コンテナオーケストレーションシステム
「Kubernetes」
前回でも少し触れましたが「2014年、Google社が自社サービスをコンテナ化しており、毎週20億のコンテナを起動していた」こと覚えているでしょうか。これほどまでのスケールになると、様々な問題が出てきます。
システムの運用管理、凄まじい数のコンテナをどのように作成・配置するのか、システムの可用性、スケーリングはどうしていくのか、状態監視をどうするか、などなど。それらの煩雑なタスクやワークフローを自動化してくれるのが「オーケストレーションシステム」といわれる、いわばオーケストラの指揮者のような存在です。今回から3回にわたって、コンテナマネジメントのデファクトスタンダードといわれる「Kubernetes」について紹介します(図1)。

図1:Kubernetesロゴ
Kubernetesを構成する
クラスタとノード
Kubernetesの構成要素には様々な概念や用語が登場しますが、まずは「クラスタ」(Cluster)と「ノード」(Node)に注目します。ノードはアプリケーションを実行しているマシンです。ノード自体は一台の物理サーバもしくは仮想マシンと理解してください。
ノードは、用途によってコンテナの実行ホストを提供する「ワーカーノード」(Worker Node)と、それを管理する「マスターノード」(Master Node)に分かれます。Kubernetesでは、異なる役割を持つノードの「集まり」をクラスタという形で管理します。クラスタ内には少なくとも1つ以上のマスターノードと1つまたは複数のワーカーノードが存在します(図2)。
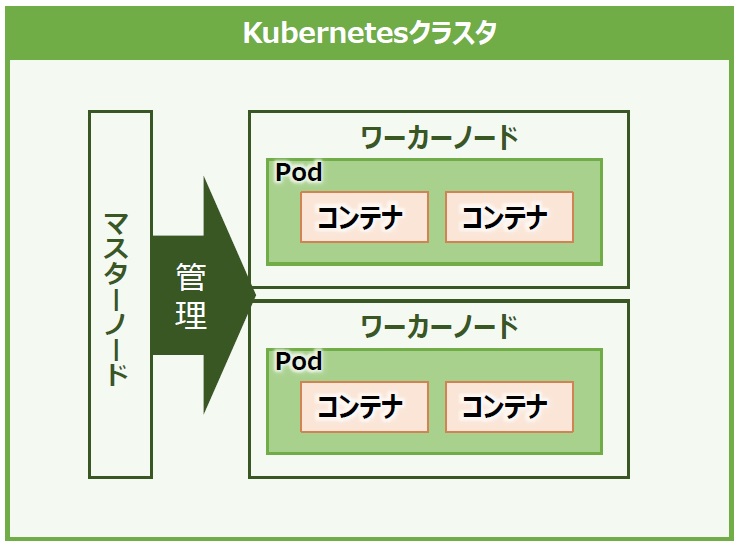
図2:Kubernetes クラスタの概要
このクラスタを構成することで「高可用性」と「負荷分散」を実現できます。
Kubernetesの高可用性は、クラスタ内にあるコンテナなどのコンポーネントに障害が発生した場合、当該コンテナを自動で再起動させたり、他のノードでコンテナを起動させ、故障したコンテナが実行していた処理を引き継がせたりと、事前に定義した状態を維持します(Self-Healing、図3)。
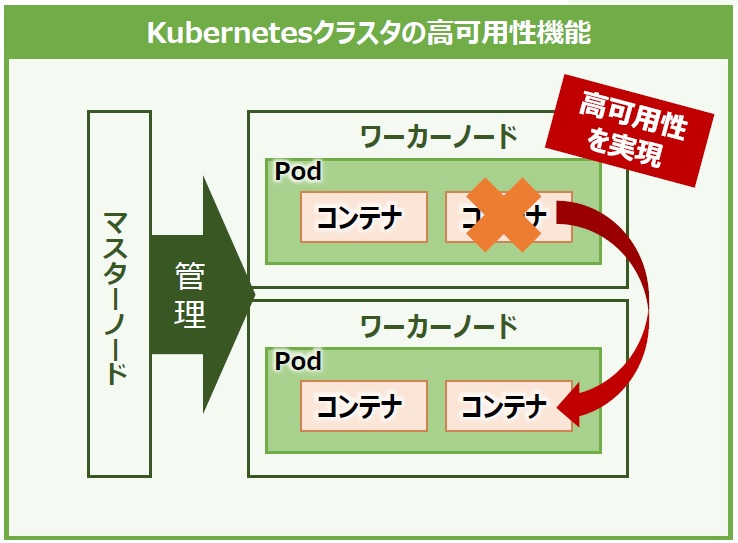
