超並列DWHとユーザー定義関数
大量データでも手間要らずのNetezza DWHアプライアンス近年のデータ増加で、データ・ウエアハウスのサイズが想定以上になってしまったという企業は少なくありません。データが増えるということは、その企業の活動が活発であるということですから喜ばしいことです。しかし、データ・ウエアハウスは悲鳴を上げてい
2010年3月10日 20:00
大量データでも手間要らずのNetezza DWHアプライアンス
近年のデータ増加で、データ・ウエアハウスのサイズが想定以上になってしまったという企業は少なくありません。データが増えるということは、その企業の活動が活発であるということですから喜ばしいことです。しかし、データ・ウエアハウスは悲鳴を上げています。
その悲鳴とは、主に以下の3つです。
- 検索パフォーマンスが悪くなった
- データ取り込みの夜間処理が、朝までに終わらない
- 結果としてパフォーマンスチューニングや運用管理の手間がかかる
データ量の多さが原因ですが、大規模ならではのチューニングや管理の複雑さが原因でもあります。ノウハウがない、もしくは面倒だから手をかけない、だから、パフォーマンスが悪化していく…という悪循環です。
近年、このような問題への解決策としてさまざまなデータ・ウエアハウス専用にハードウエアを一体化した製品が増えてきています。ここでは「DWHアプライアンス」という言葉を最初に使いはじめたベンダーNetezza(ネティーザ)社の製品をご紹介しましょう。
もっとカンタンに運用できて、チューニングしなくても速いデータベースが作れないか、という発想のもとで開発されたのがNetezzaの「DWHアプライアンス」です(以下Netezza)。アプライアンスとは特定の機能に特化したコンピュータのことで、汎用性には欠けますがそのぶん設置や設定などの操作が簡単で性能を追求したものとなっています。データ・ウエアハウス用途に特化しているから、検索処理が速い、データローディングが速い、そして、アプライアンスだからカンタン、というのが特徴です。
それでは、Netezzaの速さの秘密を2つご紹介します。
速さの秘訣(ひけつ)その1:ハードウエアでSQL処理を行う
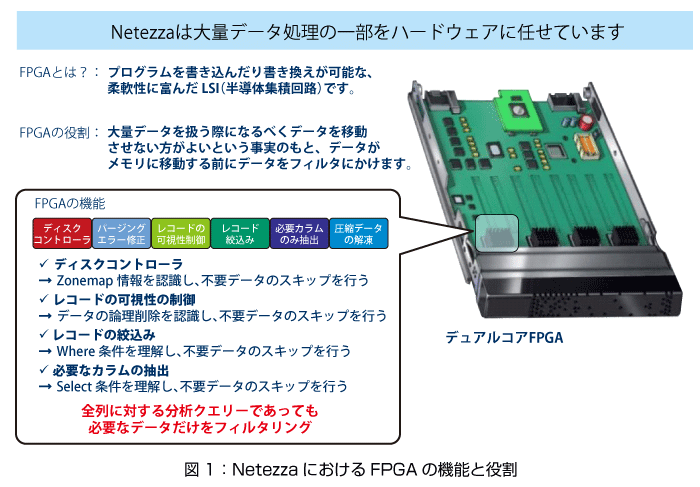
Netezzaには、SQL処理を行うハードウエア部品が搭載されています。
“SQL処理をするハードウエア”だなんてまったく想像がつかないかもしれませんが、『FPGA』というものを知っていただくと実態が理解できると思います。FPGA(Field Programmable Gate Array)は任意の論理回路の書き込み/書き換えができるLSIであり、近年ではDVDプレーヤーや画像処理ボードなど、少し複雑な処理が必要でかつ高速に動作する必要がある機器に多く採用されています。
一般的なデータベースの検索処理は、ディスクから共有メモリにデータを読み込み、メモリ上でクエリを実行します。メモリに読み込まれるデータはクエリ(SELECTやWHERE)でカラムとレコードを絞り込む前のデータブロックですので、サイズが大きいままです。データ・ウエアハウスではシステム内部で大量の「データの移動」が発生し、処理時間が遅い原因の1つとなります。
Netezzaは、このデータ自体を極力移動させないことでCPUが処理すべきデータ量を最小限に抑えています。ディスクI/Oコントローラのところで、レコードの可視化制御やSELECT句のカラム、WHERE句など条件の絞り込みを行ってしまい、メモリ上にデータブロックすべてを読み込まなくても良い仕組みとなっています。ここに使用されているのが『FPGA』です。
Netezza社はディスクからデータを読み込みながら不要なデータをフィルタリングする機能をFPGAに実装しました。さらに、圧縮してディスクに格納されているデータの解凍もこのFPGAで行われます。普通の解凍はOSの上のソフトウエアがサーバのCPUを使って処理しますが、Netezzaのデータの解凍はFPGAで行うため非常に高速なのです。
通常のシステムではCPUが処理するSQL処理の大半をFPGAが行う、まさに「ハードウエアでSQL処理」だから高速なのです。
- この記事のキーワード
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者
筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
