Istioの全貌
Istioが備える特徴や提供する機能、またそれを実現するためのアーキテクチャーを紹介いたします。
2018年9月18日 11:00
サービス・メッシュ・ファブリック:Istioの登場
マイクロサービス・アーキテクチャー(Microservices Architecture、MSA)に基づいて設計・開発されるクラウド・ネイティブ・アプリケーションは、比較的粒度の小さな複数のサービスから構成されます。これらのサービス間のネットワークを「サービス・メッシュ」と呼びます。サービスの大きさに具体的な指針はありませんが、サービスの総数は数十、大規模システムともなれば数百に上ることが予想されます。多くの場合、各サービスはクラスター構成を取ることになるでしょうから、サービス・インスタンスの数はその数倍となるでしょう。数十から数百のサービス・インスタンスが連携する極めて複雑なネットワーク環境で、ルーティングやロード・バランシングといったトラフィック管理、各サービス個別のリリース、システム全体の信頼性を判断するためのエンドtoエンドのテスト、障害影響の最小化、ログ/トレースやメトリクスの収集と監視を実装していかねばなりません。
アプリケーションそのものである「サービス」の運用に深く関係するため、ネットワーク基盤のみならずアプリケーション層も意識した、包括的なソリューションが求められます。そこで登場したのが「サービス・メッシュ・ファブリック」です。サービス・メッシュ・ファブリックは、サービス・メッシュ全体を覆う織物(fabric)のようなソリューションで、サービス・メッシュの最適化を図ります。
サービス・メッシュ・ファブリックの研究・開発自体は、すでに数年前から始まっていました。その一つがAmalgam8です。Amalgam8はIBMが開発し、2016年6月にオープン・ソース・ソフトウェア(https://github.com/amalgam8)として発表したサービス・メッシュ・ファブリックです。主にサービス・メッシュのトラフィック管理にフォーカスしており、ブルー/グリーン・デプロイメントや、カナリア・リリース、A/Bテスティングをサポートします。またサービス・レジストリーとディスカバリー、カオス・エンジニアリング実践のため意図的に障害を発生させる機能(フォールト・インジェクション)も提供します。