図3:Kubernetes のコンテナ高可用性機能
一方、負荷分散は特定のノードに処理が集中しないように、ノード間で負荷を自動で分散します。これにより、クラスタ内のシステムリソースを効率よく運用できるようになります(図4)。
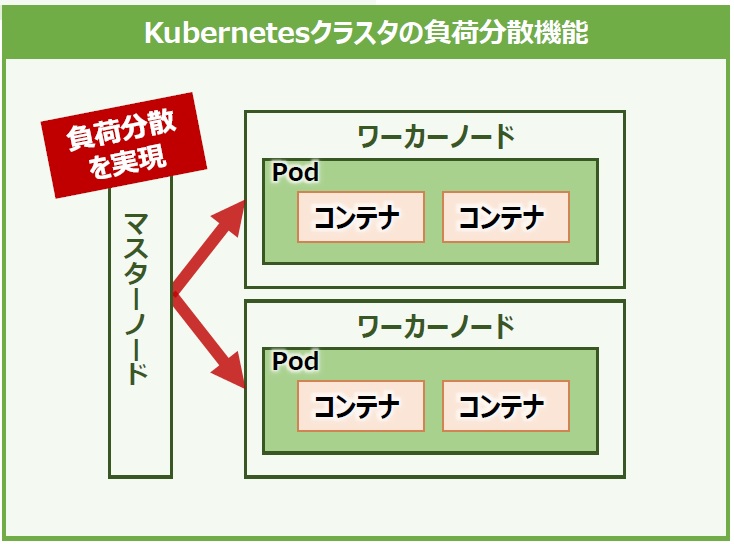
図4:Kubernetes のコンテナ負荷分散機能
※注:Podについては今後の回で詳しく解説しますが、コンテナの本体に該当する部分です。Podはコンテナの集合体で、Podの中には少なくとも1つ以上のコンテナ(コンテナエンジンにDockerを利用する場合はDockerコンテナ)が存在します。KubernetesではPodの単位でコンテナをデプロイします。
これらのクラスタの構成要素は、各ノードに「コンポーネント」という形で配置されます(図5)。
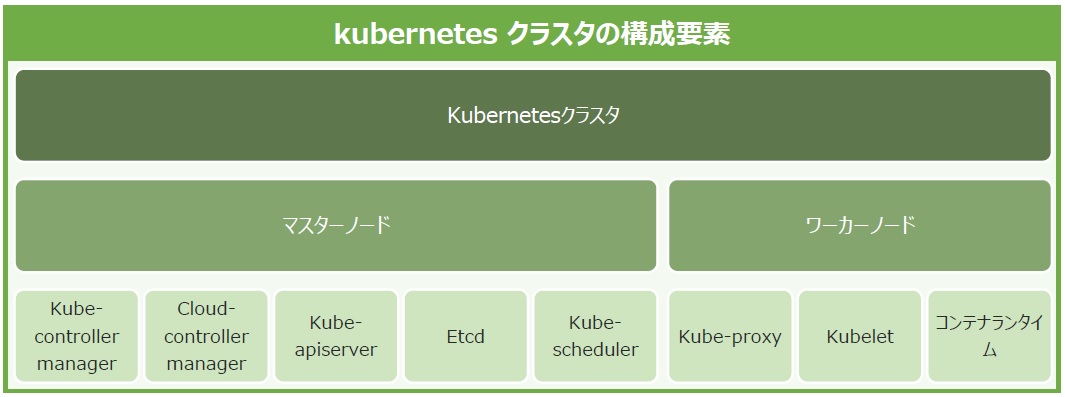
図5:Kubernetes クラスタの構成要素

マスターノードとは
ここでは、マスターノードに焦点を当てて解説します。マスターノードはクラスタ内にあるワーカーノードとPodを管理します。
Kubernetesには、クラスタ機能の提供に必要なものとしてコンポーネントと呼ばれるプロセスが実行されますが、その中でもマスターノードで実行されるコンポーネントをマスターコンポーネントと言います。そして、マスターノードはクラスタ全体を管理するために、それぞれ役割を持った複数のマスターコンポーネントによって成り立っているのです(図6)。
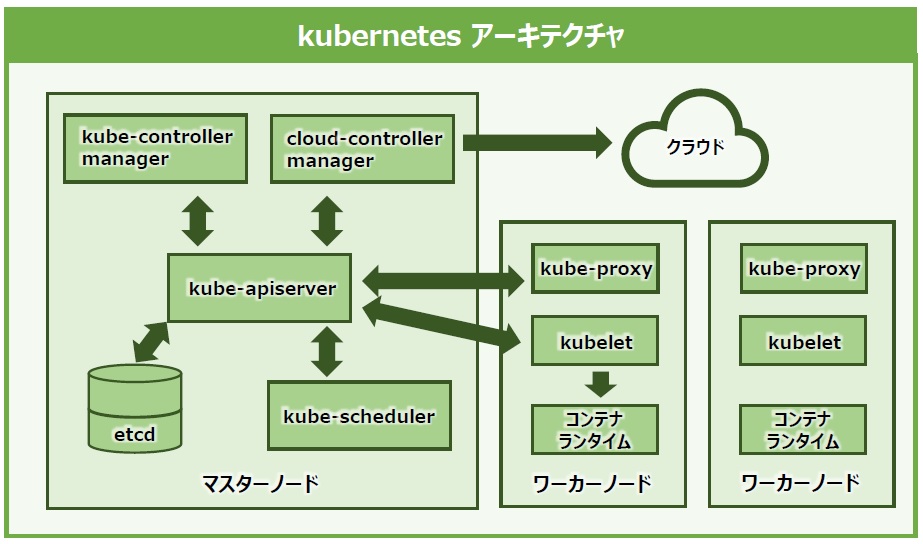
図6:Kubernetesのアーキテクチャー図
マスターコンポーネントは、それぞれを別々のノードで起動させることもできますが、マスターコンポーネントだけを同じノードで全て実行させる方法が推奨されています。マスターコンポーネントはそれぞれが密接に連携してクラスタを管理しており、バラバラに配置すると、あるマスターコンポーネントが実行されているノードに物理的な障害が発生した場合、連携が取れなくなりクラスタの管理機能が停止してしまう恐れがあるからです。
