はじめに
今回は、コンテナを中心にした技術をより有効活用するためのアーキテクチャ(構造)について説明していきます。そのため、今までよりも少し難しい内容になるかもしれません。取り上げるテーマは「マイクロサービス」と「サーバーレス」です。本来であれば、この2つのアーキテクチャを説明するためには、サービスの分割や開発者によって作られるアプリケーションの開発手法から説明しなければならないのですが、今回はアーキテクチャにフォーカスを当てていきたいと思います。
マイクロサービスアーキテクチャとは
まずは、マイクロサービスアーキテクチャについて説明していきましょう。マイクロサービスアーキテクチャを説明するためには、「モノリシック」なサービスと対比するとわかりやすいでしょう。図1に2つの構造を並べてみました。
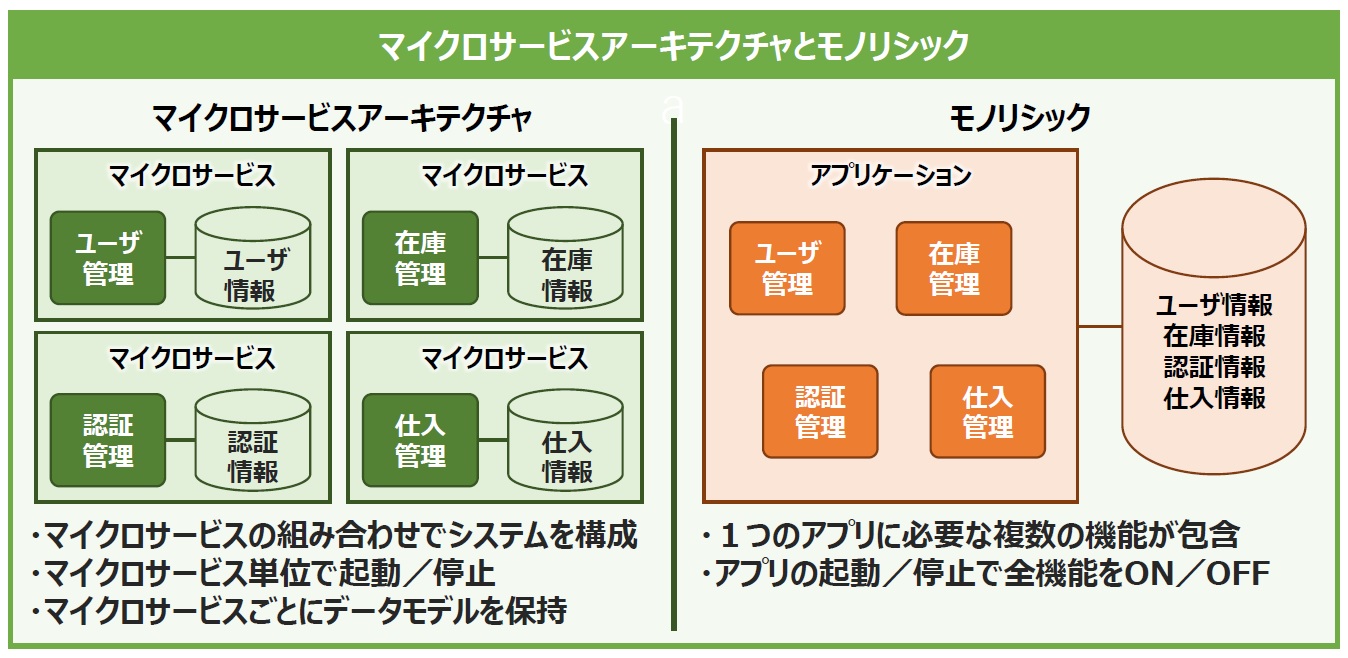
図1:マイクロサービスとモノリシック
つまり「マイクロ」という言葉の通り、アプリケーションをある程度の細かな機能単位で分割し、独立して起動・停止できるようにしたものが「マイクロサービス」であり、それらをつなぎ合わせて連動して動くようにしたのが「マイクロサービスアーキテクチャ」と言えそうですね。
マイクロサービスアーキテクチャのメリット
では、マイクロサービスアーキテクチャのメリットは何でしょうか。大きなメリットには2つあります。
- 独立して開発してデプロイできるため、単一機能の変更が他のサービスに影響しない(いわゆる疎結合)
- 独立してスケールできるため、単一機能のサービスのみ処理性能を高めることができる
