KubeCon Europe 2025からBloombergによるLLMをKserveで実装するセッションを紹介
KubeCon Europe 2025からBloombergによるLLMをKserveで実装するセッションを紹介する。
2025年5月22日 6:00
KubeCon+CloudNativeCon Europe 2025から、併催のCloud Native+Kubernetes AI Dayと命名されたミニカンファレンスで行われたBloombergのセッションを紹介する。BloombergはKserveと呼ばれる機械学習ジョブをKubernetes上で実行するためのプラットフォームを使って、大規模言語モデル(LLM)を実行するユースケースの解説を行った。Kserveの公式サイトにはBloombergはユーザーとしてトップに名前が挙げられていることから、BloombergはKserveを機械学習のプラットフォームとして高い評価を与えているのは間違いないようだ。Kserveのコントリビュータとして開発を行い、自社での利用も積極的に行っていると言える。

KubernetesとAIに特化したミニカンファレンス「Cloud Native+Kubernetes AI Day」
セッションのタイトルは「Serving the Future : Kserve's Next Chapter Hosting LLMs & GenAI Models」というもので、プレゼンターはBloombergのエンジニアAlexa Griffith氏とTessa Pham氏だ。

二人でプレゼンテーションを実施。左がPham氏、右がGriffith氏
Alexa Griffith氏はKserveのメインテナーで後半部分を担当、Pham氏は今回のプレゼンテーションでは前半部分のスピーカーとして解説を行っていた。LinkedInのプロフィールによれば双方とも2022年からデータサイエンスプラットフォームのエンジニアとして従事しており、Bloombergの機械学習及び生成AIのバックエンドを支えるエンジニアと言ったところだろう。

GenAIの時代というスライドで生成AIの課題を解説
まずは前提として生成AIが爆発的に増加し、さまざまなアプリケーションに応用され始めていること、生成AIの実行においては効率、スケーラビリティ、そして費用対コストの高さが求められていることを説明。

生成AIを実装する際の課題は主に演算リソースの高さとスケーラビリティ、信頼性など
従来の機械学習アプリケーションの実装よりもはるかに高い演算リソースが必要となることやスケーラビリティ、信頼性などを挙げて説明した。

Kserveによって生成AIの推論アプリケーションの課題を解決
ここでKserveを紹介し、Kubernetesにおいて生成AIのワークロードの実装がシンプルになったこと、複数のフレームワークをサポートしていること、モニタリングなどのオブザーバビリティがすでに実装されていることなどを解説した。ここでもメトリクスに対応したオートスケーリングやモデルのキャッシングなどが機能として実装されていることを利点として説明した。