一方Google Cloudは、サービス・メッシュにおけるセキュリティとテレメトリー(分散環境におけるログ、トレース、メトリクスの統合)に取り組んでいました。早い段階からサービス・メッシュ・ファブリックの研究・開発に取り組んでいたIBMとGoogle両社が、それぞれのプロジェクトを統合して始めたのがIstioプロジェクトです。軽量のプロキシー/ルーターであるEnvoyの開発を主導するLyft社も主要な開発メンバーに加えて、オープン・ソース・プロジェクトとして2017年Istioの開発をスタートさせました。そして2018年7月31日、Istio V1.0がリリースされました。Istioの正式版リリースを以って、いよいよクラウド・ネイティブ・アプリケーション開発の準備が整いました。
Istioの特徴
Istioの特徴の一つが、マルチ・プラットフォーム対応です。Istio 1.0はKubernetesとConsulをサポートしており、それぞれの環境におけるセットアップ手順を公開しています(2018年8月時点)。また、MesosやCloud Foundry等、他のオーケストレーション・フレームワークへの展開を示唆しています。すなわち、クラウド・ネイティブ・アプリケーション開発・運用者は、プラットフォームの違いを超えて、Istioの提供機能を利用することができます。
Istioの特徴の二点目とて、アプリケーションに依存しないことが挙げられます。Istioは、コンテナ・オーケストレーション層の上位、そしてアプリケーション下位に位置する、「アプリケーション基盤」とも呼ぶべきソリューションです(図1)。
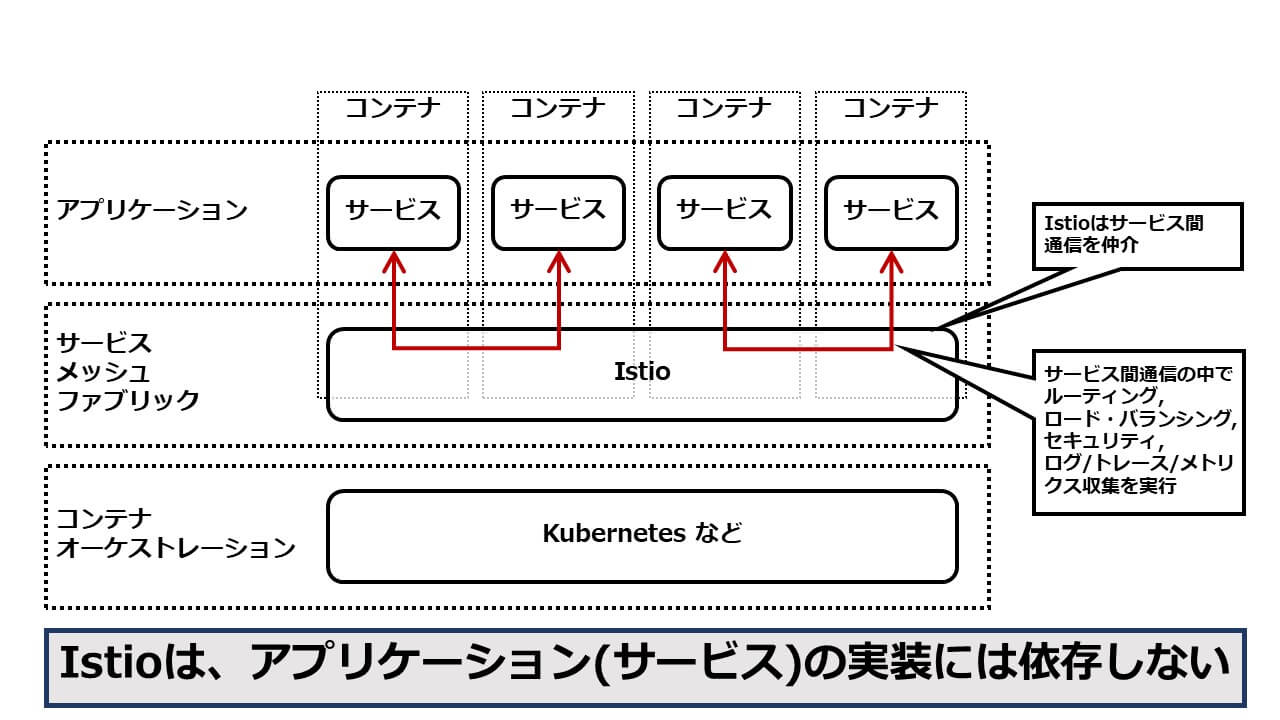
図1:ソフトウェア・レイヤー構造におけるIstioの位置づけ
このような構造の下で、Istioはいわばプロキシーとしてサービス間通信を仲介しますが、その通信のタイミングで、トラフィック管理やセキュリティといった主要機能を実行します。すなわち、Istioの機能を利用するために、サービスのソース・コードを変更する必要は一切ありませんし、サービスのプログラミング言語も問いません。Netflix OSSに見られるように、サービス・メッシュ・ファブリックに期待される機能の一部をAPIライブラリーとして提供する試みもありますが、この場合、サービスのプログラミング言語が限定されてしまいますし、サービスの実装を追加変更することになります。なによりアプリケーション開発者が、非機能要件部分の実装に多くの時間と工数を割くことに繋がりますので、効率的なアプローチとは言えません。サービス・メッシュ・ファブリックの実装方針としてみた場合、APIライブラリーとIstioの違いはこの点にあります。
そしてIstioの特徴の三点目として、「ポリシー」を基準とした運用が挙げられます。Istioでは原則として、特定のコンテナやPod、仮想マシンを指定した上で具象的に操作する必要はありません。あるべき姿ややりたいことをポリシーとして定義し、その履行をIstioに依頼するという抽象的なスタイルを取ります。ポリシー・ベースのオペレーションでは、操作が直感的で分かりやすいですし、操作ミスの低減も期待できます。
