Rancherを構成するソフトウェア
前回までの記事では、Rancherのインストールや、Rancherを使った開発のベストプラクティスを紹介してきました。
今回は、Rancherをプロダクション環境下で運用するために理解が欠かせない、Rancherのアーキテクチャについてご紹介します。
バージョンについて
今回の記事では、バージョン2.1.5を前提に紹介します。
Rancherのバージョンによって、多少の違いはありますが、バージョン2.0以降は全体像が変わるほどの大きな変更はなされていないため、2.0以降の他のバージョンを利用している方にも参考になるかと思います。
Rancherを構成する5つの要素
Rancherは大きく分けて下記の5つの要素で構成されています。
- Rancher Serverを動かすためのKubernetes(Parent Kubernetes)
- Rancher Server
- Rancher Cluster Agent
- Rancher Node Agent
- RancherからDeploy/管理されるKubernetes(Child Kubernetes)
これらの要素の相互関係は、以下の図のようになります。
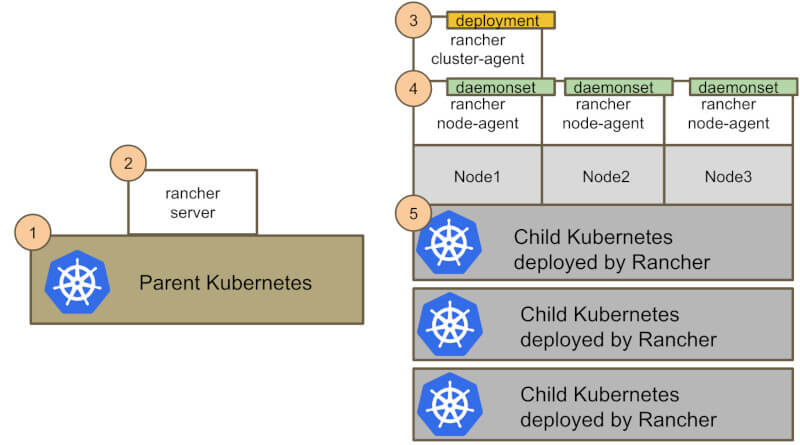
Rancherの構成
上記の図を見ると、2種類のKubernetesクラスタ(「Parent Kubernetes」、「Child Kubernetes」)が確認できます。この2つのKubernetesクラスタは、別の責任・ライフサイクルを持ちます。
Parent Kubernetesは、Rancher Serverを動かすために、事前に用意されるべきクラスタです。もう一方のChild Kubernetesは、Rancher ServerからDeployされるユーザのワークロードが動くクラスタです。Child Kuberentesのライフサイクルは、Rancher Serverによって管理されます。
Rancherの公式ドキュメントや、ソースコードの中でこのような呼び分けはされていないのですが、理解する上で便利な呼び分けなので、今回の記事ではParent Kubernetes/Child Kubernetesのように呼び分けをすることにします。
続いて、各要素がどのような役割を持っているのかを紹介します。
Rancher Serverを動かすためのKubernetes
このKubernetesは、主にRancher Serverが扱うデータの保存先として利用されます。
Kubernetesには、Custom Resource Definition(以下、CRDと表現する)というユーザが任意のリソースを定義できる仕組みがあります。この仕組みを利用すると、Kubernetes上のPodやServiceと同じようにユーザが定義したカスタムリソースを作成することができます。
RancherはこのCRDを活用し、Rancher Serverが扱うデータをすべて、Parent Kubernetes上のカスタムリソースとして表現しています。
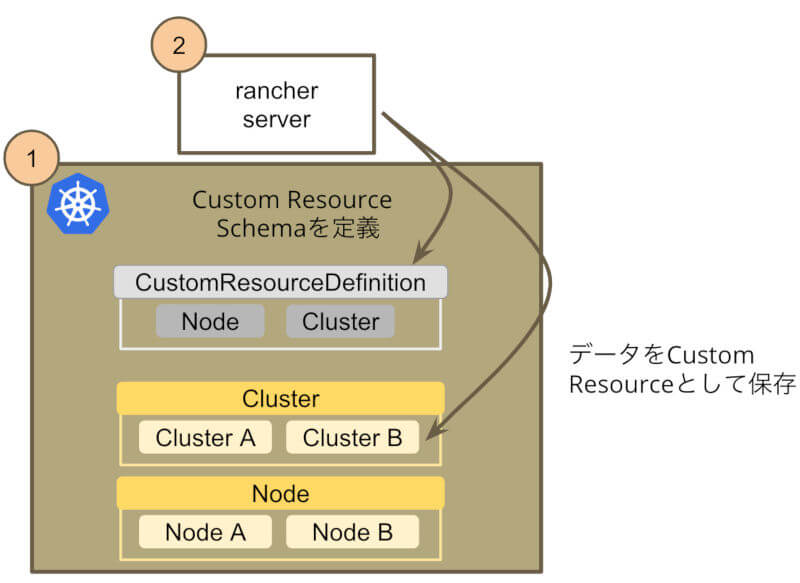
Rancher Serverが扱うデータはParent Kubernetesのカスタムリソースとして扱われる
しかし、Rancherを使ってKubernetesを便利に管理/活用したいのに、「Rancherを動かすために Kubernetesをまず構築しましょう」というのは、本末転倒な気がします。
