
- 管理者のみが扱えるリソース: PersistentVolume, StorageClass
- ユーザが扱えるリソース: PersistentVolumeClaim
PersistentVolume、StorageClassは全てのネームスペースで共有のリソースとなります。kubectlコマンドでそれぞれのリソースを確認すると、PersistentVoulmeとStorageClassは全てのネームスペースの共有リソースとなっています。
PersistentVolumeClaimのみがネームスペースごとのリソース(Namespaced)です。

そのため、PersistntVolumeとStorageClassについては、ClusterRoleとバインディングされたアカウントのみが操作可能です。つまり、管理者のみが操作できるリソースというわけです。
一方で、PersistentVolumeClaimはネームスペースごとのリソースであり、ユーザが操作できます。
ボリュームの提供方法
Kubernetesでは、ユーザへのボリュームの提供方法として2つの方法があります。Manual Volume ProvisioningとDynamic Volume Provisioninです。
●Manual Volume Provisioning
管理者が事前にPersistentVolumeとStorageClassを作成します。ストレージによっては、StorageClassが不要な場合もあります。
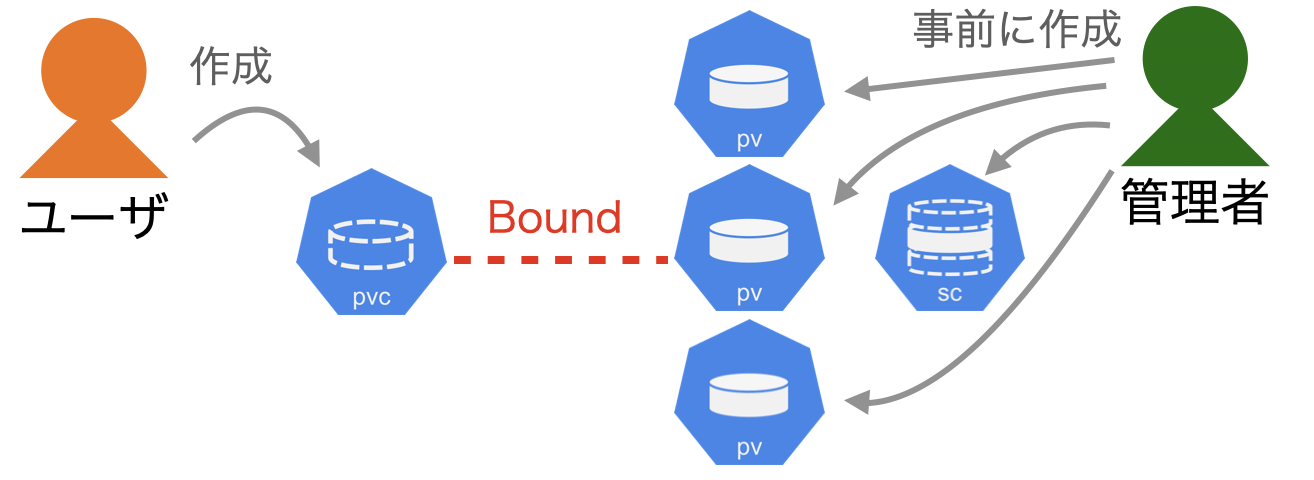
図1:Manual Volume Provisioning
●Dynamic Volume Provisioning
管理者はPersistentVolumeを作成しません。StorageClassのみ事前に作成します。
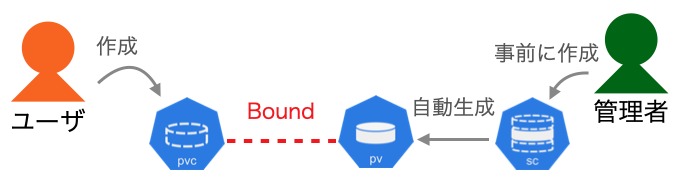
図2:Dynamic Volume Provisioning
このように、Dynamic Volume Provisioningはユーザのリクエスト毎にPersistentVolumeを事前準備する必要がないため、管理者の負荷が小さいです。
さらに、ユーザは必要な時に必要なサイズのボリュームをオンデマンドで作成できるメリットがあります。デメリットとしては、管理者が意図せずに、ユーザがストレージを無駄に使い過ぎてしまう点です。
管理者は、ユーザが使い過ぎないようにStorage Resouce Quotaなどを設定しておくと良いでしょう。
アーキテクチャ
次に、障害発生時や性能のチューニングをする際に必要な知識となるアーキテクチャについて解説します。
コンテナへのボリュームのマウント
ブロックストレージ(iSCSI)を例に、ストレージのボリュームがPod内のコンテナにマウントされるまでのアーキテクチャは下図のようになります。
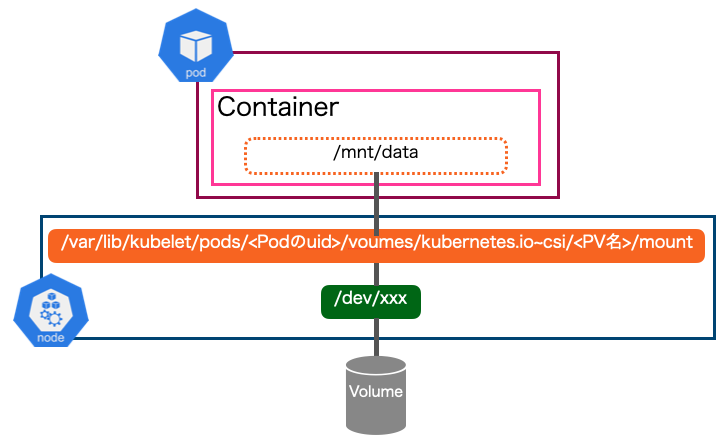
図3:Pod内のコンテナからストレージのボリュームへのパス
まず、Podが作成されると、ストレージのボリュームがNodeのデバイスファイル(/dev/xxx)にアタッチされます。その後、このデバイスファイルは/var/lib/kubelet/pods/<Podのuid>/voumes/kubernetes.io~csi/<PV名>/mountディレクトリにマウントされます。