コンテンツ・ベースド・ルーティング(Content-Based Routing、以後CBRと表記)を例に取れば、Istioでは「一般ユーザーはサービスAのバージョン1.0(現行本番システム)に、テスト・ユーザーはサービスAのバージョン1.9(バージョン2のベータと仮定)に」と割り振るように定義するだけで、一般ユーザーからのリクエストは本番システムに、テスト・ユーザーからのリクエストはテスト用の次期本番システムに割り振られます。それぞれのシステムが稼動する物理的なデプロイ情報を考慮しながら、基盤オペレーターが操作する必要はありません。
Istioの提供機能
Istioが提供する機能は「トラフィック管理」、「セキュリティ」、そして「テレメトリー」の3つに大別されます。
トラフィック管理としては、ルーティングやロード・バランシング、タイムアウトと再試行等サービス間通信に求められる基本機能を提供しています。Istioならではの付加価値としては、サービスのバージョン、あるいはリクエスト・ヘッダーやボディの中身に応じたルーティング(CBR)、また、一定の割合ごとにロード・バランシング先を割り当てる(Weight-Based Routing、以後WBRと表記)といった運用が可能となっています。これらの仕組みを応用することで、ブルー/グリーン・デプロイメント、カナリア・リリース、A/Bテスティングを実装することができるのです。また、意図的に障害をシミュレートするフォールト・インジェクションや、サービス呼び出し失敗時の影響を局所化するサーキット・ブレーカーも基本機能として提供します。
セキュリティとしては、サービス間通信における認証と認可、データの暗号化機能を提供します。
テレメトリー(telemetry)とは、不特定多数のサービスからログやトレース、メトリクスを収集し、それらのデータを監視に供する基盤機能に相当します。Istio自身が、ログや監視等の個別の機能を実装しているわけではありません。ログはFluentd、分散トレーシングはZipkinやJaeger、監視や検索にはPrometheus、ダッシュボードはGrafana等、既存のコンポーネントを活用し連携させて、超分散環境における監視機能を実現します。
Istioで何をするか? 何ができるのか?
次に、Istioの基本機能を活用して、どのようなことができるのか概観してみましょう。
ブルー/グリーン・デプロイメント
