テスト2:Dockerの仮想Disk領域を別の物理ディスクに置き換える
テスト2:Dockerの仮想Disk領域を別の物理ディスクに置き換える
前回の記事に対して、読者の方から「Dockerコンテナが更新する仮想Diskが利用するスパースファイルの領域を、ディスク領域に変更するとディスクアクセス速度が改善される」との情報をいただいたので、早速試してみたい。具体的には、Dockerコンテナの更新データを格納するスパースファイルの代わりに、専用の物理ハードディスクを割り当てることで性能が改善されるかを検証する。
今回のテスト環境の構築では、仮想Disk領域の変更を行うが、その際にはDocker環境のファイルシステムを再構成する必要がある。実際にはDockerのサービスを停止した状態で/var/lib/docker以下のファイルを全て削除し、コンテナイメージを全て削除することとなる。実際に行う時は必要なデータをバックアップしたのち、クリーンアップした状態で環境の構築を実施するよう注意して欲しい。手順を以下に示す。
- 現在のDisk構成を確認
LoopbackデバイスにDockerのDataspaceが存在していることがわかる。[root@host_server ~]# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 931.5G 0 disk ├─sda1 8:1 0 500M 0 part /boot └─sda2 8:2 0 931G 0 part ├─centos-swap 253:0 0 3.9G 0 lvm [SWAP] └─centos-root 253:1 0 927.1G 0 lvm / sr0 11:0 1 1024M 0 rom loop0 7:0 0 100G 0 loop └─docker-253:1-1287-pool 253:2 0 100G 0 dm └─docker-253:1-1287-base 253:3 0 10G 0 dm loop1 7:1 0 2G 0 loop └─docker-253:1-1287-pool 253:2 0 100G 0 dm └─docker-253:1-1287-base 253:3 0 10G 0 dm - 空のディスクを追加(/dev/sdb、/dev/sdc)
- fdiskコマンドでパーティションを作成する(/dev/sdb1に990GB、/dev/sdb2に10GBとした)
- Docker上の必要となるコンテナやイメージは全てexportする
- Dockerサービスを停止する(systemctl stop docker)
- Dockerのコンテナやイメージが格納されている/var/lib/docker/以下を全部削除する(rm –rf /var/lib/docker/*)
- /etc/sysconfig/docker-storageファイルのDOCKER_STORAGE_OPTIONSに作成したパーティションを割り当てる
DOCKER_STORAGE_OPTIONS="--storage-opt dm.datadev=/dev/sdb1 --storage-opt dm.metadatadev=/dev/sdb2" - Dockerを起動(systemctl start docker)
- ディスク割り当て後のDisk構成を確認
これでスパースファイルをloopbackデバイスでマウントする状態が解消され、物理デバイスが割り当てられた状態となった。[root@host_server ~]# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 931.5G 0 disk ├─sda1 8:1 0 500M 0 part /boot └─sda2 8:2 0 931G 0 part ├─centos-swap 253:0 0 3.9G 0 lvm [SWAP] └─centos-root 253:1 0 927.1G 0 lvm / sdb 8:16 0 931.5G 0 disk ├─sdb1 8:17 0 920G 0 part │ └─docker-253:1-3221831217-pool 253:2 0 920G 0 dm │ └─docker-253:1-3221831217-base 253:3 0 10G 0 dm └─sdb2 8:18 0 11.5G 0 part └─docker-253:1-3221831217-pool 253:2 0 920G 0 dm └─docker-253:1-3221831217-base 253:3 0 10G 0 dm sdc 8:32 0 931.5G 0 disk sr0 11:0 1 1024M 0 rom
ここからは余談となるが、筆者の環境(CentOS 7.1 + Docker 1.5.0)で物理デバイスを割り当てる際に問題が発生した、他の環境でも同様の事象が発生することも考えられる為、情報を共有しておきたい。
Dockerのmetadata領域に1TBのDiskを割り当てようとするとエラーが発生する
先に紹介した手順では、/dev/sdbの領域に990GBと10GBの領域を割り当ててDockerを起動している。当初の予定では/dev/sdbをdataに、/dev/sdcをmetadata領域に割り当てようとしていたが、その際に今回のエラーに直面した。ここでは既存のDockerのサービスは停止しており、データも存在していないものとする。
/dev/sdbをdataに、/dev/sdcをmetadataとして割り当てDockerを起動すると、以下のようなエラーとなる。
[root@host_server ~]# docker -d --storage-opt dm.datadev=/dev/sdb --storage-opt dm.metadatadev=/dev/sdc
INFO[0000] +job serveapi(unix:///var/run/docker.sock)
INFO[0000] Listening for HTTP on unix (/var/run/docker.sock)
FATA[0000] Error running DeviceCreate (CreatePool) dm_task_run failed
/var/log/messagesには、割り当てたDiskのセクタが多すぎる旨のログが出力されていた。
kernel: device-mapper: thin: Metadata device sdc is larger than 33292800 sectors: excess space will not be used.