そのため、クラスタの稼動継続力(可用性)を高めたい場合は、マスターコンポーネントをそれぞれ1セットとして起動させたマスターノードを複数用意すると良いでしょう。マスターノードとマスターコンポーネントはセットで覚えてください。
●API Server
「kube-apiserver」(以下、以降はapiserver)は、ひと言で説明すると「クラスタ内の全ての操作の窓口」になるマスターコンポーネントです。外部からクラスタを操作する窓口となるAPI(アプリケーションプログラミングインタフェース)を公開しており、管理者はAPIを通じてKubernetesをコントロールしていきます(図7)。
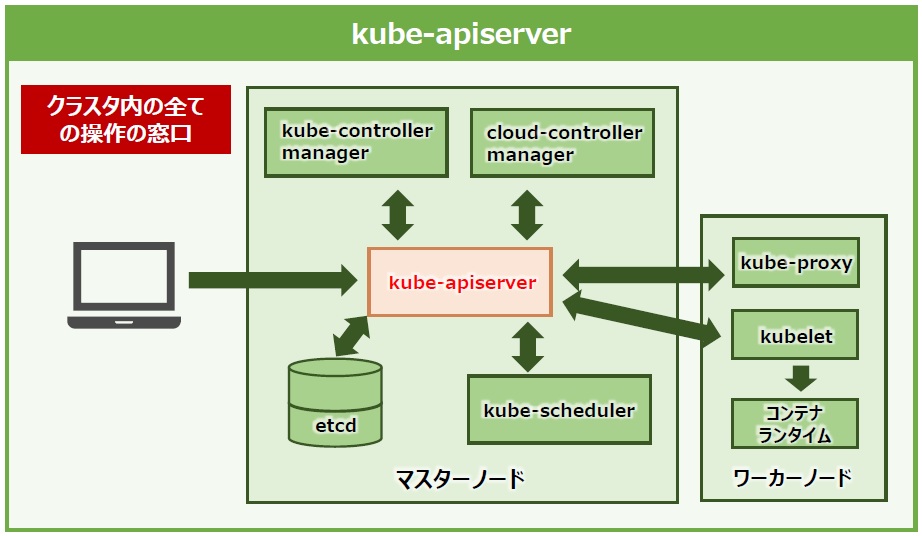
図7:kube-apiserver
「外部からAPIを通してクラスタを操作できるのは危険では?」 と思われますが、Kubernetesはapiserverを通してクラスタを操作する際に、ユーザ名や認証情報をリクエストと一緒に送る仕組みになっているのです。そして、apiserverはユーザ名や認証情報が正しいを照合する「認証」と、受信した操作リクエストが実行可能な権限を持つユーザによるものかを照合する「認可」の役割も備えています。
さらに、apiserverの凄いところは認証認可に留まらず、リクエストの中身を確認して受け入れるかどうかを制御する「入力制御」の役割も担います。事前に指定した条件に沿わないリクエストはブロックしたり、リクエスト内容の一部の変更を行ったりするのです(図8)。

図8:kube-apiserverのリクエスト制御イメージ
●etcd
「etcd」は、ひと言で説明すると「クラスタ情報の保管庫」となるコンポーネントです。Kubernetesクラスタに関する全情報(ノードやPod、構成、アカウントやロールなど)を保存します。ノード情報を取得するリクエストが実行されたとき、表示される情報はapiserverがetcdと直接やり取りをして引っ張ってきます。
Kubernetesは多数のノードをクラスタとして管理するため、ノード自体の障害やノード間を繋ぐネットワークに障害が起こってもシステムの継続稼動が求められます。これはetcdも同様です。etcdは分散された多数のノード間でデータをレプリケート(複製)して保管することに適しており、マスターノードとマスターコンポーネントのセットが複数あっても一貫してクラスタ情報を保つことができる強みがあります(図9)。