サービスを停止することなく、新たなシステムをリリースする手法がブルー/グリーン・デプロイメントで(図2)、すでに利用されている本番環境を新たに置き換える際に利用されます。クラウド・ネイティブ・アプリケーションにおいては、既存サービスを置き換える新たなサービスのリリース手法として、ブルー/グリーン・デプロイメントを使用することになるでしょう。

図2:ブルー/グリーン・デプロイメント
ブルー/グリーン・デプロイメントは、環境「ブルー(図2では仮に現行の本番環境に見立てています)」、環境「グリーン(同じく図2では次期本番環境と見なしています)」、そしてブルーとグリーンのそれぞれ環境にリクエストを転送するロード・バランシング機能から構成されます。Istioを用いたクラウド・ネイティブ・コンピューティング環境では、ブルーは現行本番サービス、グリーンは次期本番サービス、そしてIstioのトラフィック管理機能がロード・バランシング機能を提供します。
ブルー/グリーン・デプロイメントの動作は次のようなものです。最初はエンド・ユーザーからのリクエストは環境「ブルー」に転送されています(図2の1)。次期本番環境の開発・テストが終わり、正式にリリースする際にはIstioのトラフィック管理機能を操作して、リクエストの転送先を環境「ブルー」から環境「グリーン」に切り替えます(図2の2)。それ以降、エンド・ユーザーからのリクエストは環境(グリーン)に転送されるようになります(図2の3)。万が一、環境「グリーン」の新しい本番環境に致命的な不具合が見つかり、緊急避難として前の本番環境を暫定的に利用したい場合には、Istioトラフィック管理機能を操作して、リクエストの転送先を環境「ブルー」に切り戻します(図2の4)。
カナリア・リリース
十分なテストを実施していたとしても、新たなシステムのリリースは緊張する大きなイベントです。人間が携わる作業である以上、思い違い、確認漏れ、操作ミス等様々な落とし穴が待ち構えており、リスクを完全に払拭することは不可能だからです。私たちにできることは、リスクを最小化するための準備を講じることですが、カナリア・リリースはそのための一つの解決策です。
カナリア・リリースとは、事前に新システムを一部のユーザーに試行してもらって、そのフィードバック結果を以って、全ユーザーへの本格リリースの可否を判断する、新システムのリリース手法です(図3)。鳥類のカナリアを冠する一風変わったネーミングは、炭鉱におけるガス漏れ事故の素早い検知にカナリアを利用していたというエピソードに由来します。
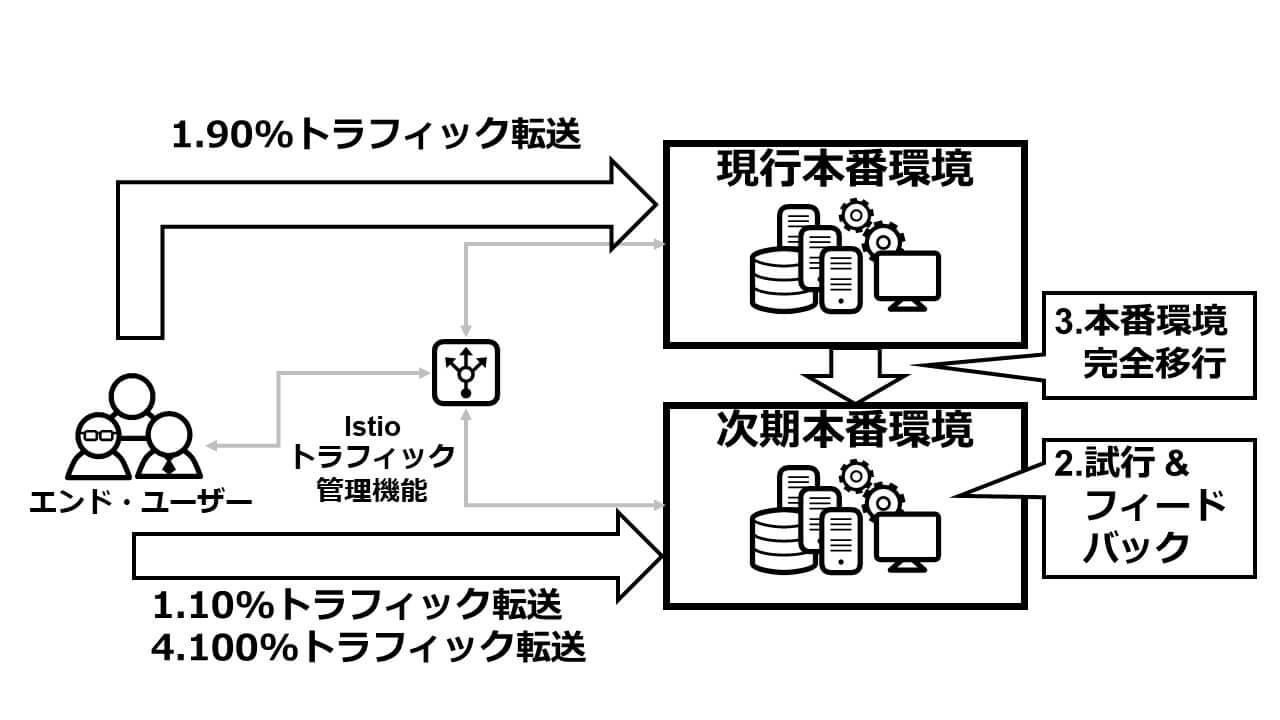
図3:カナリア・リリース