そのため、Rancher Serverが利用するKubernetesを準備する方法は、いくつか用意されています。環境の重要度、手軽さを考慮し、それぞれユーザに適した方法を選べます。
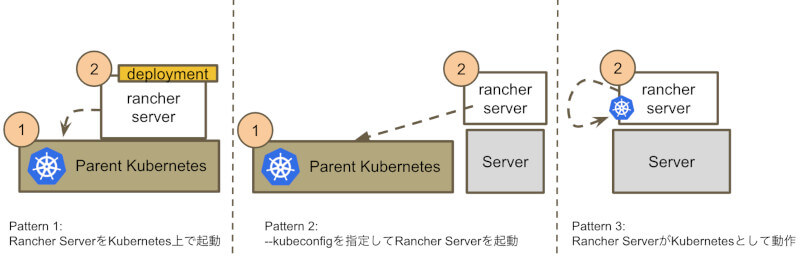
Parent Kubernetesの準備方法
公式ドキュメントのHAインストールはPattern 1に、Single Nodeインストール はPattern 3に該当します。
Rancher Server
Rancher Serverは、Rancherのコアとも言える重要な要素で、下記のような責任を担っています。
- Rancher API/GUIの提供
- Rancher Resource(データ)をParent Kubernetesに保存
- Kubernetesの構築
- 構築したKubernetesの定期的なステータスのSync
- Kubernetes上のワークロードの管理(ingress、deployment、service……)
- 管理している複数のKubernetesの認証機能/アクセスのプロキシ
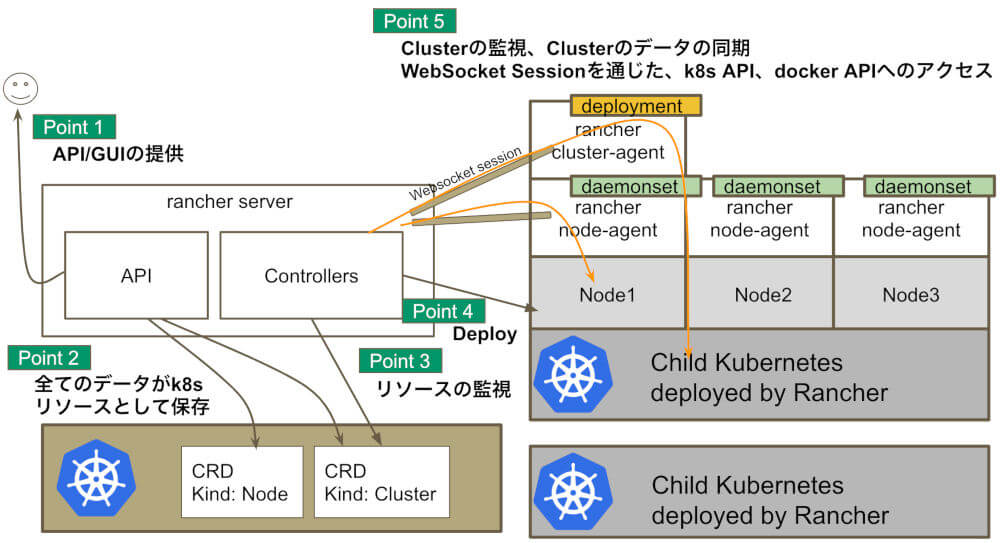
Rancher Serverの機能 その1
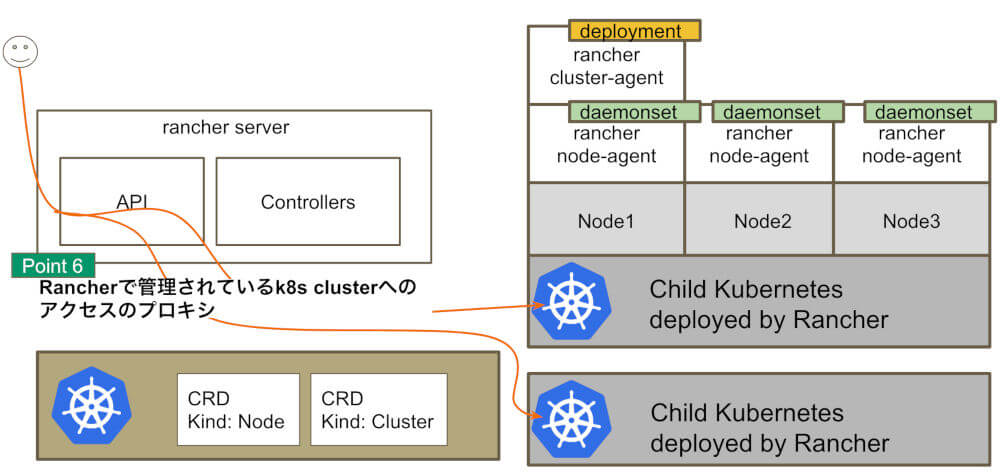
Rancher Serverの機能 その2
Rancher APIとController
Rancher Serverは、APIを提供しています。API呼び出し後のリソースの作成、削除のロジックは、Kubernetesのリソースの作成、削除のロジックに似ており、実装がAPIとControllerに分かれています。
Rancher API
Rancher APIはユーザに公開されており、ユーザはGUIまたはHTTPクライアントを介して呼び出すことになります。Rancher APIは、Rancherが取り扱うリソース、例えばクラスタ、ノードなどの理想の状態をKubernetesのカスタムリソースとして保存します。
「POST /v3/nodes」「POST /v3/clusters」などノード追加やクラスタ構築用のAPIを叩いた時に、実行が期待される実際の構築ロジックは、APIのロジックとは分離して実装されています。
それらの構築ロジックは、Controllerとして実装されており、APIリクエストのハンドリングのロジックの中ではなく、APIとは完全に別のライフサイクルを持つControllerが非同期で処理を実施します。
そのためAPIの責任範囲は、ユーザからのリクエストを元にリソースの理想の状態をKubernetes上にカスタムリソースとして保存をするところまでです。
Rancher Controller
Rancher Controllerは、Rancherのカスタムリソースを始めとしたKubernetesのリソースを監視しています。APIまたは他のControllerがリソースを変更した際にControllerはその変更を検知して、変更内容に応じて処理を実施します。
監視対象のリソースごとにControllerが実装されています。Controllerの代表的なものとしては、Clusterリソースを監視しているCluster Controllerや、Nodeリソースを監視しているNode Controllerが挙げられます。
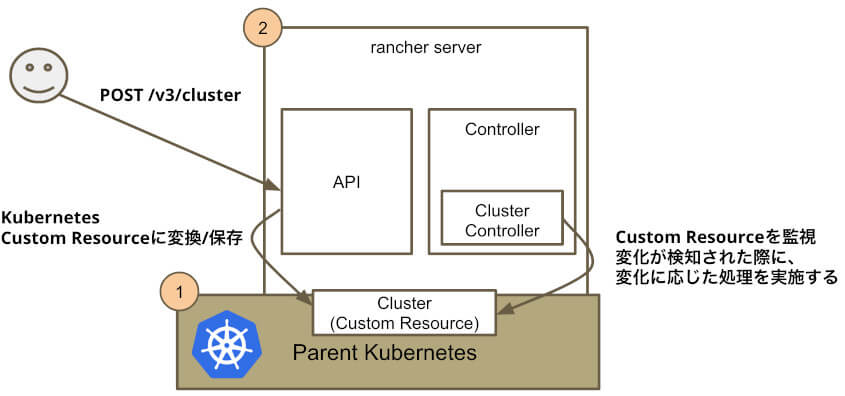