Kserveのアーキテクチャー。コアにあるのはKnative
このスライドではKserveのアーキテクチャーを解説。GPU、CPUなどのハードウェアの上にKubernetesが実装され、KubernetesのサーバーレスのフレームワークであるKnativeが実装されるという階層構造となっている。Knativeと同じレベルにIstioが置かれているが、これはModelmeshと呼ばれるモードで、Kserveを実装する際のサービスメッシュの部分をIstioが担うということだろう。実際のドキュメントサイトでは、Model Servingというモードでは比較的シンプルな構造になっている。
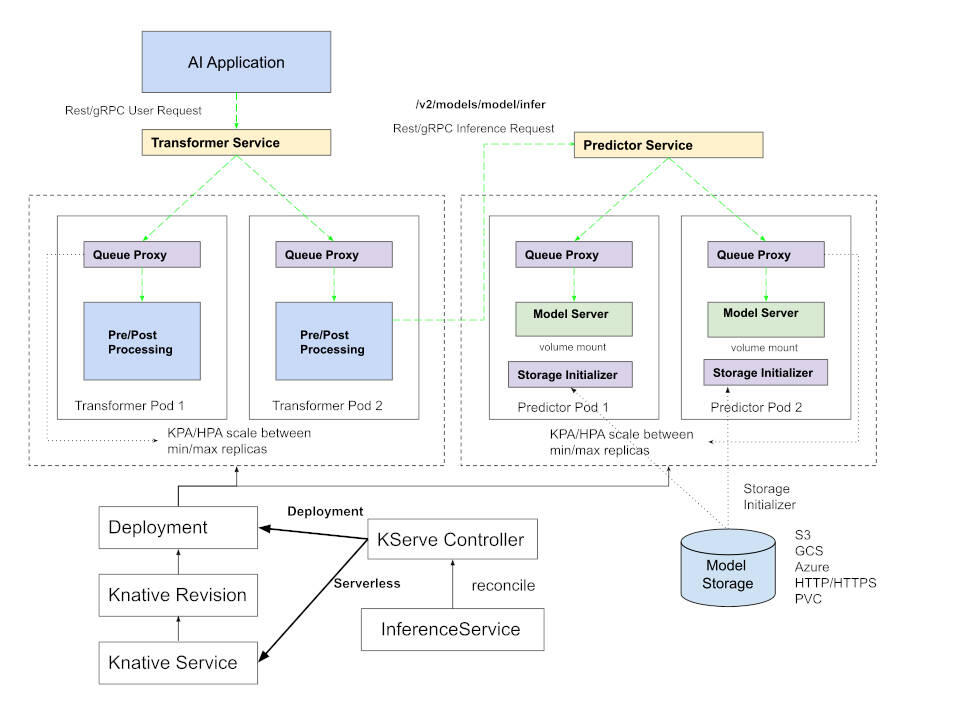
●参考:モデルサービングのアーキテクチャー
上記はKserveの公式ドキュメントからの引用となる。
そして生成AIのアプリケーションを運用する際のポイントをまとめたのが次のスライドだ。
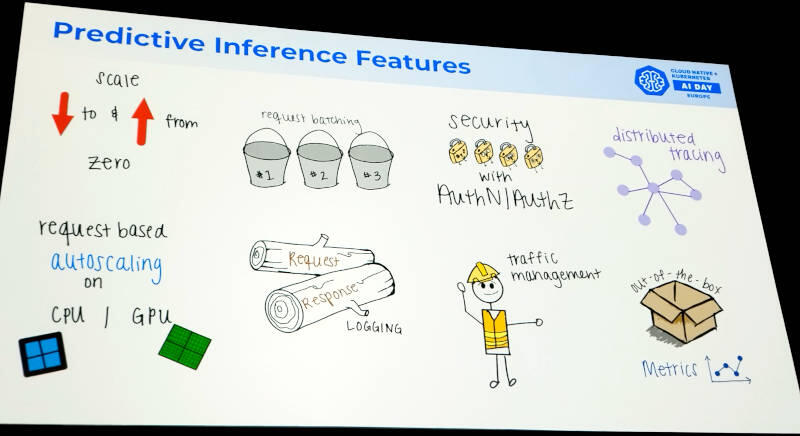
生成AIアプリケーションを運用する際のポイント
スケールアップとスケールダウン、オートスケーリング、バッチジョブの運用、ロギング、メトリクス、トレーシング、認証と許可、トラフィック管理など、大量のデータやストリーミングデータを扱うジョブと項目的には余り変わらないポイントが挙げられている。生成AIならではと言えるのはオブザーバビリティの部分だろう。
次に生成AIと機械学習における予測推論の違いを説明した。主に生成AIにおいては計算リソースの大きさ、レイテンシーの最適化が必要、高いスケーラビリティ、複数モデルの使い分け、巨大なモデルの管理などが挙げられている。