図3を用いてカナリア・リリースの典型的な動作シナリオを解説しましょう。エンド・ユーザーの大多数(例えば90%)からのリクエストは現行の本番環境に転送されて、従来通りのアプリケーション処理が履行されますが、その一方で一部のエンド・ユーザー(例えば10%)のリクエストを次期本番環境に転送して、そのリクエストの処理には新たにリリースを予定しているアプリケーションを利用します(図3の1)。すなわち、図3においては10%のエンド・ユーザーは新システムの試行に参加していることになります(図3の2)。試行結果のフィードバックを基に、不具合があれば修正し、問題がなければ、Istioのトラフィック管理機能を操作して、次期本番環境を全面リリースします(図3の3)。それ以降、Istioのロード・バランサーは、エンド・ユーザーの全てのリクエストを次期本番環境に転送します(図3の4)。
このシナリオを実現する上で、Istioのユニークなトラフィック管理機能が役立っています。その一つが、リクエスト転送先の細分化です。Istioはリクエスト転送先のサービスを、ホスト名とサブセットで指定することができます。サブセットとは任意の文字列であり、例えば「V1」や「V2」といったバージョンを指定することができます。すなわち、Istioではホスト名とサブセットを利用することで、「カタログ・サービスのバージョン1」とか「カタログ・サービスのバージョン2」といった具合に、アプリケーション層のレベルでリクエストの転送先を区別する仕組みが提供されているのです。
このようなリクエスト転送先の細分化に加えて、図3で紹介したシナリオで利用しているのがWBRです。Istioのロード・バランサーは、リクエストの転送先ごとに、転送するリクエストの割合を百分率(パーセント)で指定することができます。
またWBRに加えて、CBRもサポートします。例えば、リクエスト・ヘッダーに含まれる認証情報を基に、一般ユーザーからのリクエストを「カタログ・サービスのバージョン1」に転送すると同時に、テスト・ユーザーは「カタログ・サービスのバージョン2」を利用する、といった構成を取れるのです。
リクエストの転送先の細分化、WBRやCBRといったルーティング等のバリエーションに富むIstioのトラフィック管理機能は、カナリア・リリースだけでなく、次に紹介するA/Bテスティングにも応用することができます。
A/Bテスティング
