【AIの思考プロセス理解】言語モデルの内部から学ぶ効果的な指示の技術
本記事は、生成AIコミュニティ「IKIGAI lab.」に所属するメンバーが、生成AIに関するニュースを紹介&深掘りしながら、AIがもたらす「半歩先」の未来に皆さんをご案内します。
2025年4月17日 6:30
はじめに
本連載は、生成AIコミュニティ「IKIGAI lab.」で活動している各分野のエキスパートが執筆を担当しています。生成AIの活用がビジネス領域において本格化する中、私たちは理論と実践の両面から、最新の知見に基づいた実践的な情報をお届けしていきます。
言語モデルの特性理解とプロンプト設計
ChatGPTなどの生成AIを活用する際に「こう書けば良い回答が得られる」という表面的なテクニックを集めることに注力している方も多いのではないでしょうか。確かに、そうしたテクニックは即効性があり、一定の成果を出せます。しかし、言語モデルの能力を真に引き出し、複雑なタスクに対応するためには、その裏側で動作する仕組みや学習原理を理解することがはるかに効果的です。
実際、多くのプロンプトガイドが世に出る一方で「なぜ同じ質問でも回答が異なるのか」「単純な指示がなぜ複雑な応答を引き起こすのか」という疑問を感じている方も少なくないと思います。その答えは、言語モデルが内部で持つ「特性」に隠されています。
今回は、最新研究に基づいた言語モデルが持つ6つの特性を明らかにします。自律的な文法学習から知識操作の限界まで、AIの「思考プロセス」とも言える仕組みを理解することで、場当たり的なテクニックではなく原理に基づいた効果的なプロンプト設計が可能になります。これらの知見は、曖昧な回答の削減、複雑な問題の効率的な解決、そして一貫性のある高品質な出力を得るための基盤となるのではないでしょうか。
IT技術者がシステムの内部動作を理解することでより効果的に利用できるように、生成AIもブラックボックスのままではなく、その仕組みを理解することでAIとのコミュニケーションの質が格段に向上すると思います。
※本記事は、言語モデルの研究コンセプト「言語モデルの物理学」の記事をベースに作成しています。
https://joisino.hatenablog.com/entry/physics
- はじめに
- 言語モデルの特性理解とプロンプト設計
- 特性1. 自律的な文法学習:詳細な説明よりも具体的な例を示す
- 特性2. 問題解決の効率性:情報を明確に構造化して提示
- 特性3. 自己認識能力:不確実性を表明するよう促す
- 特性4. 知識の記憶と抽出:モデルが学習した形式に近い質問
- 特性5. 知識操作の限界:複雑なタスクは段階的に指示
- 特性6. 記憶容量とデータ品質:重要情報を明確に強調
- まとめ:原理理解がもたらすプロンプト設計の進化
特性1. 自律的な文法学習:詳細な説明よりも具体的な例を示す