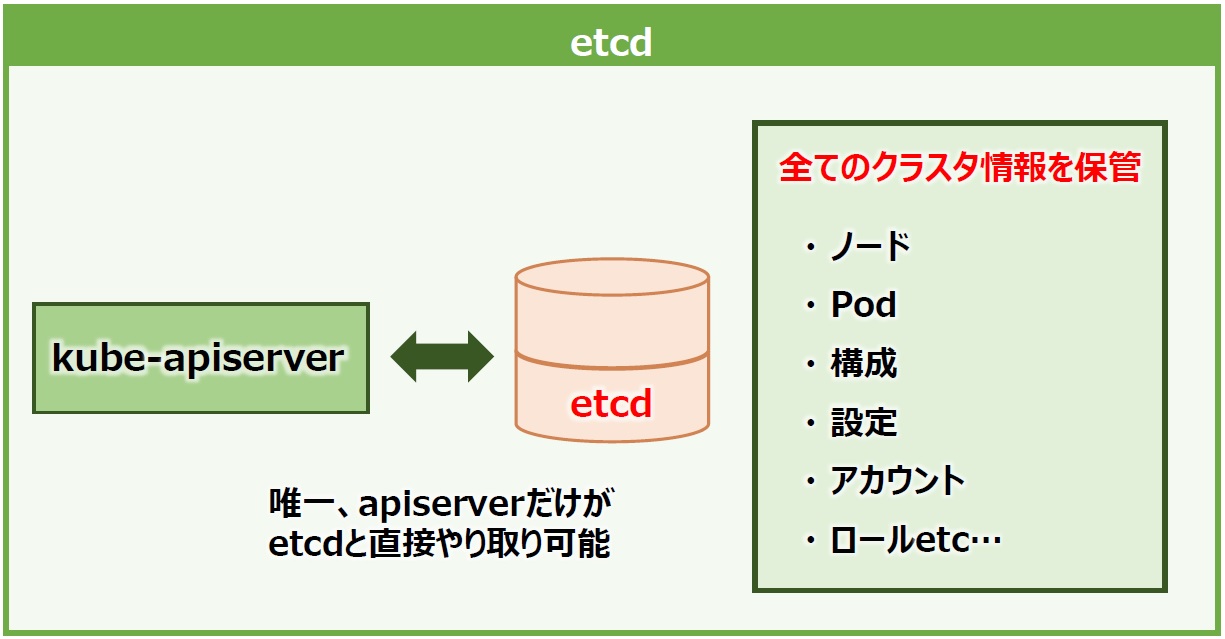
図9:ectdの概要
●Scheduler
「kube-scheduler」(以下、scheduler)は「Podの配置決め」を行うコンポーネントです。Podが新しく作成され、どのノードにも配置されなかった場合、schedulerがそれを検知して適切なノードに配置します。このとき、schedulerは、どのPodをどのノードに配置するかのみを担当し、実際にPodを作成するわけではないことに注意してください。
では、どのようにPodの配置先を決めているかというと、基本的にPodが各ノード間で偏りが出ないように配置します。また、Podにリソース要件(CPUやメモリ量)などが設定されている場合は、要件を満たすノードを探して配置します。
例えば、3つのノードと1つのPodがあるとします。Podはリソース要件として5CPUを設定しており、それぞれノードAは4CPU、ノードBは10CPU、ノードCは15CPUのリソースを持ちます。最初に、schedulerはPodの要件を満たさない4CPUのノードAを配置先候補から外します。次に、Podをノードに配置した際の空きリソース量が大きいノードを計算し、ノードCの方がノードBよりPod配置後の空きリソース量が最も多いため、最終的にノードCにPodを配置します。これらのステップをそれぞれ「フィルタリング」「スコアリング」と言います(図10)。schedulerによる配置は、リソース量以外にも様々な条件を指定できます。
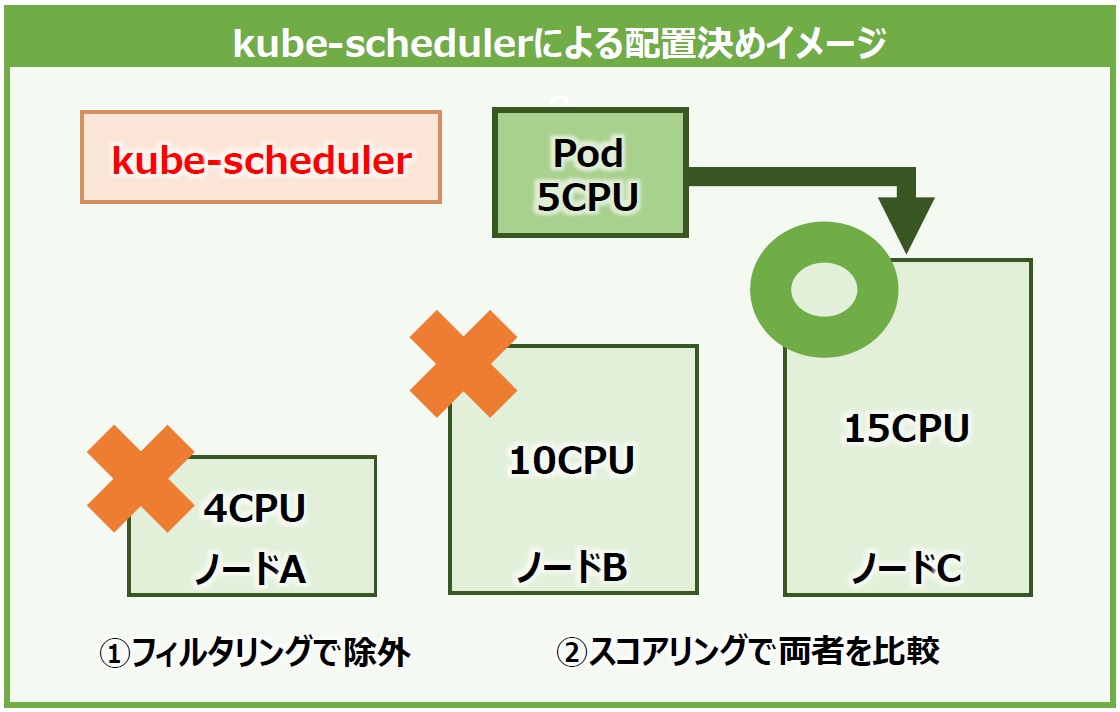
図10:kube-schedulerによるPod配置の決定イメージ図
●Controller Manager
「kube-controller-manager」(以下、controller-manager)は、様々な「コントローラ」をまとめて実行するコンポーネントです。コントローラとは、Kubernetesのコンポーネントなどの状態を監視し、必要な対応を実行するプロセスのことです。