A/Bテスティングとは、ユーザー経験評価のために、複数のバリエーションのWebシステムをホスティングし、エンド・ユーザーの実体験のフィードバックを入手するマーケティング手法です。ICTシステムの観点では、複数バージョンのシステムを同時並行で運用し、リクエストの割合やユーザーの属性等、然るべきポリシーに基づいてエンド・ユーザーのリクエストをそれぞれに転送することが求められます。すなわち、A/Bテスティングの実現において、カナリア・リリースの説明で紹介したIstioのリクエスト転送先の細分化の手法であるWBRやCBRを活かすことができるのです。
カオス・エンジニアリング
高い可用性を求められる本番システムは、万一の障害に備えて、冗長構成や自動復旧の仕組みを求められます。クラウド・ネイティブ・コンピューティングにおいても高可用性の追求は重要な要件の一つであり、Kubernetesはコンテナ・クラスターの高可用性構成をサポートしていますし、Istioもタイムアウトや再試行、後述のサーキット・ブレーカーといった障害からの自動復旧、障害影響の局所化・最小化を図る仕組みを提供します。
とはいえ、製品機能の充実が、即、現実のシステム運用の品質向上に繋がる訳ではありません。十分な時間と手間をかけて設計・実装・テストを実施したにも関わらず、障害発生時に高可用性機能が上手く働かなかったという話はしばしば耳にします。多くの場合、それぞれ個別の製品機能は適切に構成しテストされていたが、他の製品機能と組み合わせたシステム全体の最適化を怠っていたということがその原因にあるようです。これは、多くの分散配置されたコンポーネントから構成されるサービス・メッシュにとって他人事ではありません。分散システム全体として、万一の障害発生に際して、意図した通りに可用性を維持できるのか、また、一定水準のパフォーマンスを保てるのか検証し、改善する取り組みが求められます。このような背景の下、本番あるいは本番相当のシステムにおいて、意図的に障害を発生させて(カオス、Chaos、「混乱」のこと)、その後のシステムの振る舞いを評価し、より障害に強いシステム改善を目指す手法をカオス・エンジニアリングと呼びます。
カオス・エンジニアリングを支援するツールとして有名なのが、NetflixがOSSとしてリリースしているChaos Monkeyと関連するソフトウェア群です。これらのツールを用いることで、意図的にシステムのクラッシュや遅延を発生させることができます。Istioのフォールト・インジェクション機能は、このようなカオス・エンジニアリングを支援する機能を提供します。
フォールト・インジェクションとは、Istioのトラフィック管理機能がサービス間通信を仲介する過程で意図的に障害をシミュレートする機能で、ネットワークの遅延や、サービス呼び出しの失敗をサポートします。ネットワークの遅延は、Istioのトラフィック管理機能が呼び出し先サービスへのリクエスト転送を保留して、その際のシステム全体の振る舞いを確認するものです(図4)。また、サービス呼び出しの失敗は、Istioのトラフィック管理機能がリクエスト呼び出し元に意図的にエラー(HTTPの例で言えば、HTTPステータス500等)を返す機能です。これは呼び出し先サービスの障害をシミュレートするものです(図5)。