この/var/lib/kubeletディレクトリ配下はKubernetesのコンポーネントのひとつであるKubeletによって管理されています。/var/lib/kubelet/pods/<Podのuid>/voumes/kubernetes.io~csi/<PV名>/mountディレクトリはPod内でVolumeとして扱われ、コンテナの任意のディレクトリ(上図では/mnt/data)にマウントされます。
このPod内のコンテナからストレージへのパスについて理解しておくことは重要です。例えば、PersistentVolumeClaim、PersistentVolumeは正しく作成されているが、ボリュームはコンテナにマウントされない障害が発生したとします。この場合、ストレージにはボリュームが作成されていても、Pod内のコンテナからボリュームまでの間で正しくマウントされていない可能性があります。
これを調査するには、Podのログなどを調べても原因の追求は困難でしょう。このケースでは、NodeのOSが出力するマウント関連を含んでいるシステムのログとKubeletのログを調査すると良いでしょう。
Node間移動
続いて、PodがNodeを移動する場合の動作を解説します。Kubernetesでは、Node障害やローリングアップデートなどにより、PodがNodeを移動する場合があります。
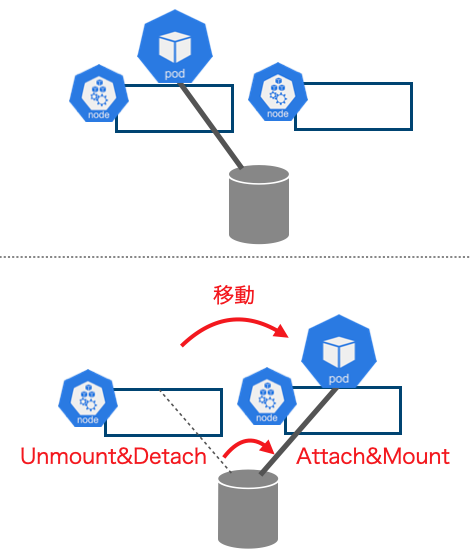
図4:PersistentVolumeのNode切り替え
PodがNodeを移動する場合、移動元のNodeにてボリュームのアンマウント&デタッチが行われ、Nodeからボリュームが外れます。次に、移動先のNodeにてアタッチ&マウントが行われます。
このように動作することで、ボリューム上のデータを削除することなく、Node間をPodが移動します。
ベアメタル・VMとの比較
ここまで、Kubernetesでストレージがどのように扱われているかを解説しました。ここまでの内容を理解したうえで、読者のなかにはステートフルアプリケーションをデプロイするインフラは、何が良いのか悩む人もいるでしょう。
そこで、インフラとして利用されるベアメタル・コンテナ(Kubernetes)・VM(パススルー)・VM(仮想ディスク)のアーキテクチャを比較します。
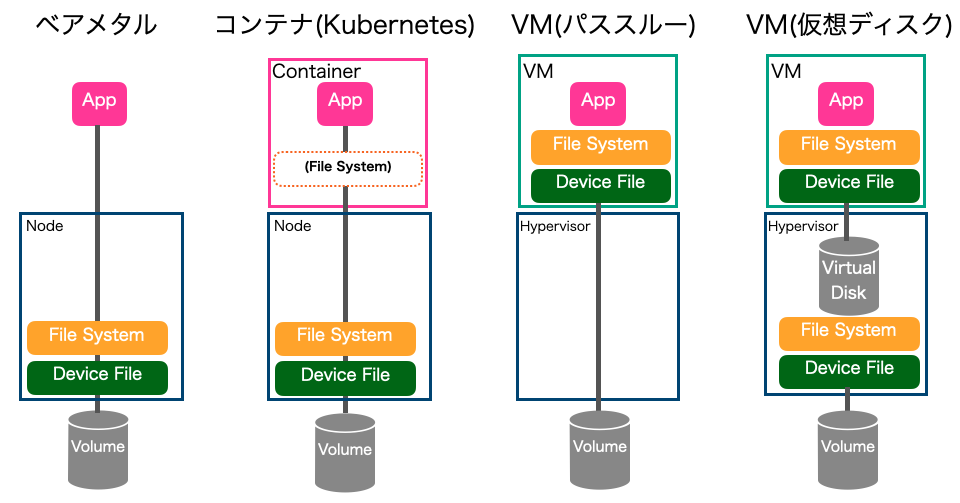
図5:ベアメタル・コンテナ・VMのアーキテクチャ比較(ストレージ)
| 比較項目 | ベアメタル | コンテナ (Kubernetes) | VM (パススルー) | VM (仮想ディスク) |
|---|---|---|---|---|
| シンプルさ | ◯ | △ | ◯ | × |
| 移動の容易さ | × | ◯ | × | △ |
コンテナは、ベアメタルやVM(パススルー)に比べるとコンテナにマウントされる分だけ複雑さが増します。しかし、VM(仮想ディスク)と比べるとシンプルな構成です。構成のシンプルさは、障害発生時の原因究明の容易さにも大きく影響します。