生成AIと予測推論の違いを説明
今回の解説のコアとなっているKserveに関して生成AIを実行するための新機能を解説した。

Kserveの生成AIに関する新機能を紹介
課題として挙げられていたスケーラビリティに加え、モデルやプロンプトのキャッシング、OpenAIプロトコルのサポート、トラフィック管理においてはEnvoyを使ったGateway APIを利用することを挙げている。
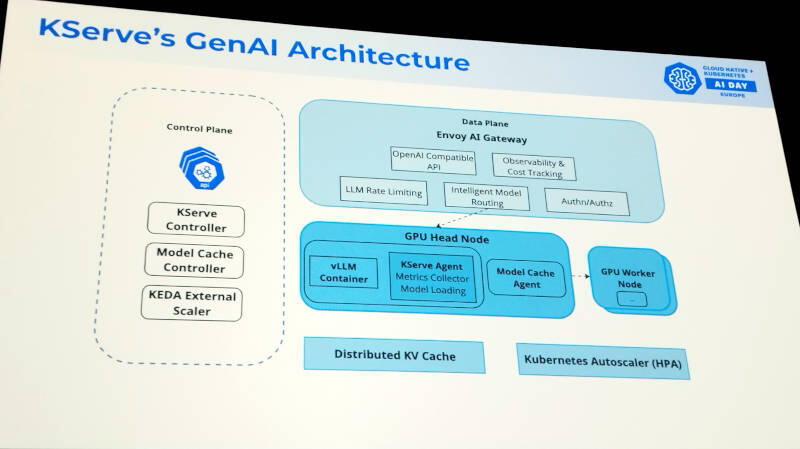
新機能で説明した内容を盛り込んだアーキテクチャー図
Kserve's GenAI Architectureというスライドでは、Envoy AI Gatewayによるデータプレーン、KEDAによるオートスケーラーなどが確認できる。KEDAはKubernetes Event-driven Autoscalerの頭文字を名称とするオープンソースソフトウェアである。また右隅に書かれているオートスケーラーはHorizontal Pod Autoscaler(HPA)で、どちらもオートスケーリングを実現するための仕組みだ。コントロールプレーンにはモデルのキャッシングを行うコンポーネントも記載されている。
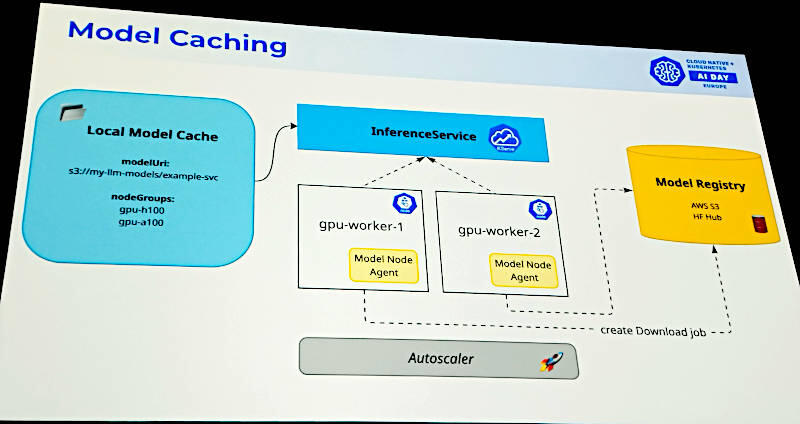
モデルキャッシングの解説図。モデルレジストリからのダウンロードを減らすのが目的
オートスケーリングについてはKEDAベースのマニフェストを例に挙げて説明。
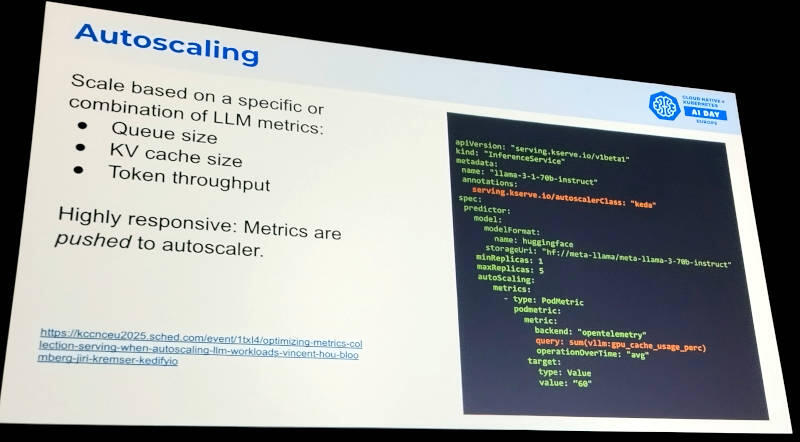
オートスケーリングの解説
OpenAIのプロトコルサポートについても説明を行い、100%の互換性を持っていることを強調した。