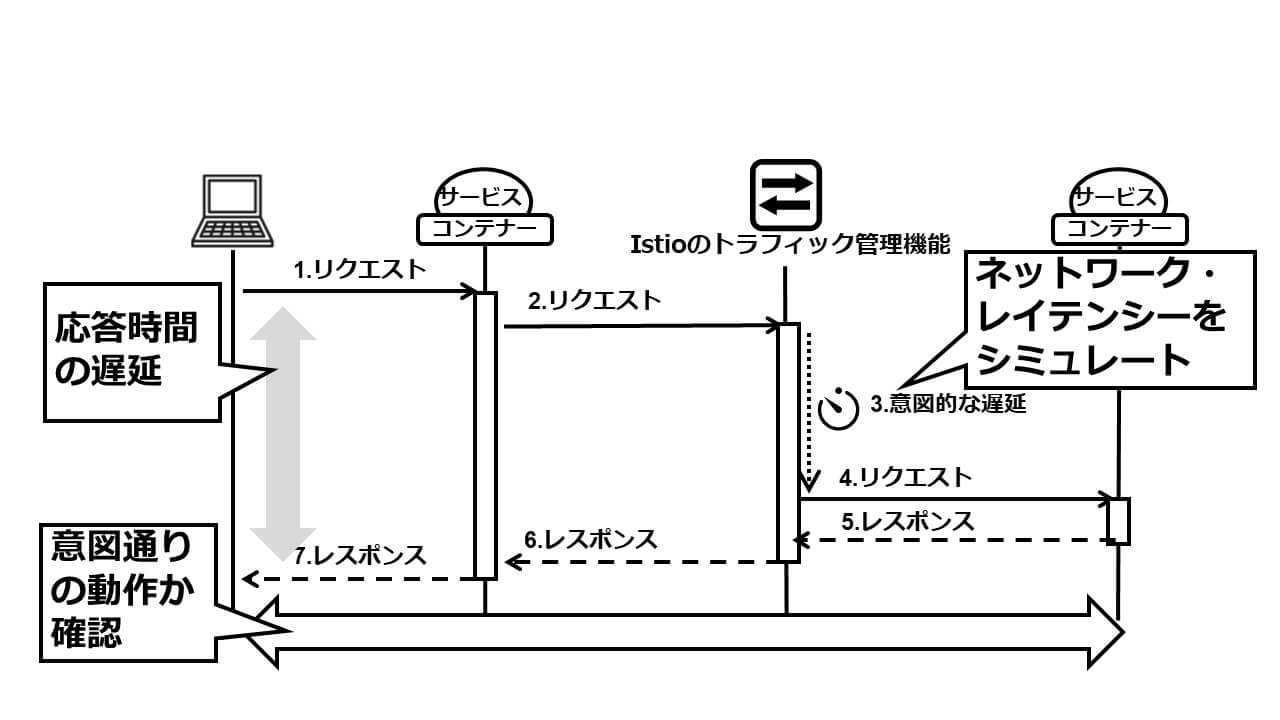
図4:フォールト・インジェクション:ネットワーク遅延のシミュレーション
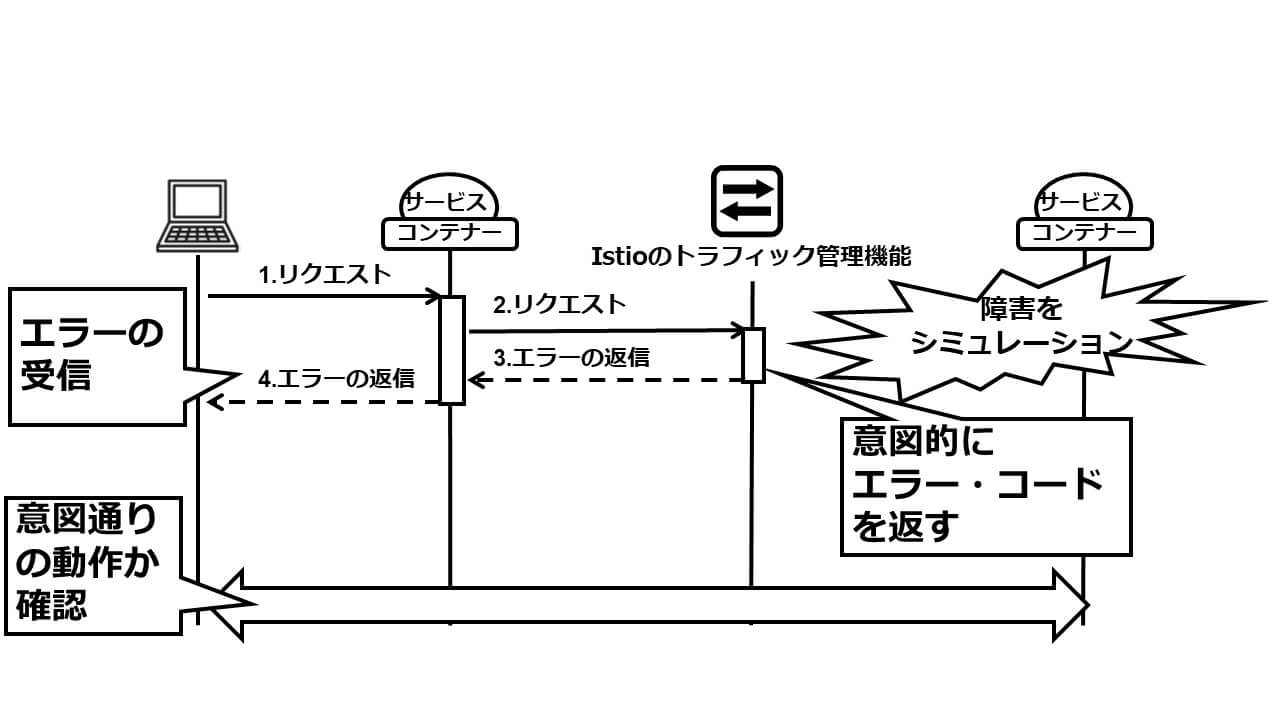
図5:フォールト・インジェクション:サービス障害のシミュレーション
フォールト・インジェクションは、他のIstioの機能と組み合わせて利用することもできます。例えば、特定のバージョンのサービスを呼び出す時のみ、障害をシミュレートすることが可能です。また、WBRと組み合わせて、一部のリクエストのみが障害の影響を受けている状況を作り出すことが可能です。さらにCBRを利用することで、一般ユーザーは通常の本番システムを利用する一方で、テスト・ユーザーのリクエスト処理には障害のシミュレーションをするという使い方もできます。このようなバリエーションを柔軟に取ることができる理由は、Istioでは実際に障害を発生させているわけではなく、通信経路であるサービス・メッシュ上で障害を「シミュレート」していることにあります。
サーキット・ブレーカー
分散システムにおいては、ささいな不具合が大きな障害を引き起こす可能性があります。例えば、ある一つのサービスがダウンしたと仮定しましょう。リクエスターはそのサービスの呼び出しに失敗することになりますが、事態はそう単純には済みません。多くの場合、通信処理にはタイムアウト値が設定されています。呼び出し先から即座にレスポンスを得られない場合に備えて、リクエスターはタイムアウトが満了するまで応答を待つことになります。つまり、1つ以上のネットワーク・コネクション、いくらかのメモリーやCPUといったシステム・リソースを消費しながら、タイムアウトで指定した期間、期待できない応答を待つのです。
仮にこのシステムが非常に多くのリクエストを処理する高トランザクション・システムで、ダウンしたサービスはほぼ全てのリクエストが利用するコア・コンポーネントであったならどうなるでしょうか? 膨大なリクエストが滞留し、最悪の場合システム全体の障害に繋がるかもしれません。このような最悪の事態を避ける手法の一つとして、サーキット・ブレーカーの適用が考えられます。