Dockerのmetadata領域に、Diskの先頭セクタを利用したパーティションを割り当てようとするとエラーとなる
割り当てられるセクタに上限があることが上の事象からわかったので、次に最大割り当て可能セクタ以下の領域をmetadataに割り当てることにした。具体的には/dev/sdcにパーティションを作成し、先頭セクタから10GB分を/dev/sdc1(metadata用)に、残りの領域を/dev/sdc2(data用)に割り当て、Dockerを起動する。
[root@host_server ~]# lsblk /dev/sdc
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sdc 8:32 0 931.5G 0 disk
├─sdc1 8:33 0 10G 0 part
└─sdc2 8:34 0 921.5G 0 part
そうすると、以下のエラーとなった。
[root@host_server ~]# docker -d --storage-opt dm.metadatadev=/dev/sdc1 --storage-opt dm.datadev=/dev/sdc2
INFO[0000] +job serveapi(unix:///var/run/docker.sock)
INFO[0000] Listening for HTTP on unix (/var/run/docker.sock)
FATA[0000] Error running DeviceCreate (CreatePool) dm_task_run failed
この際、/var/log/messagesには以下のログが出力されていた。
kernel: device-mapper: block manager: superblock validator check failed for block 0
kernel: device-mapper: thin metadata: couldn't read superblock
kernel: device-mapper: table: 253:2: thin-pool: Error creating metadata object
kernel: device-mapper: ioctl: error adding target to table
ログの内容からは、スーパーブロックのバリデートチェックが失敗してmetadataオブジェクトの作成に失敗しているように見える。対処法としては、実際の手順として前述したようにmetadataに割り当てる領域を「Diskの終端を含みつつ環境の最大割り当て可能セクタ以下のパーティション」とすることで、エラーを回避できることが判明した。
前述の問題を解消し、ディスクが割り当てられた状態でテスト1のコンテナ構成を用意してテストを実施すると、表5の結果が得られた。
表5:テスト2の結果
| 作業 | 1分間のオペレーション | 平均(ミリ秒) | 中央値(ミリ秒) | 90%Line(ミリ秒) | 最小値(ミリ秒) | 最大値(ミリ秒) | Error% | スループット | KB/sec |
|---|---|---|---|---|---|---|---|---|---|
| アクセス | 2000 | 9474 | 3346 | 32695 | 13 | 112310 | 5.67 | 18.3 | 82.9 |
| ログイン実行 | 2000 | 1590 | 1260 | 3300 | 8 | 9923 | 5.67 | 18.3 | 110.2 |
| Projectへ遷移 | 2000 | 10109 | 4138 | 33039 | 22 | 112338 | 5.65 | 18.3 | 97.6 |
| チケット作成 | 2000 | 1507 | 1179 | 3176 | 11 | 10041 | 5.65 | 18.3 | 95.0 |
| 平均 | 2000 | 5670 | 2480.75 | 18052.5 | 13.5 | 61153 | 5.66 | 18.3 | 96.43 |
テスト2で取得できたiostatの最大値
avg-cpu: %user %nice %system %iowait %steal %idle
46.43 0.00 5.65 9.43 0.00 38.49
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sdb 0.00 277.33 2.33 127.00 9.33 5364.00 83.09 1.62 12.54 7.29 12.64 5.88 76.07
dm-2 0.00 0.00 2.33 391.67 9.33 5305.33 26.98 4.29 10.94 7.29 10.96 1.72 67.77
dm-4 0.00 0.00 2.33 392.00 9.33 5508.00 27.98 4.47 11.38 7.29 11.41 1.94 76.33
テスト1に比べ待ち時間(90%Line)とエラー率のパフォーマンスが50%程度改善されていることが見て取れる。Writeの流量も増えており、こちらも良い傾向である。しかし全体で見るとまだ待ち時間が多く、少ないながらエラーも発生していることから改善の余地があると考える。
