はじめに
みなさん、こんにちは。本連載では、これまでインフラの概要と主要技術を紹介してきましたが、今回はその技術を使用していく中で「インフラエンジニアが直面する様々な問題」という切り口で解説していきたいと思います。
インフラエンジニアの仕事
連載のおさらいになりますが、インフラエンジニアは様々なハードウェアやソフトウェアを組み合わせて設計や構築を行っています。この様々な製品や技術の存在がインフラエンジニアという仕事の難しさの一端を担っているのですが、実際の現場ではどのようなことが起きるのでしょうか。
読者のみなさんも耳にしたことがあるかと思いますが、1990年代までは大型汎用機(メインフレーム)が業務システムの主役でした(図1)。メインフレームは今でも大企業や官公庁を中心に使用されていますが、メインフレームメーカの中には製造を停止するところも現れ、徐々にオープン系システムに移行されているのが現状です。ただ、メインフレームに慣れているお客様の中には根強いファンもいて、私自身も製薬会社のシステム更改の際にオープン系システムへの移行に強く反対する担当者とのやりとりに苦労した思い出があります。

図1:NECのメインフレーム「ACOS」
メインフレームのメリットは、何と言っても「安定性」です。ハードウェア、OS、アプリケーションと全てを同一メーカが提供しており、組み合わせもしっかりと試験された上で提供されています。一方でオープン系システムは「様々な製品」が「様々なメーカ」から提供されています。「自由に組み合わせられる」と言うと聞こえは良いですが、実際に全ての組み合わせについてテストされているわけではないので、色々な問題が発生する可能性があります(図2)。

図2:メインフレームとオープン系システムの対比イメージ
ここからは、私が実際に経験した具体的な問題事例を紹介していきます。皆さんがプロジェクトで仕事をする上での参考にしていただければと思います。
1. ハードウェアの不具合
システムの規模にもよりますが、システム開発では数十台以上のサーバを購入して、それをインフラエンジニアが組み上げていくことになります。通常は導入サービスとしてCE(Customer Engineer)と呼ばれるメーカのエンジニアがサーバの設置、初期設定、テストをしてくれるのですが、それでも引き渡されたものを使用してみると不思議と不具合が発生します。
システムボード障害やメモリが認識されないなど、あらゆるパーツに不具合の発生する可能性がありますが、今までの経験の中で最も衝撃的だったのはMACアドレスの重複です。「MACアドレスは世界で一意であり、重複するものではない」と信じて疑っていなかったのですが、2台のサーバ間で重複していたのです。
そのサーバはネットワークの冗長化をしていたのですが、運が悪いことに該当のネットワークカードは待機系として使用されており、切り替わりが行われた時にだけ通信が不安定になるという事象が発生していたところから問題はスタートしました(図3)。
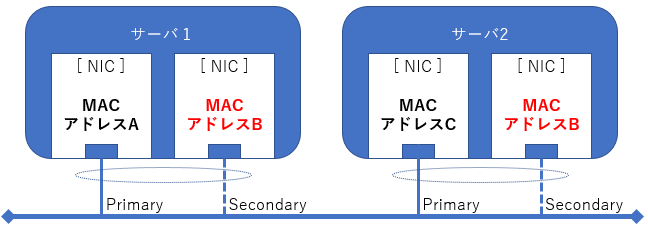
図3:【ハードウェアの不具合】サーバ構成図
このような場合には、可能性として下記の原因が考えられるのですが、問題を要素分解して原因を探ることを「切り分け」と言います。
① NICの問題
② LANケーブルの品質が悪い
③ 接続先ネットワークスイッチとの相性(昔は良くあった)
④ OSのネットワーク設定に不備がある
⑤ 接続先ネットワークスイッチの設定に不備がある
⑥ 冗長化特有の問題
まず⑥の問題をつぶすため冗長化の設定を解除して単純な構成にしてみましたが、相変わらず通信は不安定であり、⑥の可能性は低いことが分かりました。③と⑤に関してはネットワークチームを巻き込む必要があるため、次は①②④について確認しました。
このような具合で徐々に切り分けしていくと、この時は①の可能性が高くなってきました。本当にNICが壊れていればメーカに連絡して交換してもらえますが、「何だかおかしい」程度では対応してもらえません。そこで第3回でも使用した専用ソフトでパケットキャプチャを実施してみました。Pingコマンドを実行しながらパケットキャプチャをするのですが、それぞれのサーバのIPアドレスに対するARP要求に同一のMACアドレスの応答が確認でき、最終的にMACアドレスの重複が判明しました(図4)。
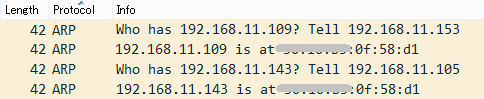
図4:ARP通信イメージ
MACアドレスが重複した経緯についてはメーカに何度も問い合せをしましたが、サーバ製造元の米国本社にエスカレーションされ、結局うやむやにされてしまいました。ハードウェアの不具合はとりわけ時間がかかるため、構築工程の早い段階で顕在化できるように受入確認やテストを計画しておく必要があります。
2. ソフトウェアの不具合