サーキット・ブレーカーとは、システム障害の影響を局所化し、システム全体への波及を抑えるデザイン・パターンです。そのコンセプトは、サービスのダウンを検知したら、それ以降のサービス・リクエストに対してはタイムアウトの満了を待つことなく、即座にエラーを返すというものです。すなわち、システム稼動を脅かす要因となるリクエストの滞留を排除するのが、サーキット・ブレーカーの骨子なのです。
超分散ネットワークであるサービス・メッシュにおいてもサーキット・ブレーカーは有益なソリューションであり、Istioを使えば簡単にサーキット・ブレーカーの利用が可能になります。図6を用いて、Istioを用いたサーキット・ブレーカーの動作を説明しましょう。
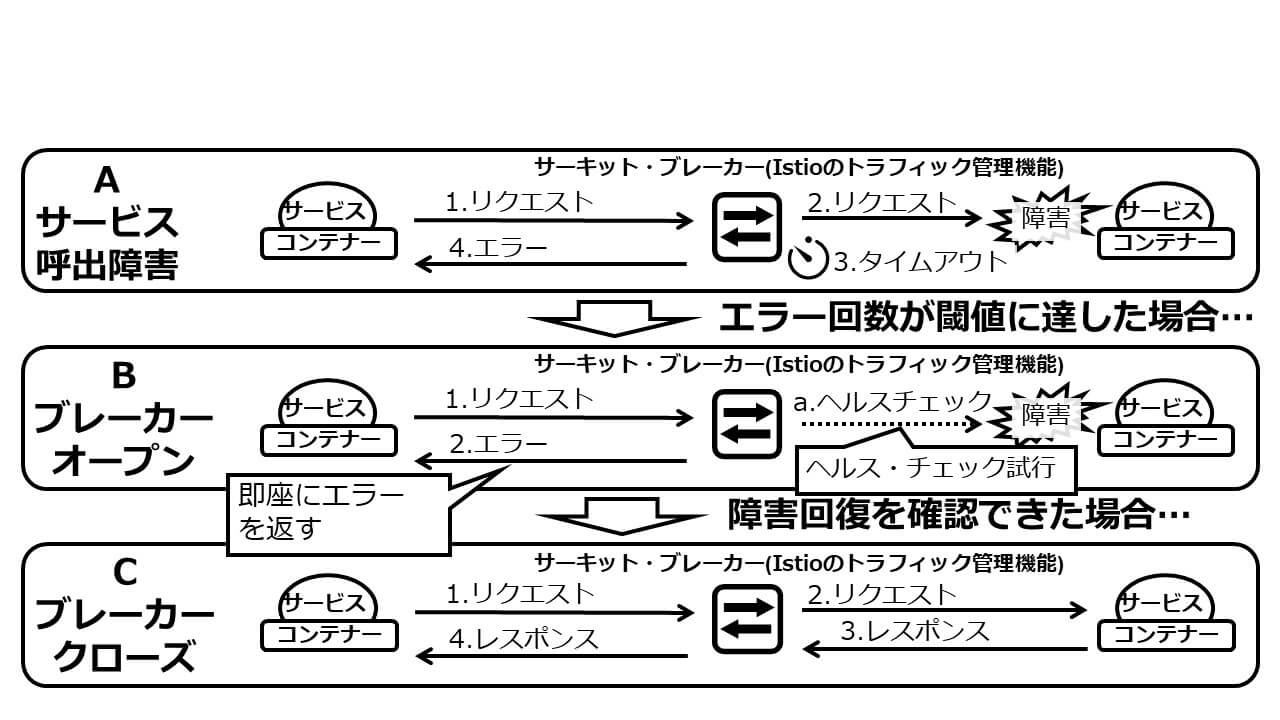
図6:サーキット・ブレーカーの動作フロー
通常時、サービスに障害が発生した場合には、Istioのトラフィック管理機能は、タイムアウト満了時までサービスの応答を待ち、その後リクエスターにエラーを返します(図6のA.サービス呼び出し障害)。同等のエラーの発生回数が、予め設定した閾値に達すると、Istioのトラフィック管理機能は当該サービスへのリクエストを受け取ると、タイムアウトの満了を待つことなく、即座にリクエスターにエラーを返します(図6のB.ブレーカー・オープン)。その一方で、Istioの管理機能は、バックグラウンドでダウンしたサービスにヘルス・チェックのためのポーリングを繰り返します。ヘルス・チェックの結果、サービス復旧を確認すると、Istioのトラフィック管理機能は、当該サービスへのリクエストの転送を再開します(図6のC.ブローカー・クローズ)。
- この記事のキーワード
この記事をシェアしてください
関連記事
Oracle Cloud Hangout Cafe Season4 #4「Observability 再入門」(2021年9月8日開催)
2024年4月23日 6:30
BookinfoデモでIstioを体感する
2018年10月30日 6:40
Keycloakと認可プロダクトを利用したマイクロサービスにおける認証認可の実現
2023年10月23日 6:00
KubeCon 2日目の注目はAirbnbのユースケースとBallerina
2019年1月25日 6:00
Kubernetesをサービスメッシュ化するIstioとは?
2018年3月6日 6:00
アプリケーションをモジュラーモノリスとして記述し、容易にマイクロサービスとしてデプロイできるフレームワーク「Service Weaver」
2024年7月23日 6:30
バックナンバー
この記事の筆者
筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