テスト3:コンテナで利用する一部のファイルをホストOSへ切り出す
本テストはコンテナ内の一部のファイルをホストOS側で管理する仕組みを試してみる。本項で行った環境への変更は全て戻し、テスト1の最初の時点の環境へとロールバックを行っている。
Dockerを利用する上で、Dockerが利用する各ファイルシステムが差分更新となっているため、パフォーマンスが気になるという声があった。今回のテストは、差分更新のファイルシステムを回避することが可能かの検証を考えている。
Dockerの機能として、外部デバイスや領域をコンテナからマウントして利用する機能が提供されている。
その機能を活用し、DiskIOが多いと考えられるRedmineのデータ部分やMySQLのDBのファイルシステム部分をベースOS側に配置してみる。
ホスト側で保存する領域(ディレクトリ)を作成
Redmineのファイル保存領域、およびMySQLのDBファイルの保存場所を作成する。
[root@host_server ~]# mkdir -pv /opt/redmine/files
[root@host_server ~]# mkdir /opt/redmine/mysql
コンテナ起動
Redmineコンテナを起動する。一部のファイルをホスト側に保存し利用するため、「-v」オプションを使って先の手順で作成した保存領域を指定する。テスト1と同条件で行ったテストの結果を表6に示す。
[root@host_server ~]# docker run --name=redmine -p 8080:80 -d -v /opt/redmine/files:/redmine/files -v /opt/redmine/mysql:/var/lib/mysql sameersbn/redmine:2.5.0
表6:テスト3の結果
| 作業 | 1分間のオペレーション | 平均(ミリ秒) | 中央値(ミリ秒) | 90%Line(ミリ秒) | 最小値(ミリ秒) | 最大値(ミリ秒) | Error% | スループット | KB/sec |
|---|---|---|---|---|---|---|---|---|---|
| アクセス | 2000 | 53 | 21 | 110 | 10 | 1025 | 0.00 | 10.8 | 50.4 |
| ログイン実行 | 2000 | 112 | 88 | 203 | 38 | 959 | 0.00 | 10.8 | 66.2 |
| Projectへ遷移 | 2000 | 79 | 36 | 169 | 18 | 952 | 0.00 | 10.7 | 59.3 |
| チケット作成 | 2000 | 70 | 41 | 14418 | 1064 | 0.00 | 10.7 | 56.4 | |
| 平均 | 2000 | 78.5 | 46.5 | 156.5 | 21 | 1000 | 0.0 | 10.75 | 58.08 |
テスト3で取得できたiostatの最大値
avg-cpu: %user %nice %system %iowait %steal %idle
51.89 0.04 2.82 2.56 0.00 42.69
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 3.33 0.00 110.67 0.00 4377.50 79.11 1.51 13.67 0.00 13.67 6.62 73.27
dm-1 0.00 0.00 0.00 86.67 0.00 4377.50 101.02 1.66 19.18 0.00 19.18 8.45 73.20
dm-2 0.00 0.00 0.67 12.33 42.67 332.00 57.64 0.08 6.26 0.00 6.59 6.26 8.13
dm-3 0.00 0.00 0.00 18.00 0.00 710.67 78.96 0.12 6.89 0.00 6.89 6.89 12.40
全てのファイルをコンテナに配置していたテスト1と比べて、大幅にパフォーマンスが上がっているのがわかる。平均待ち時間が0.15秒となり、HTTPリクエストエラーも検出されなくなった。さらに若干ではあるが、DiskIOのWriteの値が増えている。これはIOWaitの時間が短くなり、より多くの書き込みが出来るようになったということだろう。
特定のファイルをホストOS内のストレージ領域へ保持させる「-v」オプションを利用した手法は、コンテナのパフォーマンス向上が見込める便利なオプションではあるが、Dockerのメリットでもあるポータビリティが犠牲になる側面を持つ。
通常の利用であれば、コンテナ内で設定や情報が完結しているので、コンテナを起動するホスト端末が変更された場合にもコンテナを移動すれば、今までの環境を再現できる。だが今回のように情報をコンテナ外に出すことによって、コンテナを移設するためには、新たなホスト端末へ同様のパスを作成し、切り出した情報を配置し、コンテナをオプション付きで起動する必要が生じる。
一方でこの方法を利用すれば、誤ってコンテナを削除してしまった場合にもデータの喪失はない。外部ストレージなどを活用すれば堅牢性の確保にも有用だが、コンテナのポータビリティという観点では運用が難しくなり、コンテナの数が増えていくと運用ミスの温床になることが懸念される。