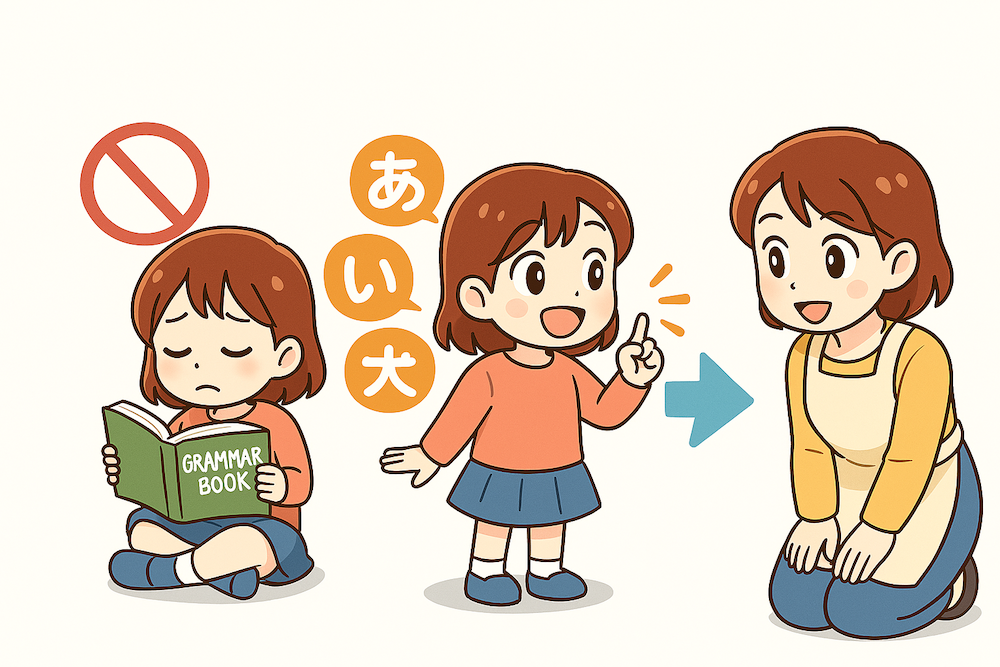
言語モデルは独自の学習能力を持っています。子どもが文法書を読まなくても自然と言葉を習得していくように、言語モデルも正しい文章に多く触れるだけで文法を身につけていきます。
例えば、私たちが外国語を学ぶとき、最初は「これが正しい言い方です」と教わりますが、上達するにつれて「なんとなくこれが正しい気がする」と感覚的に判断できるようになります。言語モデルも同様に、ただテキストを読むだけで、自然と言語のパターンを把握していくのです。
【参考】「Discover Self-Supervised Learning for LLMs」(Coditude Insights)
この特性を知っていると、プロンプト作成では細かい指示よりも的確な例を示す方が効果的だと分かります。言語モデルに手取り足取り教える必要はなく、親が子どもに「このような場面ではこう言う」と例示するように、モデル自身がパターンを把握して適切な回答を生成できるようになります。
(「GPT‑4o image generation」で作成)
特性2. 問題解決の効率性:情報を明確に構造化して提示
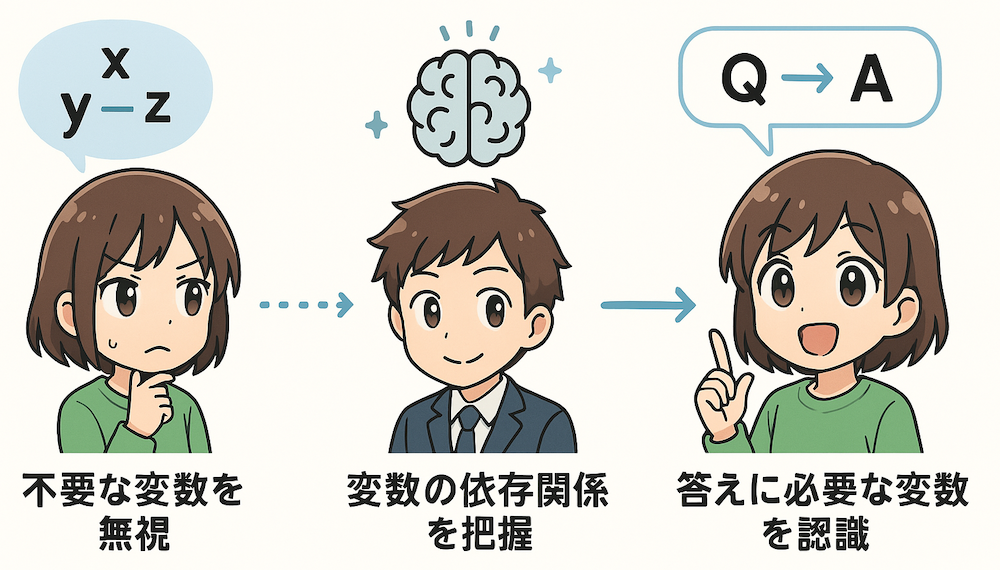
言語モデルの問題解決能力も非常に興味深いです。研究によると、言語モデルは問題文中の不要な変数を自動的に無視し、最短経路で答えにたどり着く傾向があります。これは試行錯誤を重ねる人間の回答方法とは対照的です。
さらに、内部状態の分析から、言語モデルは問題の前提が入力された直後の段階で、すでに変数間の依存関係を把握しています。そして質問文が入力された直後には、回答に必要な変数の集合を認識していることが示されています。
【参考】「Physics of Language Models: Part 2.1, Grade-School Math and the Hidden Reasoning Process」(arXiv 2024年7月29日)
【参考】「Instructing Large Language Models to Identify and Ignore Irrelevant Conditions」(arXiv 2024年3月19日)
これは、ベテランの数学教師が問題を一読しただけで解法の道筋を即座に見抜くようなものです。初学者は試行錯誤を繰り返すのに対し、熟練者はどの情報が重要で、どう組み合わせるべきかを直感的に理解します。言語モデルも同様に問題の核心を素早く見抜き、不要な情報を自然に除外していくのです。
このことから、プロンプトで問題を提示する際は情報を整理して明確に構造化することが有効だと分かります。また、ステップバイステップで考えるよう指示することで、モデルの問題解決プロセスをより引き出せるでしょう。
【参考】「Unlocking Structured Thinking in Language Models with Cognitive Prompting」(arXiv 2024年10月3日)