この2つのメリットを活かした機能ごとのスピーディな開発と変更により、ビジネスの状況変化に素早く対応でき、必要な時に必要な分だけ開発の人的リソースやアプリケーションを動かすための環境、つまり物的リソースに適材適所で投資できます。ただし、このようなメリットを得るには課題も多いのです。

マイクロサービスの課題
さて、先に触れたようにビジネスにおけるメリットが大きいマイクロサービスアーキテクチャですが、全てを解決してくれるわけではありません。サービスの規模が大きくなり、個々のサービス(機能)間の通信が複雑化していくにつれ、マイクロサービスならではの課題が表れてきます。
例えば6つのPodで成り立っているサービスがあると仮定した場合、それぞれのPod同士の接続パターンは「6x5x4x3x2x1」で720にも及びます。たった6つのPodだけでもそれだけのパターンが考えられるため、サービスの規模が大きくなれば各サービス間でどのように通信しているのかを管理し、全体を把握するのが困難になっていくことは容易に想像できます。
また、サービス間通信における通信の暗号化や認証・認可の機能が必要になったとしましょう。KubernetesではPod間やNode間の通信はデフォルトでは暗号化されていないため、その場合には複雑化したサービス間の依存関係などの影響範囲を事前に調べ、テストして実装するといった手間が発生します。これらもサービスの規模が大きくなればなるほど困難になっていきます。
マイクロサービスアーキテクチャには、各サービスを独立した異なる言語で開発できるメリットがある一方で、それ故に個々の要件に応じてサービス間通信をセキュアにすることはとても難しくなるということです。