例えば、ノードの状態を監視するノードコントローラは、apiserverを通じて決められた間隔でノードのステータスを確認します。もし、あるノードに問題が発生し、継続してステータス確認に失敗すると、そのノードに配置されているPodをscheduler経由で正常なノードに再割り当てします。ステータス確認に失敗したノードはschedulerの配置候補の対象から外されます。
ノードコントローラの他にも様々なコントローラがあり、controller-managerは「様々なコントローラをまとめて実行」します。コントローラは個別のプロセスですが、それらが1つの実行ファイルに纏められてcontroller-managerとして単一のプロセスで実行されます(図11)。
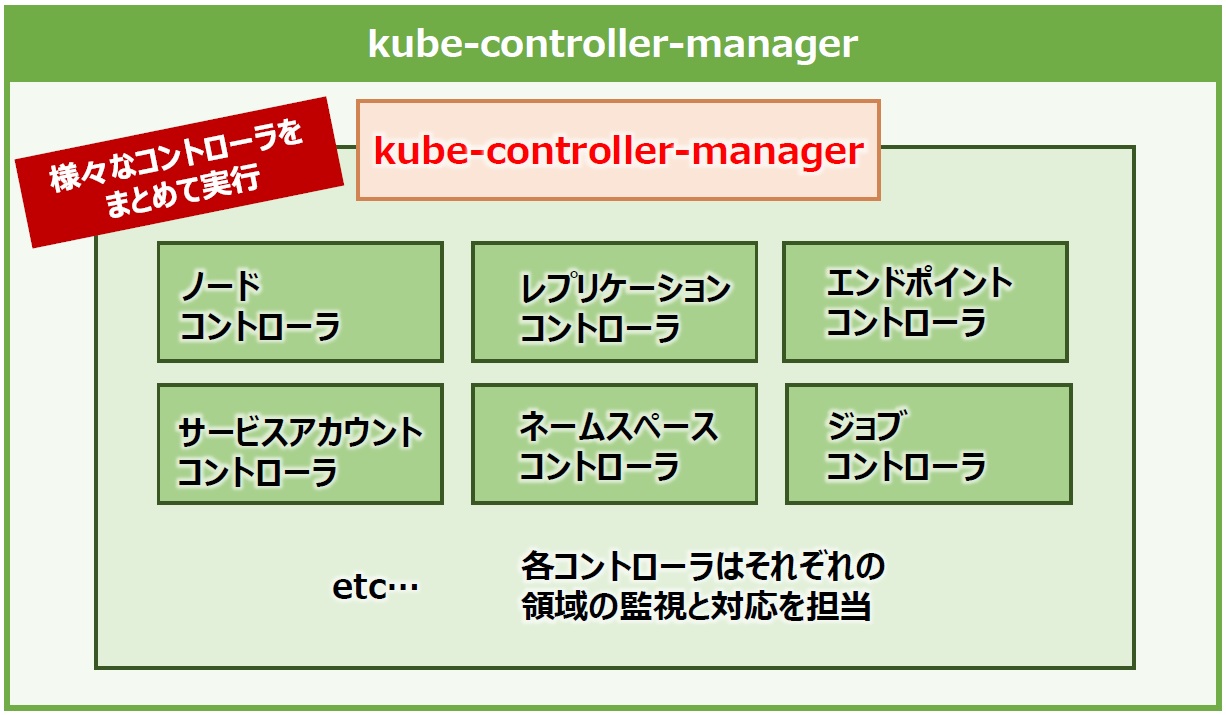
図11:kube-controller-managerは配下のコントローラ群をまとめて実行・管理
●Cloud Controller Manager
「cloud-controller-manager」(以下、ccm)は「Kubernetesとパブリッククラウドを中継」するコンポーネントです。
ccmはKubernetesで使用したいリソースと実際にクラウドで使用しているリソースを連携します。例えば、パブリッククラウドの仮想マシンを利用してKubernetesを実装したとします。その際にクラウドのサービスで提供されているロードバランサーが必要になった場合、クラウド上で実際にロードバランサーを作成し、Kubernetesに関連付ける必要があります。
しかし、本来Kuberntesにはパブリッククラウドを操作する機能はありません。そこでccmはKubernetesがやりたいことをパブリッククラウドとの間に入り操作の指示を中継することで、Kubernetes上の情報とパブリッククラウド上のリソースとの整合性を保ちます。apiserverの代わりにクラウドとの第一窓口になってくれるわけです(図12)。

図12:Kubernetesクラスタとパブリッククラウドとの中継役cloud-controller-manager
様々なマスターコンポーネントがあって混乱しそうですが、それぞれの役割や違いをしっかりと理解しておきましょう。

ワーカーノードとは