次のNode(Hypervisor)間での移動の容易さでは、コンテナは他に比べてKubernetesでのサポートにより優位です。VM(仮想ディスク)については、VMベンダーでHypervisor間のデータ移動のソリューションを提供している場合があります。
ただし、多くのソリューションでは仮想ディスクのデータコピーが発生し、CPUやネットワークに高負荷がかかります。ベアメタルとVM(パススルー)については、ストレージ自身が持つデータマイグレーション機能とマルチパスソフトを組み合わせたソリューションなどを利用する必要があります。
Nodeの移動の容易さは障害時の回復スピードやスケールアウトのし易さにも影響する場合があります。また、性能は早い・遅いのような単純比較はできないためしませんが、考えるポイントを示します。
ストレージの性能をダイレクトに反映されるのはベアメタルです。コンテナはベアメタルにコンテナでのマウントのみ追加されたアーキテクチャのため、性能劣化は少ない傾向です。
VM(パススルー)の性能は、構成から一見ベアメタルと同等に思えますが、違います。注意すべきはボリュームをマウントしているドライバやデーモンプロセス(iscsidなど)がVM上で動作していることです。そのため、HypervisorでのVMの優先度によって性能が大きく左右されます。
VM(仮想ディスク)は、構成のレイヤーが多段なため性能は悪いようにも見えます。しかし、実際は違います。VM製品によってはVMから仮想ディスクへの書き込みは同期処理で行い、仮想ディスクからボリュームへの書き込みは非同期に行うものもあります。そのため、仮想ディスクがキャッシュとして振る舞い性能向上するケースがあります。
このように、性能については様々な要素に影響されるため、実際に利用する環境で計測するのが良いでしょう。
おわりに
今回は、ステートフルアプリケーションをKubernetesで動作させるために重要となるストレージについて解説しました。現在(2020年)では、ステートフルアプリケーションを実行させるインフラとして、ベアメタル・VMに加えコンテナ(Kubernetes)も選択肢のひとつとなるまでに成長しました。
単に「慣れている」や「流行だから」という理由でインフラを選ぶのはやめ、アプリケーションの特性や管理体制などにマッチしたインフラを選ぶのがベターではないでしょうか。
この記事をシェアしてください
関連記事
CSIによるKubernetesのストレージ機能
2020年7月10日 6:30

坂下 幸徳(さかした・ゆきのり)
StatefulSetとPersistentVolumeを使ってステートフルアプリケーションを動かす
2021年7月16日 6:30
Oracle Cloud Hangout Cafe Season7 #1「Kubnernetes 超入門」(2023年6月7日開催)
2023年12月14日 6:30
CNDT2021、Kubernetes上のステートフルアプリに関する深い考察をゼットラボのエンジニアが解説
2021年12月2日 6:00
CNDT2020シリーズ:サイボウズのSREが語る分散ストレージの配置問題を解決するTopoLVMとは
2021年1月13日 17:17
バックナンバー
この記事の筆者

Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