同時に、サービス間の通信が複雑化して依存関係の把握が困難になると、通信関連の障害が発生した際に、どこで発生した障害かを適切に判断(切り分け)することが格段に難しくなることにもつながります(図2)。
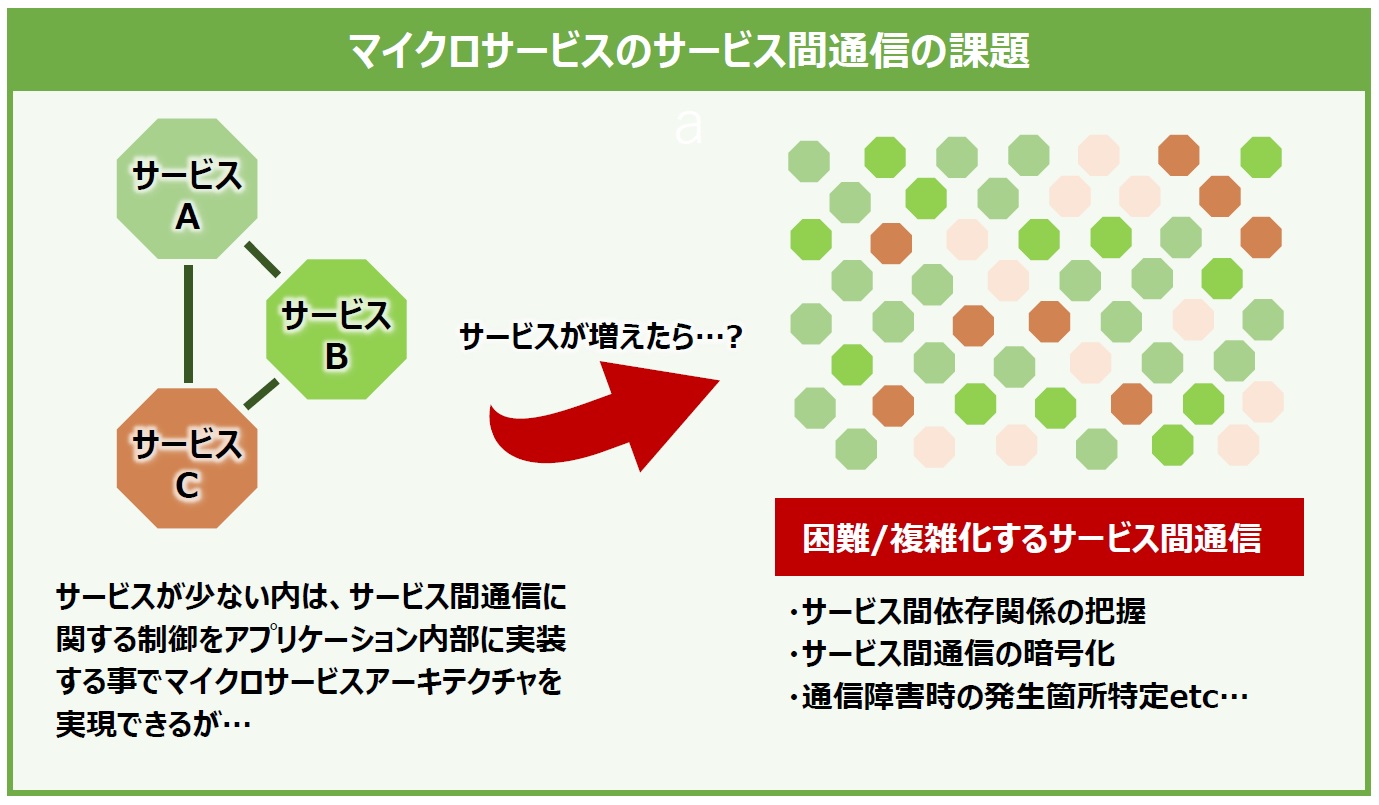
図2:マイクロサービスのサービス間通信の課題
サービスメッシュとは
マイクロサービスアーキテクチャにおけるサービス間通信の課題を、個々のサービス内のコードを書き換えて解決しようとすると膨大な開発工数が必要となり、現実的ではありません。
そこで登場するのが「サービスメッシュ」というアイデアです(図3)。サービスメッシュとは、個々のサービス内通信に制御周りの機能を実装するのではなく、通信制御に関する専用のレイヤを追加することでサービス間接続の管理を実現させようという考え方です(※サービスメッシュという名前は、マイクロサービス間(Service)を繋げる通信が網目(Mesh)のように見えることから来ています)。
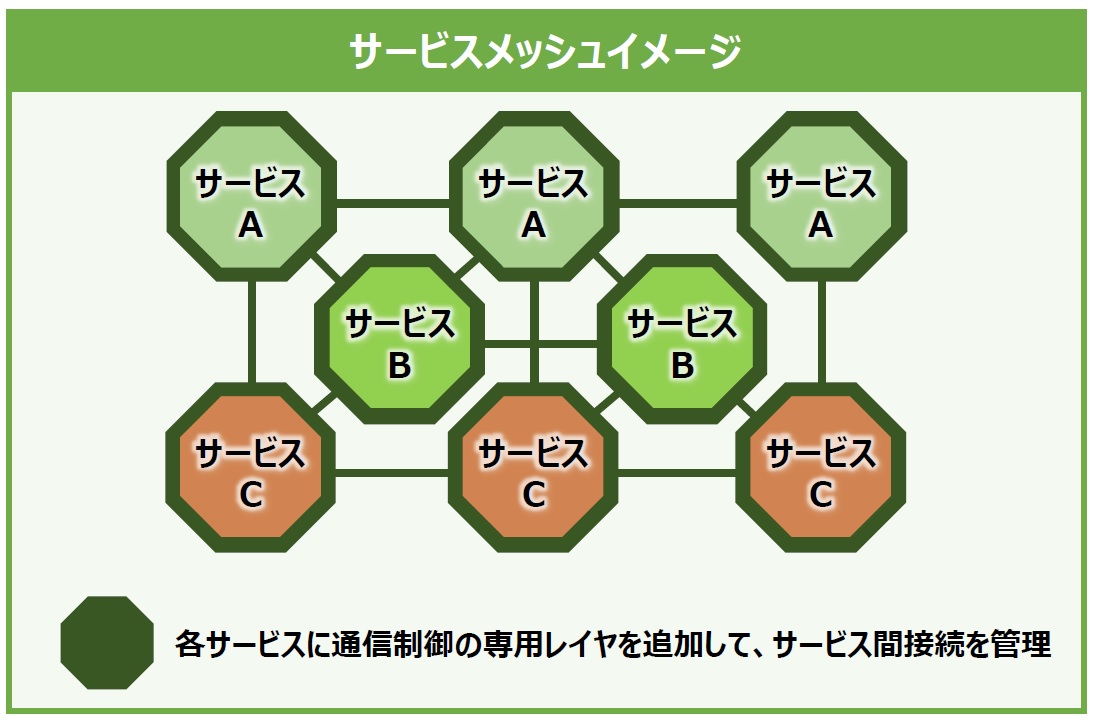
図3:サービスメッシュイメージ
サービスメッシュを実現するためのソフトウェアとして「Istio」「Linkerd」「Consul」などが挙げられます。ここでは、これら3種の中でも最も知名度の高いIstioを紹介します。
Istio