ワーカーノードは、実際にPodを動作させるためのノードです。Podとノードコンポーネントで成り立っており、マスターノードにより管理されます。それぞれのノードコンポーネントは全てのワーカーノードで実行されるので、マスターコンポーネントと同様にセットで覚えておきましょう。
●kubelet
「kubelet」は「エージェント」の役割を持つコンポーネントです。各ノードで動作するKubernetesのエージェントで、Podの起動や管理を担います。schedulerからのPod配置指示をapiserver経由で受け取り、コンテナランタイム(後述)を操作してワーカーノード上にPodを作成します。そしてPodやノードの状態を監視してapiserverにレポートを送信します(図13)。
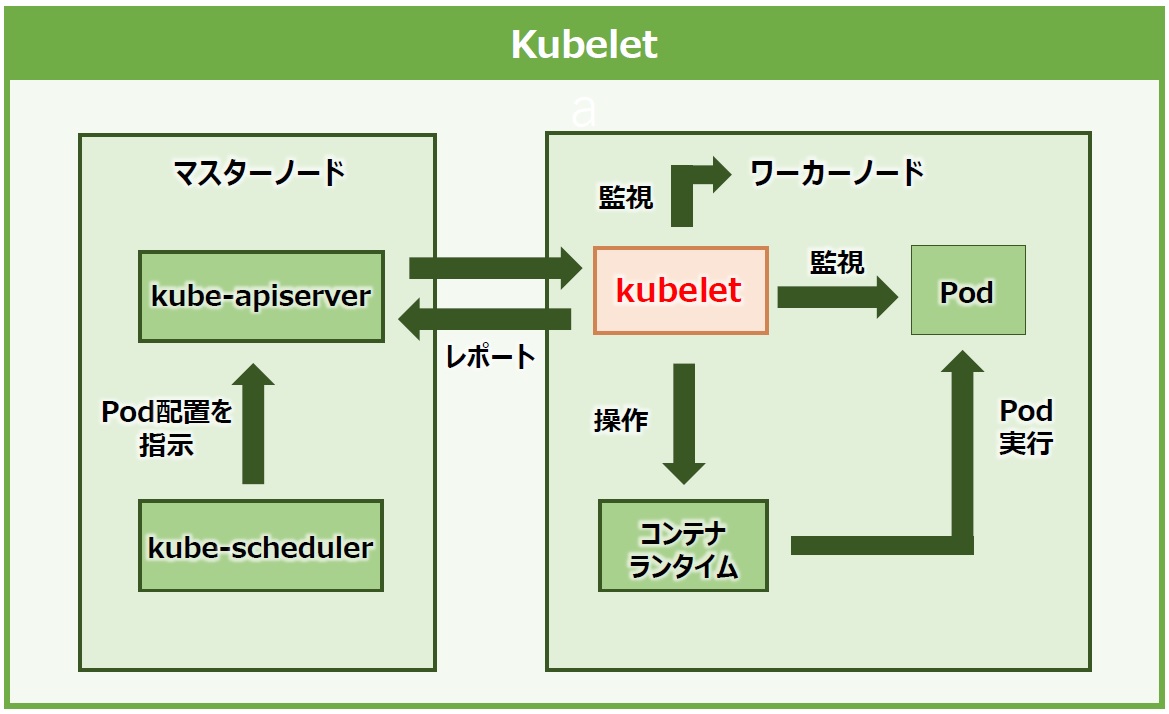
図13:Worker Nodeを監視しMasterに報告するエージェントkubelet
●Kube Proxy
「kube-proxy」は「ネットワーキングと負荷分散をサポート」するコンポーネントです。各ノードで実行され、内部的にはLinuxカーネルのiptablesが利用されています。iptablesは主に通信の許可や遮断の機能と、受信した通信の送信先アドレスを変換し転送する機能などを持ちます。kube-proxyはこれらを使って通信をPodへ転送するためのノード内のネットワークルールをメンテナンスします(図14)。

図14:kube-proxyによる通信転送
また、kube-proxyは今後の回で解説するserviceの機能の一部を実装しています。serviceはクラスタIPという仮想的なIPで負荷分散をします。
具体的には、PodはそれぞれIPアドレスで通信しますが、コンテナの節で解説したようにPod(コンテナ)も起動や削除を繰り返すため、その宛先も常に変わっていきます。そのためPodと通信するにはクラスタIPを挟み、serviceが仲介となり各Podに通信を転送します。クラスタIPの情報さえ知っていれば、PodのIPアドレスがどんなに変わっても通信を振り分けてくれるということです。
●コンテナランタイム
「コンテナランタイム」は、ワーカーノードでコンテナを実行するコンポーネントです。kubeletから受けた指示を元にコンテナのイメージ取得から実行までを行います。コンテナランタイムは「高レベルランタイム」と「低レベルランタイム」の2層に分かれています(図15)。