ソフトウェアに関してはどうでしょうか。Linux OS(Red Hat Enterprise Linux)上に「NetBackup」というバックアップソフトウェアをインストールしてOracle領域をバックアップするという構成での話です(図5)。NetBackupはミドルウェア(システム運用)製品の1つですが、そのシステムでは「バックアップを取得している最後のタイミングでエラー終了してしまう」という事象が発生していました。
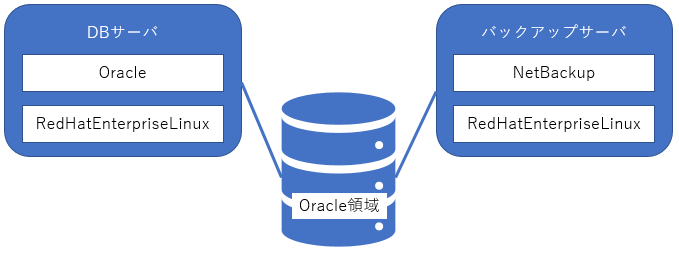
図5:【ソフトウェアの不具合】システム構成図
NetBackupのログにはエラーが出力されるので、そのログや各種設定情報をNetBackupのサポートに送付するのですが、なかなか解決に至りません。OSやOracleのサポートも同じ状況でした。
このような場合には、もう少し情報を収集してOSが悪いのか、Oracleが悪いのか、NetBackupが悪いのかをインフラエンジニアが切り分けしてあげる必要があります。このシステムの場合、Oracleの領域をrawデバイス(OSのファイルシステムを使用せずに、ダイレクトにディスクにアクセスする方法)としてバックアップしていました。一方で、他のファイルシステム領域のバックアップは成功していたため、まず下記の絞り込みができました。
- ファイルシステム領域のバックアップ:成功
- raw領域(ファイルシステムをスキップ)のバックアップ:失敗
次に、rawアクセスはOSが提供している機能であるため、「実はNetBackupではなくOSが怪しいのでは」と推測を立て、下記のコマンドを実行してみました。詳細は割愛しますが、ddコマンドはraw領域を扱うことのできるコマンドで、このコマンドではraw1という名前のraw領域の内容を1Mバイトずつ読み出しています。
# strace dd if=/dev/raw/raw1 of=/dev/null bs=1Mまた、straceはインフラエンジニアであれば覚えておいた方が良いデバッグ用のコマンドです。プロセスが使用するシステムコールなどを可視化してくれますが、簡単に言うとコマンドを打った時の動きを通常より細かい単位で確認できるようになります。
ここまでの推測が正しければこのコマンドも最後に失敗して、その時の細かいエラー内容をOS上で確認できるのでは、と期待していました。結果的にはこの推測が正しく、エラー内容をOSサポートに送付することで下記のOSのバグを見つけることにつながりました。また、問題はカーネルをアップデートすることで解決されました。
https://access.redhat.com/solutions/1191763今回紹介したものは、インフラエンジニアにとってはよく発生する典型的な事例です。OSとミドルウェアは密接に連携しているため、表面的なエラー内容だけではすぐには原因を特定できないことが多々あります。サポートとのやり取りは思いのほか時間がかかるため、設計時の検証や構築の初期段階で気になるところをテストするなど、早めに顕在化する動きが必要となります。
3. 組み合わせによる不具合
サーバとサーバ、ネットワーク機器の組み合わせにも注意点があります。その中の代表的な1つが通信タイムアウトではないでしょうか。通信には一定時間やりとりがない場合に接続を切断するための「タイムアウト値」が設定されています。普段は問題にならないのですが、サーバ、OS、ミドルウェア、ネットワーク機器が関連してくると、お互いのタイムアウト値に矛盾が発生することがあります。
例えば、図6はAPサーバとDBサーバがファイアウォールを介して通信する、一般的なシステム構成です(図6)。

図6:【組み合わせによる不具合】システム構成図
コネクションプールはAPサーバからDBサーバへの接続時によく使用される技術ですが、その名の通り接続を事前にプールしておく技術です。通常は通信が発生した時に接続を行いますが、通信が発生する前にあらかじめ接続しておくことで接続のオーバヘッドを削減できます。
ここでよく問題になるのが「コネクションプールの未使用タイムアウト」と「ファイアウォールの無通信タイムアウト」です。例えば、下記は私が関わったプロジェクトで使用していた製品のデフォルト設定です。
- コネクションプールの未使用タイムアウト:30分
- ファイアウォールの無通信タイムアウト:15分
この場合、15分以上使用していないコネクションプールはファイアウォールにより強制的に切断されてしまいます。ファイアウォールで切断されたことを知らないAPサーバは「接続できているもの」として扱うため、実際にこのコネクションプールを使用して接続するとDBサーバからの応答をずっと待ち続けることになります。
このような製品間の隙間みたいなものは様々存在しており、インフラエンジニアは積極的にこれらをカバーしていく必要があります。また、カバーするためには普段から主要技術について全般的な基礎知識を身につけておく必要もあります。