OpenAIのプロトコルをサポート
マルチノードの推論についても図を用いて簡単に説明。この機能はKubernetesのサービスとして実装されているようだ。
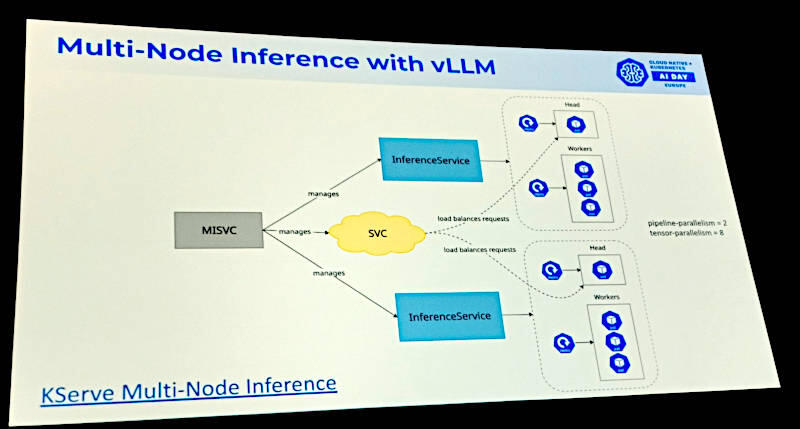
マルチノードでの推論サービスのアーキテクチャー図
キャッシングについては将来の計画として説明。この機能はLMCacheというソフトウェアを利用するようだ。
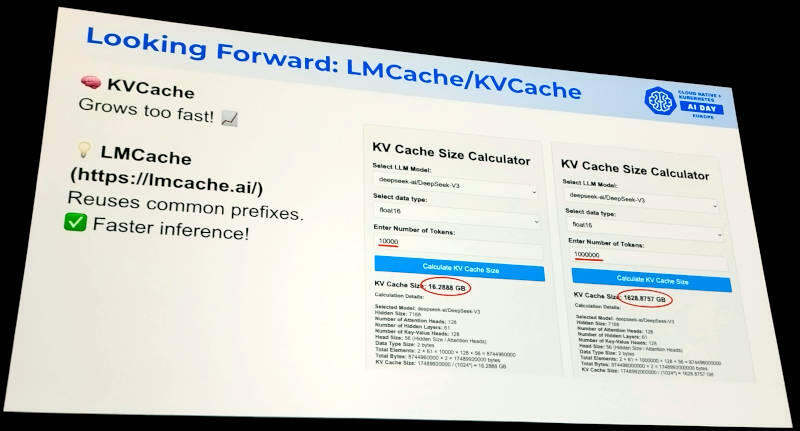
キャッシングについての解説。LMCacheを使う
●参考:LMCache
このスライドではキーバリューのキャッシュサイズがトークン数に比例して増えていることを赤字で強調している。この2つのキャッシュによって長文生成時のメモリー使用量を減らすことを目指しているのだろう。
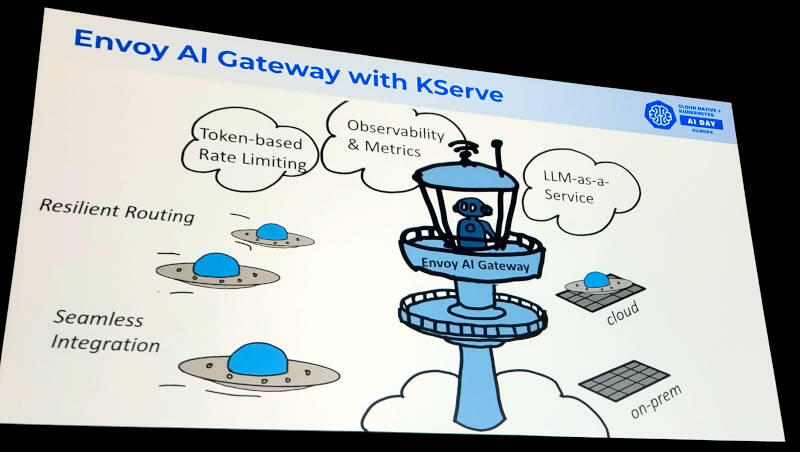
Envoy AI Gatewayの解説
KserveにおいてEnvoy AI Gatewayを使うことで複数のモデルへのトラフィックのルーティングやオブザーバビリティが実装できることなどを挙げた。そもそも生成AIをKubernetesで実装しようとする場合、なるべくメインストリームなソフトウェア(プロジェクト)を使うというのがリスクを下げるために必要という判断だろう。
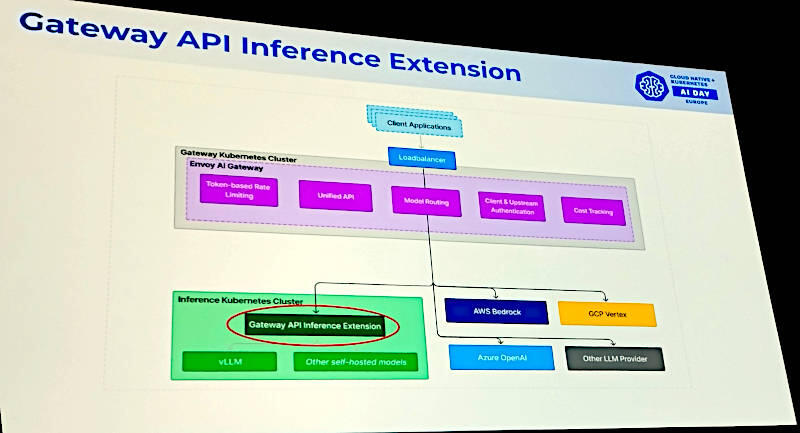
Envoy AI Gatewayからオンプレミスとパブリッククラウドに連携
Envoy AI Gatewayを使うことでオンプレミスの生成AIクラスターとパブリッククラウド上のマネージドサービスを上手くルーティングできることを説明。Gateway APIについては大きな期待をかけていることが次のスライドでも示されていると言える。
Gateway APIでオブザーバビリティとルーティングを効率的に実行できる