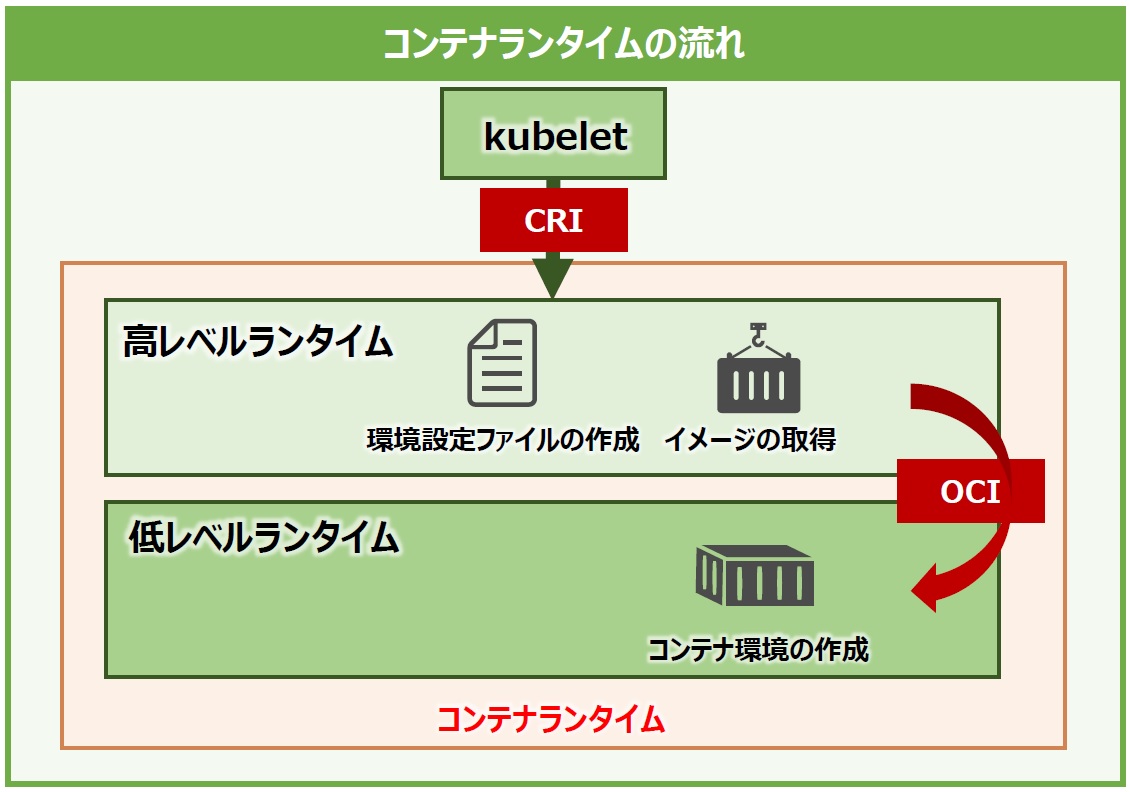
図15:コンテナランタイムの構造
高レベルランタイムは、主にコンテナのイメージを取得し、実行するコンテナ環境の設定ファイルなどを作成します。kubeletからCRI(Container Runtime Interface)というインターフェイスで呼び出されますが、CRIには高レベルランタイムで行うイメージ取得やコンテナ環境の設定などの定義情報が含まれています。
低レベルランタイムは、設定ファイルを元に環境の作成やコンテナの実行を行います。低レベルランタイムはOCI(Open Container Initiative)に準拠した仕様で高レベルランタイムから呼び出され、高レベルランタイムから受け取った情報を元にコンテナ環境を作成します。 OCIは低レベルランタイムの標準仕様で、設定ファイルを元に作られるNamespaceやcgroupなどの仕様が定められています。
コンテナランタイムには様々な種類のソフトウェアがあり、セキュリティや機能の多様性、開発の活発さなどの違いがあります。
高レベルランタイムには、DockerやDockerの機能から独立した「containerd」、Kubernetesに使われることを前提に作られた「CRI-O」、低レベルランタイムの機能も備えた「rkt」などがあります。
低レベルランタイムには、Linuxのシステムリソースを隔離するnamespaceやcgroupの機能を利用し、Dockerの標準ランタイムとして搭載されている「runc」、セキュリティを重視したGoogleの「gVisor」、軽量の仮想マシンを立ち上げ、隔離を重視した「Kata Containers」が存在します。
Kubernetesはこれらのコンテナランタイムをすべてサポートするため、環境に合ったコンテナランタイムを選択できるのです。このようなサポートの広さもKubernetesの人気の1つかもしれません。

Ingress
ワーカーノードでネットワーキングに触れたので「Ingress」についても解説しておきます。