連載を通して、インフラエンジニアが関わる「プロジェクト」に注目し、さまざまな側面から解説していく本コラム。今回は、プロジェクトにおける文化について解説します。
冒頭で「文化」と書きましたが、これからIT業界に携わる人にはこれが結構厄介な存在です。例えば、使う用語1つ取っても「基本設計」を「方式設計」と呼んだり、「詳細設計」を「環境設計」や「定数設計」と呼んだりと様々です。工程ごとに設計する範囲もプロジェクトごとに異なってきます。
略語も、「単体テスト」を「UT(Unit Test)」や「CT(Component Test)」と略したり、「結合テスト」を「IT(Integration Test)」と略してさらに「ITa」と「ITb」に分けてみたりと、プロジェクトでは当たり前に使われている単語なので逆に分かりにくかったりします。私も前後の文脈をもとに「よっしゃ、分かったぞ」と思って単語を使ったら、通じなかったなんてこともよくあります。
メールの書き方にも特徴があります。”様”ではなく”殿”がデフォルトだったり、名前を括弧でくくると様をつけなくても敬称扱いになったりと結構面白いです。
レビュに関してもプロジェクトごとにルールがあります。私が経験したもので最も大変だったのが、「本番環境の手順書を9回レビュしないといけない」というものでした。かつて色々な過ちを犯してきたプロジェクトであったため、そのたびにレビュ観点や回数が増えていったということでしたが、さすがに目的を見失いそうになります。
(第9回へ続く)
インフラエンジニアに大事な能力
ここまでインフラエンジニアが直面する様々な問題を紹介してきました。インフラエンジニアになるきっかけは人それぞれなのですが、周りの人を見ていて「成功しているな」「うまく好循環を作れているな」と感じる人には、下記のような特性があるのではと思っています。
- モノづくりにわくわくする才能がある
- 継続して物事に取り組むことができる(勉強熱心である)
- 前に出ることができる
- 聞いて、考えて、伝えることができる
- チームで仕事ができる
我々の仕事は世界に2つとないシステムを作っていく仕事なので1については必須だと思います。仕事をしていれば良い時もあれば、悪い時もあります。同じものを作るのであれば計画通り進むのですが、プロジェクトを進めていく中でどうしても課題が出てきます。毎日9時18時で確実に帰れる仕事でもありません。そんな時にはわくわくする言葉のレベルは違いますが、それぞれ「良いものを作りたい」「良いものを提供したい」「この仲間と最後まで作りたい」といったものをモチベーションに頑張っています。
また、インフラエンジニアになってサービスを提供するうえでの最初のジレンマは技術力です。どうしても「知識や経験がないと良い仕事ができない」「インプットを増やしていかないと周りから必要とされるスタートラインに立てない」という側面があります。さらにインフラ技術は時代とともに新しいものが出てくるので、日々キャッチアップしていくことも必要となります。最近では仮想化やパブリッククラウドが有名なところですが、さらに細かいレベルでは多くの技術が出てきています。
ただ、私たちの仕事において、技術力は本質ではありません。弊社は戦略的にエンタープライズのシステムに携わるようにしているのですが、大きなシステムでは特にその傾向は強くなります。理由は簡単、大きなシステムは1人で作るものではないからです。3~5は図らずも経済産業省が発表している「社会人基礎力」と同じなのですが、技術を超えて人間が工夫できる余地がある、結果を変えていけるといったところにドラマが生まれます。
インフラエンジニアにおける最初の段階では、技術が大事だと感じ、また周りから評価される場面が多いため、どうしてもこのような当たり前に思えることが忘れ去られていきます。私自身も技術偏重から最初の数年は多くの失敗を経験しました。会社の合併に伴うシステム統合において私の担当箇所で2回失敗して担当を外されたり、本番稼動しているサーバを停止したりと、多くの人に迷惑をかけました。
おわりに
今回は少し観点を変えてインフラエンジニアの仕事にフォーカスしてみました。システムの大規模化に伴い日常の仕事も縦割りになりがちですが、そのような環境だからこそシステム全体を俯瞰してみることのできる能力がますます必要になってきていると感じます。
さて、実は本連載も今回で最終回の予定だったのですが、社内外の多くの方々のご支援もあり、連載の延長が決定しました。これまで執筆したメンバ全員で打ち上げまでしたのですが、おいしい料理の思い出を糧に、下記の内容を解説していく予定です。
- 第9回:バックアップ/リカバリ
- 第10回:セキュリティ
- 第11回: プログラミング
次回以降も楽しみにしていてください!
- この記事のキーワード
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