Istioは、ライドシェアサービスを展開するLyft社が社内システムの構築用に開発した「Envoy」をベースに、GoogleやIBM、Lyftの3社が協力して開発したサービスメッシュのオープンソースプロジェクトです(※Istioはギリシャ語で「Sail」(帆)を意味します)。Istioの大きな特徴は、KubernetesのPodごとにEnvoy(Proxy)をサイドカーとしてデプロイすることでPod間通信を全てEnvoy経由で制御し、管理できるところにあります(図4)。
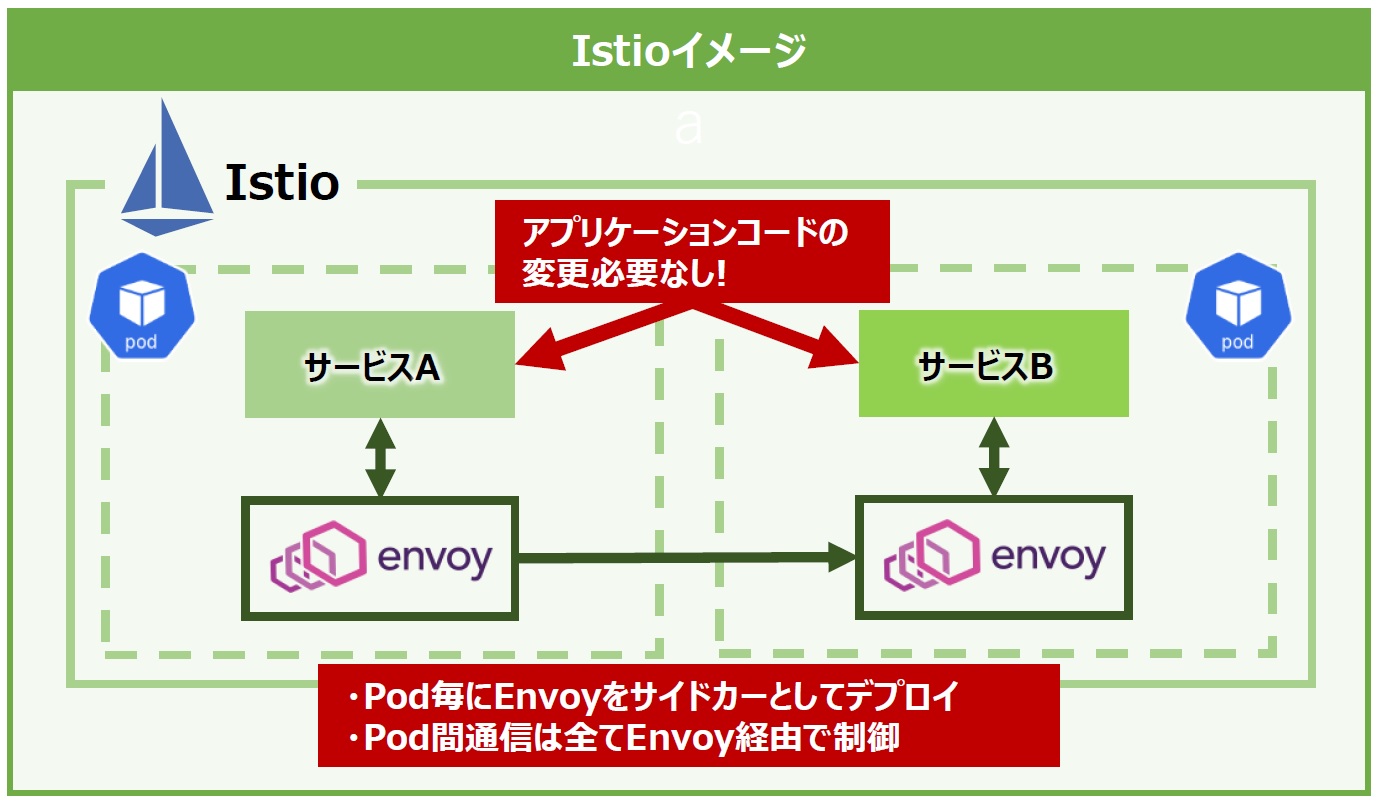
図4:Istioイメージ
Istioを理解するために、まずサイドカーとEnvoyについて説明します。サイドカーはKubernetesのPod内で主たるコンテナを補助する役割を持つ別のコンテナを同居させる構成パターンを指します。
EnvoyはLyft社が社内で開発したクラウドネイティブアプリケーション向けに設計されたプロキシです。マイクロサービスにおけるネットワーク制御を個々のサービスで対応するのではなく、ネットワークプロキシで実現させる目的で開発されました。
各サービスが他のサービスを直接参照することなくEnvoyプロキシを経由して通信するため、コンテナの入れ替わりで動的に変わるIPアドレスなどの接続先情報をサービス自身が意識しなくても良くなり、通信先が変わってもアプリケーション側のコードを変更せず、Envoy側で接続先情報を更新するだけで済むというわけです。
これにより、開発者はサービス間接続に関する課題から開放されます。この他にも、Envoyにはロードバランシングやトラフィックのモニタリングなどの様々な機能が備えられています。