Ingressはクラスタ外部からクラスタ内に通信するためのURLを提供し、Serviceにロードバランシングするオブジェクトです。外部のクライアントはこのURLを通じてServiceやPodへアクセスできるようになります。Ingressには、クラウドやオンプレミスなどのクラスタ外部のロードバランサーを使用する形式と、クラスタ内部にIngress用のPodを起動する形式とがあります。
また、IngressにはIngressControllerという専用のコントローラがありますが、これはマスターノードの項で解説したcontroller-managerで実行される他のコントローラと違い、自動で実行が開始されない点に注意が必要です。
そのため、使用するIngressリソースを作成するだけでは十分でなく、Ingress機能を利用するには個別にIngressControllerを用意する必要があります。IngressControllerには各パブリッククラウドのロードバランサーサービスと連携するものやIngress-nginxなどがあります。これらのIngressControllerを用いることで通信をServiceへルーティングできるようになります(図16)。
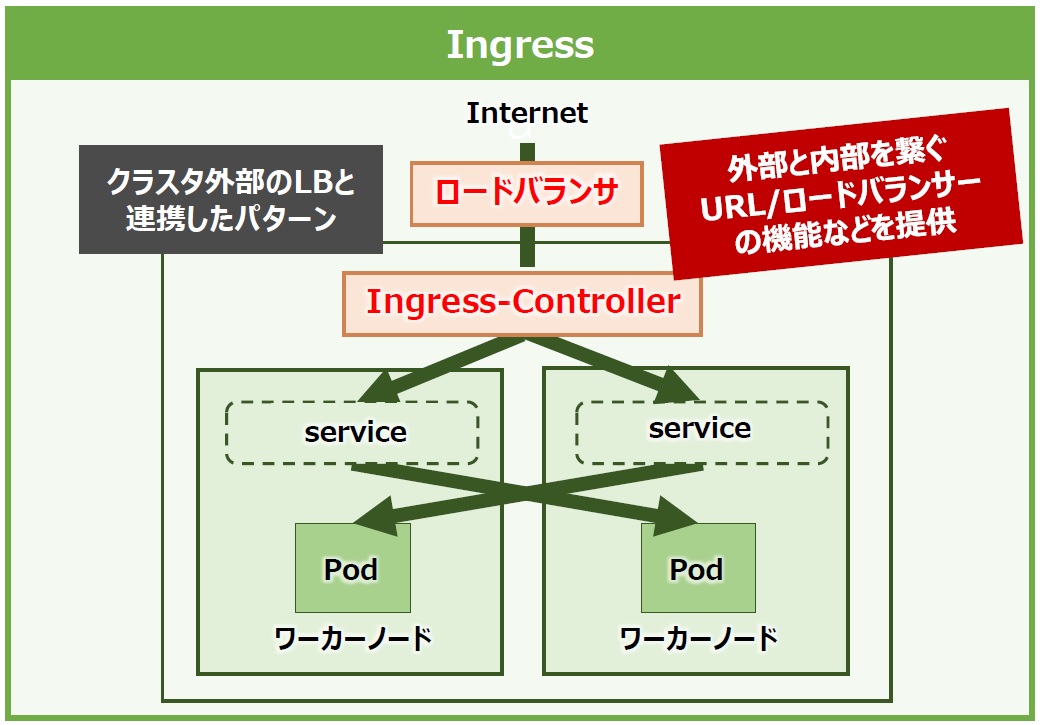
図16:Ingressの役割
なお、Ingressには負荷分散やSSL/TLS終端の機能や、Serviceに名前ベースの仮想ホスティングを構成する機能などがあります。ここでは詳細に触れませんが、様々な機能が備わっていることを知っておきましょう。

おわりに
今回は、コンテナオーケストレーションシステムの代表格である「Kubernetes」について、その構成要素を紹介しました。Kubernetesは、クラスタ全体を管理統括するマスターノードと、実際にコンテナを動かすワーカーノードに分かれて稼動するコンテナのオーケストレーションシステムだということを覚えておいてください。
次回も、引き続きKubernetesについて解説していきます! 今回だけでは語り尽くせないKubernetesの中身をもっと深く掘り下げて紹介します。次回もお楽しみに!

この記事をシェアしてください
バックナンバー
この記事の筆者

Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