プロンプト応用例
# 週末旅行のプラン相談
## 1. 旅行の目的
- リラックスできる温泉旅行に行きたい。
## 2. 条件
- **場所:** 東京から電車で2時間以内で行ける場所。
- **期間:** 今週末の土曜日出発、日曜日帰宅(1泊2日)。
- **予算:** 1人あたり3万円以内(交通費、宿泊費、食費込み)。
- **参加者:** 大人2名。
## 3. 希望すること
- 露天風呂がある宿に泊まりたい。
- 地元の美味しいものが食べたい(特に海鮮)。
- あまり混雑していない静かな場所が良い。
## 4. 依頼事項
上記の条件と希望に合う旅行先の候補と、簡単なスケジュール案(例:どこに泊まり、何をするか)を2つ提案してください。
この例では「予算3万円以内(条件)」と「露天風呂付きの宿(希望)」や「海鮮(希望)」がどう両立できるか、「東京から2時間以内(条件)」で「静かな場所(希望)」はどこか、といった依存関係をモデルが効率的に理解し、現実的な候補を探しやすくなっています。
(「GPT‑4o image generation」で作成)
特性3. 自己認識能力:不確実性を表明するよう促す
言語モデルには、自分自身の推論の誤りを認識する能力があることも分かってきました。これは、私たちが計算をしていて「あれ? このやり方で合っているかな?」と立ち止まる瞬間に似ています。
研究によると、算数の問題を間違えたケースの内部状態を分析すると、言語モデルは一度は計算できない変数を計算できると勘違いしますが、その直後には「これは違う」と気づいている兆候が見られるのです。
【参考】「Physics of Language Models: Part 2.2, How to Learn From Mistakes on Grade-School Math Problems (ICLR 2025)」(arXiv 2024年8月29日)
さらに興味深いことに、モデルがまだ1文字も出力していない段階で、その内部状態から後に誤りを犯す可能性を予測できることも示されています。これは人間が問題を解き始める前から「自信がない」と感じる状態に似ています。
【参考】「Self-Correction in Large Language Models」(Communications of the ACM 2025年2月26日)
この特性を活かすには「あなたの回答に確信が持てない場合は、その旨を明記してください」といった指示を出すことが効果的です。こうすることでモデルの内部にある不確実性が表面化し、より正確な回答が得られる可能性が高まります。
プロンプト応用例
# 言葉のニュアンスについての質問
## 依頼内容
最近よく聞く「チルする」という言葉は、具体的にどういう意味で、どんな状況で使われることが多いですか?