テスト4:コンテナをRedmineとMySQLの2つに分離してみる
今回利用しているコンテナは、一つのコンテナに対してRedmineやMySQLといったサービスが複数入っている状態で稼働している。メンテナンス性を考えると、コンテナは分離したほうが良いというのがDockerコンテナを利用する上での一般的な考え方となっている。
コンテナを分離した場合、コンテナ間はDockerの仮想ネットワークで通信が行われるため、ネットワーク通信によるオーバーヘッドが発生するのでは? と考えた。今回の検証ではコンテナを2つに分離し、パフォーマンスの観点からどのような相違が発生するかを検証する。
コンテナの分離手順
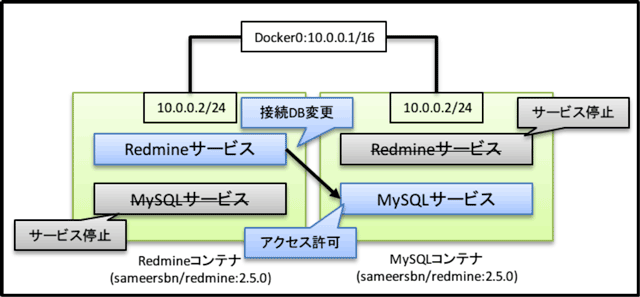
図1:MySQLとRedmineを別のコンテナに分離する
コンテナの分離は、上図のように行った。コンテナは先のテストと同様に「sameersbn/redmine:2.5.0」を利用しており、同じコンテナを別の名前をつけてポートフォワードするコンテナ(Redmine用)とポートフォワードしないコンテナ(MySQL用)を起動する。
[root@host_server ~]# docker run --name=redmine -p 8080:80 -d sameersbn/redmine:2.5.0
[root@host_server ~]# docker run --name=mysql -d sameersbn/redmine:2.5.0
この状態では2つのコンテナともRedmine+MySQLの構成で動いているので、それぞれ片方のサービスを停止した後、DBに対して外部からのアクセス許可を加えRedmineの接続DBの向き先を変更した。
この構成でテストを行い、得られた結果を表7に示す。
表7:テスト4の結果
| 作業 | 1分間のオペレーション | 平均(ミリ秒) | 中央値(ミリ秒) | 90%Line(ミリ秒) | 最小値(ミリ秒) | 最大値(ミリ秒) | Error% | スループット | KB/sec |
|---|---|---|---|---|---|---|---|---|---|
| アクセス | 2000 | 24892 | 12424 | 63000 | 17 | 110880 | 21.68 | 11.1 | 45.4 |
| ログイン実行 | 2000 | 2245 | 1833 | 4712 | 9 | 19814 | 21.68 | 11.1 | 62.7 |
| Projectへ遷移 | 2000 | 24629 | 12890 | 63000 | 84 | 110882 | 20.05 | 11.1 | 53.3 |
| チケット作成 | 2000 | 2118 | 1713 | 4461 | 10 | 18078 | 20.05 | 11.1 | 55.3 |
| 平均 | 2000 | 13471 | 7215 | 33793.25 | 30 | 64913.5 | 20.87 | 11.1 | 54.18 |
テスト4で取得できたiostatの最大値
avg-cpu: %user %nice %system %iowait %steal %idle
23.42 0.00 3.17 13.57 0.00 59.83
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 3.33 0.33 86.00 16.00 3096.33 72.10 1.37 15.92 14.00 15.93 11.32 97.77
dm-1 0.00 0.00 0.33 75.67 16.00 3095.83 81.89 1.39 18.25 14.00 18.26 12.86 97.77
dm-2 0.00 0.00 0.67 94.33 2.67 3076.00 64.81 3.95 41.39 7.00 41.63 9.11 86.57
dm-4 0.00 0.00 0.00 19.33 0.00 1021.33 105.66 1.20 62.28 0.00 62.28 9.83 19.00
dm-5 0.00 0.00 0.67 74.33 2.67 2430.67 64.89 3.08 40.85 7.00 41.16 13.13 98.47
使用しているコンテナ自体はテスト1と同じだが、コンテナを2つに分離した場合にはパフォーマンスが劣化するという結果が得られた。ネットワーク起因によるレスポンス悪化を想定していたが、それに加えて、DiskIOの劣化が顕著であった。iostatの結果を見てもw/sの発行回数が少なく、ディスクビジー状態が平均して高いわりに書き込み流量が少ない結果となった。エラー発生率も1個のコンテナで動作させた場合の2~2.5倍程度になり、性能面だけから見ると、密接に関係している複数のサービスは1つのコンテナに集約した方が良いことがわかる。
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者


筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
