並列クエリを上手に使いこなす!
テーブルの上手な分割
ここでは、ログの解析を例にとりテーブルの分割を考えましょう。例えば単純に1ヶ月単位でテーブルを分割したとします。通常、頻繁に行われるログの分析は、大昔のことというよりは、むしろ、最近のことを分析することが多いです。このため、3年分のログを36ヶ月分に分割したとしても、実際の処理で活躍するのは、最近12ヶ月分であって、残りの24ヶ月分を担当するノードは、ほとんど働かないという状況が生じるかもしれません。
この場合、ログを解析するという目的に対して、「本当に時系列でテーブルを分割するのが良いのか?」ということを検討する価値があるかもしれません。時系列ではなく、年齢や地域などのユーザ属性ごとにテーブルを分割する方法もあるかもしれません。
以上のように、テーブルをどう分割するかによって、並列クエリの威力がどの程度発揮されるかが変わってきます。そして、その分割の選択肢は多様であるため、自らのアプリケーションの特性を見極めて、最適となるよう分割を行うと良いでしょう。
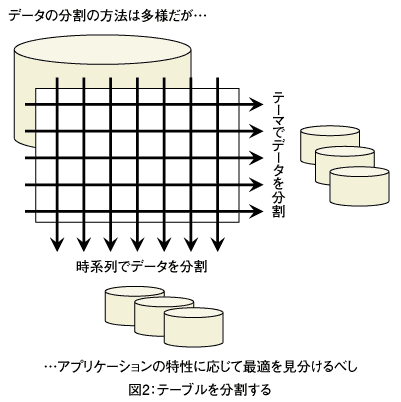
テーブル分割は複数を併用することもありえる
アプリケーションの特性を見極めた際に、甲乙つけがたく、どうしてもテーブルの分割方法が1つに固まらない場合もあるでしょう。そのような場合には、多少冗長かもしれませんが、2種類の分割方式の双方を採用するというのも手です。これによりAという検索を行う場合には、Aに特化した分割をした並列クエリを行い、Bという検索を行う場合には、Bに特化した分割をした並列クエリを行うことができます。
もちろん、冗長にすればするほど、管理・運用が煩雑になるので、あまり気安く手を出すべきものではありません。しかし、検索の速度を高めるためには、あらかじめ想定できる事態に対処できるよう、冗長なデータの格納をするということも、選択肢の1つとして持っておくべきです。
ただし、更新が頻繁に行われるようなテーブルにおいて、冗長なデータ構成にした場合には、排他処理や同期をとるのが大変なので、アプリケーションの特性に応じて、選択することが大切です。
テーブルの分割の際には、単純に並列クエリが最速になるということのみで決定すべきものではありません。ログの解析などは、さほど頻繁に行うものでもなければ、恐ろしく速いレスポンスを求められるものでないことが通常です。クエリが多少遅くても問題ないでしょう。こうした場合には、バックアップのやりやすさなどを考慮して、時系列でテーブルを分割しておくことがトータルでは優れた設計になるかもしれません。
時系列でテーブルを分割するとしても、アクセスが頻繁に行われるであろうテーブルに対しては1ヶ月ごとに分割するなど分割度合いを高め、古いものは3ヶ月分ごと、または半年分ごとといった具合に、その粒度を大きくすることで、効率を少しでも高める工夫はできるでしょう。
大切なことは、さまざまな要素を考慮し、技におぼれず、合理的な理由のもとに、選択を行うということです。