## 指示事項(特に重要)
意味や使われ方を説明する際に、**もしその言葉のニュアンスについて、人によって解釈が違う可能性があったり、あなたの説明に完全な自信が持てなかったりする部分があれば、そのことも正直に付け加えて教えてください。** 例えば、「若者言葉なので、世代によっては少し違う捉え方をするかもしれません」や「この解釈が全てではありません」といった形です。
## 期待するアウトプット
「チルする」の意味と使われ方の説明、およびその説明の確実性や解釈の多様性に関するコメント。
この指示では、モデルに「『チルする』のような比較的新しい言葉や俗語に対して解釈の幅や知識の限界(不確かさ)を認識し、それを隠さずに出力する」ように促しています。

(「GPT‑4o image generation」で作成)
特性4. 知識の記憶と抽出:モデルが学習した形式に近い質問
言語モデルが知識をどのように記憶し引き出すかは、図書館の例えで理解できます。膨大な本(知識)があっても、適切な検索システムがなければ情報を見つけるのは困難です。同様に、言語モデルも知識を記憶していても、それを引き出す「検索方法」が学習されていないと利用できません。
研究では、言語モデルは知識を貯蔵できても、質問応答タスクをうまくこなすには事前訓練時に質問応答のデータを関連させる工夫が必要だと分かっています。つまり「図書館の本の内容を知っている」ことと「質問に対して適切な本を見つけて答えられる」ことは別のスキルなのです。
【参考】「Physics of Language Models: Part 3.1, Knowledge Storage and Extraction」(arXiv 2024年7月16日)
そのため、プロンプト設計ではモデルが学習した可能性が高い形式に近い質問の仕方をすることが大切です。例えば、医学の専門知識を尋ねる場合は、一般的な質問よりも医学教科書や論文で見られるような専門的な問いかけの方が、より正確な回答を引き出せる可能性があります。
「あまり効果的でない」指示例
# 質問
冷蔵庫に鶏むね肉とキャベツがあるんだけど、何か美味しいもの作れる?
「効果的」な指示例(学習形式を意識した例)
# 具体的な形式を意識したレシピ検索
## 手元にある主な食材
- 鶏むね肉:1枚
- キャベツ:1/4個
- (基本的な調味料(塩、こしょう、醤油、油など)はあります)
## 作りたい料理のイメージ
- **種類:** 簡単な**炒め物**
- **味付け:** **あっさりした塩味系**
- **用途:** 平日の**晩ごはんのおかず**
## 依頼内容
上記の食材とイメージに合うレシピを1つ、具体的な手順(下準備、調理手順)とともに教えてください。
## 期待するアウトプット
鶏むね肉とキャベツを使った、塩味系の簡単な炒め物レシピ(材料リストと調理手順)。
このように「鶏むね肉とキャベツで何か」と漠然と聞くよりも、「鶏むね肉とキャベツを使った塩味の炒め物」と具体的に指定する方が、モデルは膨大なレシピ知識の中から関連性の高い情報を効率的に検索しやすくなります。

(「GPT‑4o image generation」で作成)
特性5. 知識操作の限界:複雑なタスクは段階的に指示
