ユーザー定義関数(On Stream機能)とは?
ユーザー定義関数(On Stream機能)とは?
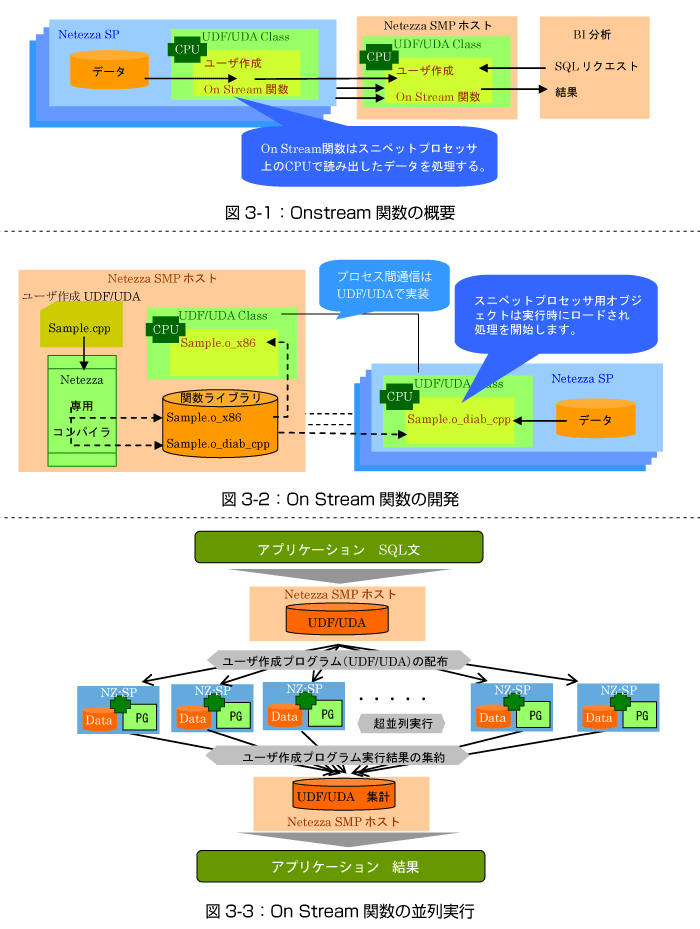
ここからはNetezzaの標準機能を拡張するユーザー定義関数(On Stream機能)について概要を紹介します。
ユーザー定義関数(On Stream機能)とは、データを保存しているストレージデバイス(ディスク)から読み出したデータを、その場(Netezzaのスニペット・プロセッサ)でユーザーが作成したプログラムによる処理を行い、結果をBIシステムやクライアントへ返す仕組みなのです。
このユーザー定義関数は、各スニペット・プロセッサで実行されるためNetezzaの持つデータ分散と並列実行機能をフルに利用した高速処理が実現できます(図3-1:Onstream関数の概要を参照)。
ユーザー定義関数の例
On Stream機能には、データ処理の形式に応じて2つのFunctionタイプが提供されています。それぞれUDF(User Defined Function)・UDA(User Defined Aggregates)と呼ばれています。定義された関数は、通常のSQL関数と同じように使用できます。
【UDF(User Defined Function)】
読み出した1データレコードに対して1回実行される、フィルター処理を記述します。
例 select Address, DISTANCE(P1.x, P1.y, P2.x, P2.y) form Map_info;
座標情報より2点間の距離を計算して返す、ユーザー定義関数DISTANCEを作成できます。
【UDA (User Defined Aggregates)】
読み出したデータレコードを蓄積・集計する場合の処理を記述します。
例 select ID, ADDPOINT(POINT)from Tran_table group by ID;
前回の獲得ポイントに応じて、今回の獲得ポイント倍率が加算される関数ADDPOINTを作成できます。
従来はアプリケーション側で計算する処理であっても、データ・ウエアハウス側(Netezzaのスニペット・プロセッサ)に計算させることで、並列処理を行い実行速度は飛躍的に(スニペット・プロセッサ数に比例して)速くなります。
ユーザー定義関数の活用で大きなレスポンスを得る
ユーザー定義関数の作成
ユーザー定義関数の作成はオブジェクトプログラム言語であるC++を使って作成します。Netezzaが提供するUDF/UDAクラスを基本クラスとして、継承したユーザー定義クラスを作成し、クラス内にユーザーのロジックをプログラミングすることによりユーザー定義関数のプログラムを作成します。
作成したプログラムをNetezza専用のコンパイラでコンパイルすることにより、SMPホスト用とスニペット・プロセッサ用の2つのオブジェクトが作成されます。このスニペット・プロセッサ用オブジェクトはSMPホストに登録され、実行時に個々のスニペット・プロセッサ上へ配布され実行されます。
この時スニペット・プロセッサとSMPホスト間のデータ通信はUDF/UDAの基本クラスに実装されているため、プロセス間通信を意識せず簡単に分散処理プログラミングができます(図3-2:On Stream関数の開発を参照)。
ユーザー定義関数の並列実行
Netezzaのユーザー定義関数では、ユーザーが作成した1つのプログラムコードが複数のスニペット・プロセッサで同時に並列処理され(92個のスニペット・プロセッサを搭載したNetezzaTwinfin12では92並列処理)結果を受け取ることができるのです。
つまり、あなたの作ったプログラムが超並列コンピューティングされるということを意味します(図3-3:On Stream関数の並列実行を参照)。
ユーザー定義関数の有効性
データベースでは一般的にビジネスロジックをストアード・プロシジャとして実装する方法があります。しかし、ストアード・プロシジャによるビジネスロジックの実装は、SQLプログラミングの効率化や、データベースの運用性向上としては効果がありますが、処理の高速性には適していません。
Netezzaのユーザー定義関数により、データ・ウエアハウスの並列処理にユーザーのビジネスロジックを組み込むことが可能になります。また、ユーザー定義関数はスニペット・プロセッサで処理されるため、データフローによるオーバーヘッドも小さく結果としてユーザーはけた外れのレスポンスを得ることができるのです。
今回はデータをためる部分“データ・ウエアハウス”の最新技術を紹介しました。次回は、たまったデータを活用する“分析ツール”の製品選定について紹介します。
- この記事のキーワード
関連記事
バックナンバー
この記事の筆者
筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