Controllerの一種であるCluster Controller
このようにKubernetes上にカスタムリソースを定義し、該当のカスタムリソースに変化/追加があった際に、実際のステートがカスタムリソースで定義されているステートに近づくように、Controllerが処理を実施するようなデザインパターンを「Kubernetes Operatorパターン」と呼びます。Rancherもこのデザインパターンを採用しています。
Embedded Kubernetes
Rancher ServerはAPI、Controllerの他に、「Embedded Kubernetes」というとても重要な機能も提供しています。これは、Parent Kubernetesの準備の方法に関連する機能です。
Rancher Serverは、データの保存先にParent Kubernetesを利用しています。しかし、起動時にParent Kubernetesの情報をRancher Serverに渡さなかった場合、または、まだ構築をしていない場合は、Rancher ServerはParent Kubernetesを見つけられないため、データの保存先を確保することができず、きちんと動作しません。
しかし、https://github.com/rancher/rancher/blob/v2.1.5/README.mdのQuick Startセクションには、下記のコマンドでRancherが利用可能になると記述されており、Kubernetesの構築を一切せずともRancher Serverが利用可能になると記されています。
リスト1:以下のコマンドでRancherが利用可能に
sudo docker run -d --restart=unless-stopped -p 80:80 -p 443:443 rancher/rancher
これは、なぜでしょうか? 実はこれを可能にしているのが、Rancher ServerのEmbedded Kubernetes機能です。Rancher Serverが起動時にParent Kubernetesの情報を見つけられなかった場合、Rancher Server自身がetcd、kube-apiserver、kube-controller-managerと同等の機能を提供し、自身が提供するetcd、kube-apiserver、kube-controller-managerにデータを保存します。
Production環境では、公式ドキュメントのHAインストールに記述されているように、事前にKubernetesクラスタを構築することが推奨されています。そのため、Embedded Kubernetesの機能は、テスト環境などでのみ利用することになると思います。
Rancher Serverは1つの実行ファイルである
Rancher Serverの実装はAPI、Controller、Embedded Kubernetesと分けられており、Controllerは監視対象のリソースごとに複数用意されていると紹介しました。しかしそれらの実装は、1つの実行ファイルにまとまっています。
Rancherの開発者でない限り、ユーザが直接実行ファイルを起動することはなく、多くのユーザは、Rancher ServerをDocker Image経由(rancher/rancher)で実行しています。
そのため、Kubernetes上で動かすためのHelm Chartもhttps://github.com/rancher/rancher/tree/master/chartで管理されており、このHelm Chartを使ってRancher ServerをDeployすることがRancherの公式ドキュメントでも推奨されています。