言語モデルには「知識をそのままの形でしか取り出せず、柔軟な操作や逆検索が苦手だという重要な限界」もあります。
電話帳の例えで考えると、名前から電話番号を調べるのは簡単ですが、電話番号から名前を探すのは(逆引き電話帳がなければ)非常に困難です。言語モデルも「AからBが取り出せる」からといって「BからAが取り出せる」とは限りません。また、生年月日の全体を知っていても、生まれ年だけを取り出すような「部分抽出」も苦手としています。
【参考】「Physics of Language Models: Part 3.2, Knowledge Manipulation」(arXiv 2024年7月16日)
【参考】「Unveiling the Limitations of Large Language Models: The Reversal Curse」(Linkedin 2023年9月26日)
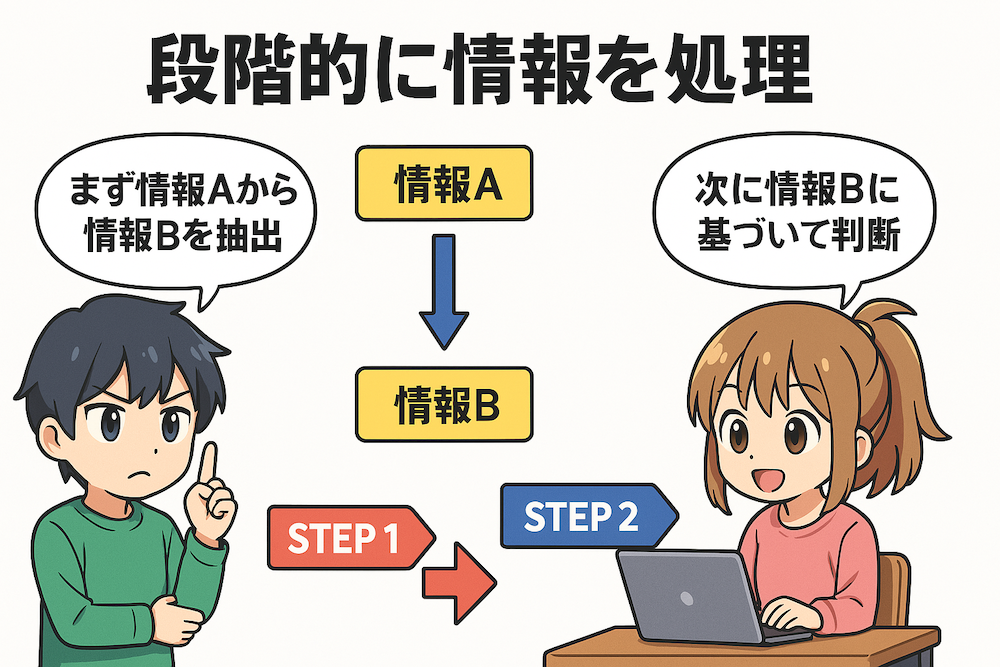
この特性を理解すると、複雑な知識操作を一度に要求するのではなく「まず情報Aから情報Bを抽出し、次に情報Bに基づいて判断してください」といった形で段階的に処理を進めるよう指示すると効果的です。これは複雑な料理のレシピをステップバイステップで伝えるようなものです。
「あまり効果的でない」指示例
以下の買い物リストから、果物だけを選んで、その合計金額を教えてください。
- りんご (150円)
- 牛乳 (200円)
- バナナ (100円)
- パン (180円)
- みかん (50円)
「効果的」な指示例(学習形式を意識した例)
# 元の買い物リスト
- りんご (150円)
- 牛乳 (200円)
- バナナ (100円)
- パン (180円)
- みかん (50円)
# ステップ1:果物だけを選ぶ
まず、上のリストの中から**果物だけ**をリストアップしてください(名前と価格)。
# ステップ2:合計金額を計算する
次に、ステップ1でリストアップした果物の**価格だけを合計**して、合計金額を教えてください。
# 期待するアウトプット
ステップ1で果物のリスト、ステップ2でその合計金額が示されること。
このようにステップを分けて指示することで、モデルは1度に1つの単純な知識操作(まず抽出、次に計算)に集中できるため、エラーを減らし、より正確な結果を出しやすくなります。
(「GPT‑4o image generation」で作成)
特性6. 記憶容量とデータ品質:重要情報を明確に強調
最後に、言語モデルの記憶容量について見てみましょう。これは倉庫の収納効率に例えられます。
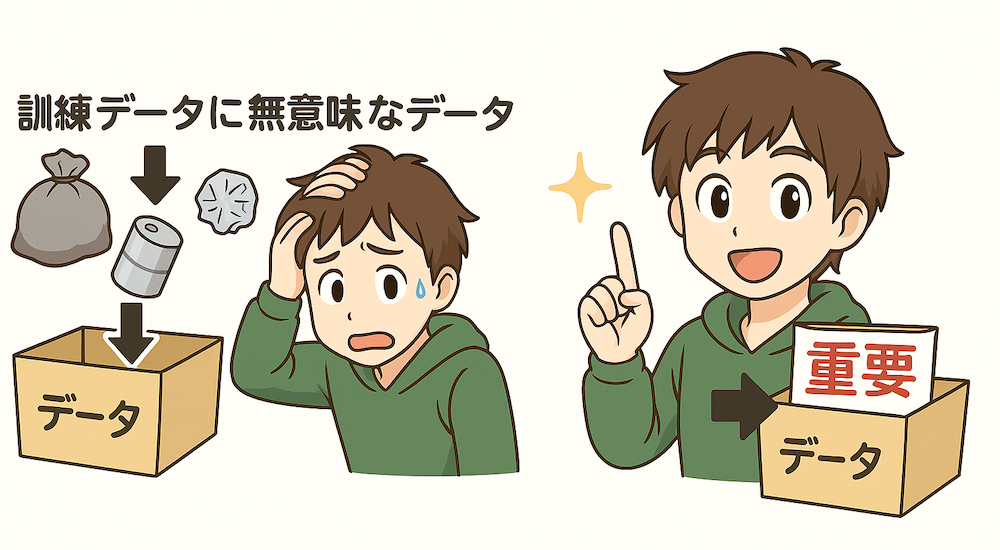
訓練データの質は記憶容量に大きく影響します。これは、整理された物と雑多な物が混ざった倉庫では収納効率が落ちるのと同じです。実験では、訓練データに無意味なデータ(ゴミデータ)を混ぜると記憶容量が大幅に悪化することが分かっています。しかし、重要なデータに「これは重要です」というラベルを付けることで、この悪影響を軽減できることも示されています。例えるなら、倉庫の重要な品物に目立つラベルを貼っておくようなものです。
【参考】「Garbage In, Garbage Out: Why Data Accuracy Matters for AI Models」(sama BLOG)