このスライドでは今回のKserveのユースケースについての教訓をまとめて説明。レイテンシーとスループットはトレードオフの関係にあること、最適化が必須、Gateway APIによってLLMをサービスのように実装できること、LLMにおいてもオブザーバビリティの実装が必須であることなどを説明した。このセッションで取り上げた内容がBloombergのどのようなサービスに使われているのかについて多くは語られなかったが、金融情報サービスとして応用の場面は多数存在するだろう。また実装時のチャレンジや未だ解決されていない課題などについては説明されず、Kserveの良い宣伝という形に収まってしまったのが残念だ。この辺りはユーザーというよりもKserveのメインテナーとしての立ち位置に終始してしまったということだろう。次回以降ではユーザー側に立ったリアルな声にも期待したい。
●Kserve公式ページ:https://kserve.github.io/website/latest/
●KserveのGitHubページ:https://github.com/kserve/kserve
最後になるが、Bloombergというアメリカのビジネスパーソンなら誰もが知る金融情報サービスの大手でも、スライドには手書き風のイラストを多用し、女性エンジニアがプレゼンテーションを行っている辺りに、外部から見えるお硬いイメージはある程度払拭できたのではないだろうか。最後のスライドではお約束の「We are Hiring !!」を強めの声で語り、多数の求人ポジションを見せるなどしていたことが印象的なセッションだった。
- この記事のキーワード
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
SASEのCato Networks、CEOによるセミナーとインタビューを紹介
2020年4月16日 6:00
Rustのエコシステムの拡がりを感じるデスクトップアプリのためのツールキットTauriを紹介
2022年12月16日 6:00
Zabbix式オープンソースの秘密に迫る
2025年1月31日 6:00
WebAssemblyとRustが作るサーバーレスの未来
2020年4月21日 6:00
三菱電機が設立したOSPOのメンバーにインタビュー。「インナーソース」を戦略的に使う背景とは?
2025年10月3日 6:00
エンタープライズLinuxを目指すSUSE、Red Hatとの違いを強調
2015年2月3日 19:00
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