Helm Chartを使ってインストールした場合、Rancher Server(rancher/rancher)は、Deployment Resourceとして起動されます。
Rancher Cluster Agent
Rancher Cluster Agentは、Rancher Serverとは別の実行ファイルとして、1つにまとめられています。Rancher Server同様、Rancher Cluster Agentも基本的にはDocker Image経由(rancher/rancher-agent)で実行されます。
Rancher Serverとは異なり、ユーザが直接Rancher Cluster Agentを意識してデプロイすることはありません。Rancher Cluster Agentは、Child Kubernetesを構築後、クラスタの状態を管理するために、Rancher Serverがクラスタに1つだけ起動します。
Rancher Cluster Agentはクラスタの状態を管理するために、下記のような責任を持ちます
- クラスタ情報をRancher Serverへ登録
- WebSocketを利用したTCP、Unix Socket Proxy機能をRancher Serverに提供
Rancher Serverが、RancherビルトインAlert機能や、Log Aggregation機能、クラスタのステータスの定期的な同期の実現のため、クラスタのKubernetes APIを呼ぶ必要が生じる場合があります。その際は、基本的にこのTCP Proxyを経由して通信します。
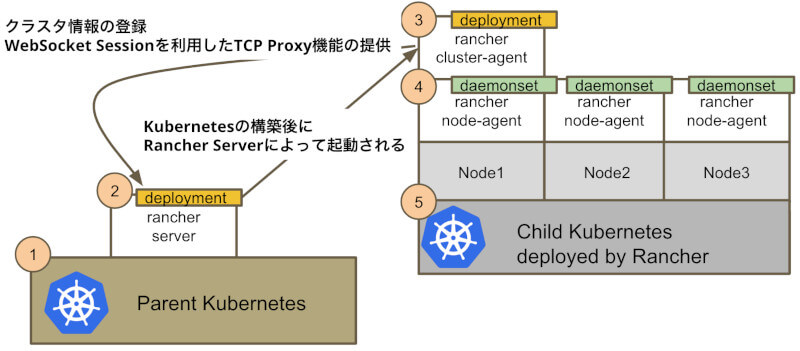
Rancher Cluster Agentが提供するTCP Proxyを経由して通信
Rancher Node Agent
Rancher Node Agentは、Rancher Serverとは別の1つの実行ファイルであり、Rancher Cluster Agentと同じ実行ファイルを利用しています。そのため、基本的にはRancher Cluster Agentと同じく、Docker Image経由(rancher/rancher-agent)で実行されます。
Rancher Node Agentも、Rancher Cluster Agentと同じく、Rancher Serverによって起動されます。しかしRancher Node Agentは、daemonsetとして全ノードで起動されます。
Rancher Node Agentは各Nodeのステート、各Nodeで動くKubernetes Processの状態管理のために、起動後次のような責任を持ちます。
- Rancher ServerへNode情報の登録
- 起動しているNodeで動かすべきコンテナ(kubeletなどのKubernetes Process)を定期的に取得し、起動
- 起動しているNodeに配置すべきファイルを定期的に取得し、配置
- WebSocketを利用したTCP、Unix Socket Proxy機能をRancher Serverに提供