この知見はプロンプト設計にも応用できます。重要な情報を明確に強調し、余分な情報は削除するといった工夫が有効でしょう。例えば「以下の情報は特に重要です:」という形で情報を提示することでモデルの注意を重要な部分に向けさせ、より質の高い回答を得られる可能性が高まります。
「効果的」な指示例(学習形式を意識した例)
# 予定調整依頼
## 依頼内容
来週、山田さんと打ち合わせを設定したい。
## 希望条件
- 曜日: 火曜日 または 水曜日
- 時間帯: 午後
- 場所: できれば渋谷
## 以下の条件は特に重要です:
- **打ち合わせは、必ず15:00までに終了する必要があります。**
## 依頼事項
上記の希望条件を考慮しつつ、**特に「15時までに終了」という最重要条件を確実に満たす**打ち合わせの日時(曜日と具体的な開始・終了時間)の候補を2つ提案してください。
この指示では「以下の条件は特に重要です:」という明確な「重要ラベル」を使用し、さらに太字で強調することで、モデルに対して「15時までに終了」という条件が他の希望条件よりも優先度が高い、絶対に守るべき制約であることを伝えています。
※「**」で囲まれた文字は太字扱いになり「強調される箇所」と認識されます。
(「GPT‑4o image generation」で作成)
まとめ:原理理解がもたらすプロンプト設計の進化
言語モデルの内部原理を理解することは、プロンプト設計の質を根本から高める基盤となります。本記事で見てきた特性は単なる知識ではなく、AIとのコミュニケーションを根本的に改善するための実践的な指針となります。これらの理解に基づくと、表面的なテクニック集を暗記するよりも効果的だと分かります。
言語モデルは単なるテキスト生成機械ではなく、複雑な内部メカニズムを持つ知的システムです。その特性を理解し、AIとの建設的な協働関係を築いて「なぜそれが効くのか」という理解に基づいたプロンプト設計こそが状況に応じた柔軟な対応を可能にし、AIの真の潜在力を引き出す鍵となると思われます。
今後プロンプトを書く際には「この指示がなぜ効果的なのか」を考えてみるのも良いと思います。それが、生成AIを単なるツールからパワフルな協働パートナーへと進化させる第一歩になるはずです。
この記事をシェアしてください
バックナンバー
この記事の筆者
筆者の人気記事
【注目】生成AIサービス「Perplexity」の独自機能と信頼性を徹底解説
2024年7月4日 6:30
【2026年の新常識】「良い質問」より「良い前提」。生成AIを動かすコンテキスト設計
1月8日 6:30
【一気にわかる!!】動画生成AIが構築する世界の「現在」と「未来予想」
2024年8月29日 6:30
【AIの思考プロセス理解】言語モデルの内部から学ぶ効果的な指示の技術
2025年4月17日 6:30
【日本上陸の衝撃】OpenAI上陸で変わる日本のAIビジネスの在り方
2024年5月9日 6:30
【OpenAI o1が切り拓く新時代】AI推論の実力と社会への影響は?
2024年10月10日 6:30
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