Rancher Node Agentが提供するProxy機能は、該当ノードで起動されているdockerdのAPIを呼び出すために利用されます。この時dockerdには、TCPではなくunix socket経由で接続します。Rancher Serverは、Docker APIを使うことで、Kubernetesを構成するための管理プロセスをコンテナとして立ち上げたり、コンテナを新しいものにアップグレードしたりしています。
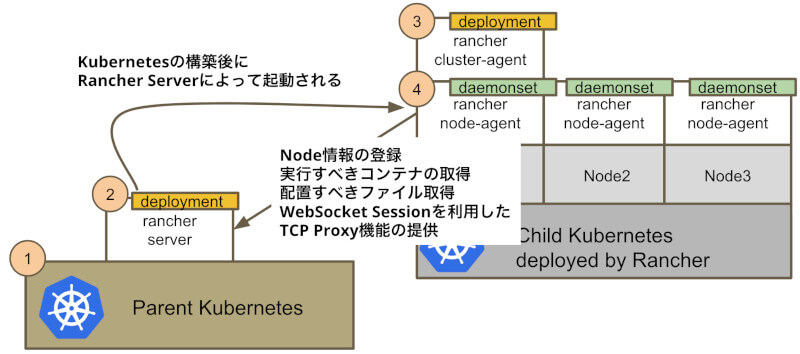
Rancher Node Agentの機能
ここで注意したいのが、Rancher ServerからデプロイされるKubernetesクラスタが、GKEやパブリッククラウドのマネージドKubernetesサービスである場合の挙動です。Kubernetesのノード上で動くKubernetes Process(kubeletなど)の状態管理やアップグレードなどはPublic Cloud側が処理してくれるため、その際はNode Agentは、Nodeで動かすべきコンテナや配置すべきファイルの定期的な確認は実施しません。
RancherからDeploy/管理されるKubernetes
最後は、Rancherからデプロイ/管理されるKubernetesクラスタです。Rancherのユーザは、このKubernetesクラスタ上でApplicationやその他のワークロードを動かすことになります。
Rancherから管理できるKubernetesクラスタには、大きく分けて3つの種類があります。
- GKE、EKSなどのパブリッククラウドのマネージドKubernetesサービス
- RKE(Rancher Kubernetes Engine)を利用して構築したKubernetes
- 構築済みのKubernetesをインポート
これらのどのKubernetesクラスタも、Rancherの特別なロジックが含まれたものではないので、一般的なKubernetesとしてOperator Hubで公開されているKubernetes Operatorなども利用可能です。
Rancherを構成する5つの要素の紹介まとめ
ここまで、Rancher Server、Rancher Cluster Agent、Rancher Node Agent、Parent Kubernetes、Child Kubernetesの各々の概要と役割を紹介してきました。
全体を通して、いくつか重要なポイントをここでおさらいしておきます
- Rancher Serverの実装は、APIとControllerに分けられている
- Rancher APIはKubernetesのProxyのようにふるまい、RancherのデータはParent Kubernetesのリソースとして保存される
- Rancher Controllerは、Parent Kubernetes、Child Kubernetesのリソースを監視しており、変更を検知した際に、変更内容に沿った処理を実施する
- Rancher Serverは、ほとんどのビジネスロジックを実装しており、Child Kubernetesと通信が必要な際は、AgentがWebSocket経由で提供するTCP、Unix Socket Proxyを通じて通信する
- Rancher Cluster/Node Agentは、WebSocket経由でTCP、Unix Socket Proxy機能をRancher Serverに提供するだけで、多くのビジネスロジックは、Agent側には実装されていない
- この記事のキーワード
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