さて、このEnvoyでも、やはり利用するサービスが増えれば増えるほど管理の手間も時間もかかってしまいます。そこで登場するのがIstioです。
Istioにおけるサービスメッシュはコントロールプレーンとデータプレーンの2つに分けられます。データプレーンでは、各サービスにサイドカーとしてEnvoyをデプロイして、マイクロサービス間での全ての通信を仲介、制御します。また、全てのトラフィックに関する各種統計情報を収集して報告します。
コントロールプレーンでは「Istiod」というコンポーネントによってプロキシやトラフィックルーティングなどの設定や管理を行います。元々は「Pilot」「Citadel」「Galley」というコンポーネントがコントロールプレーンにありましたが、バージョン1.5に更新されたタイミングでそれらはIstiodに統合された経緯があります(図5)。

図5:Istioアーキテクチャイメージ
Istioは図5の各コンポーネントを用いてトラフィックマネジメント、セキュリティ、可観測性の3つの主要機能を実現します。
トラフィックマネジメント機能(図6)では、トラフィックの宛先に関するルーティングや負荷分散方式などのトラフィック処理方法の制御、サービスメッシュ内外へのインバウンドおよびアウトバウンドトラフィック管理などの機能があります。また、タイムアウトやリトライ、サーキットブレーカー(同時接続数や呼び出し失敗回数を定義して制限に達すると、それ以上の接続を停止させる機能)などの障害復旧ポリシーを定義することで、アプリケーション全体の障害回復能力をテストできます。
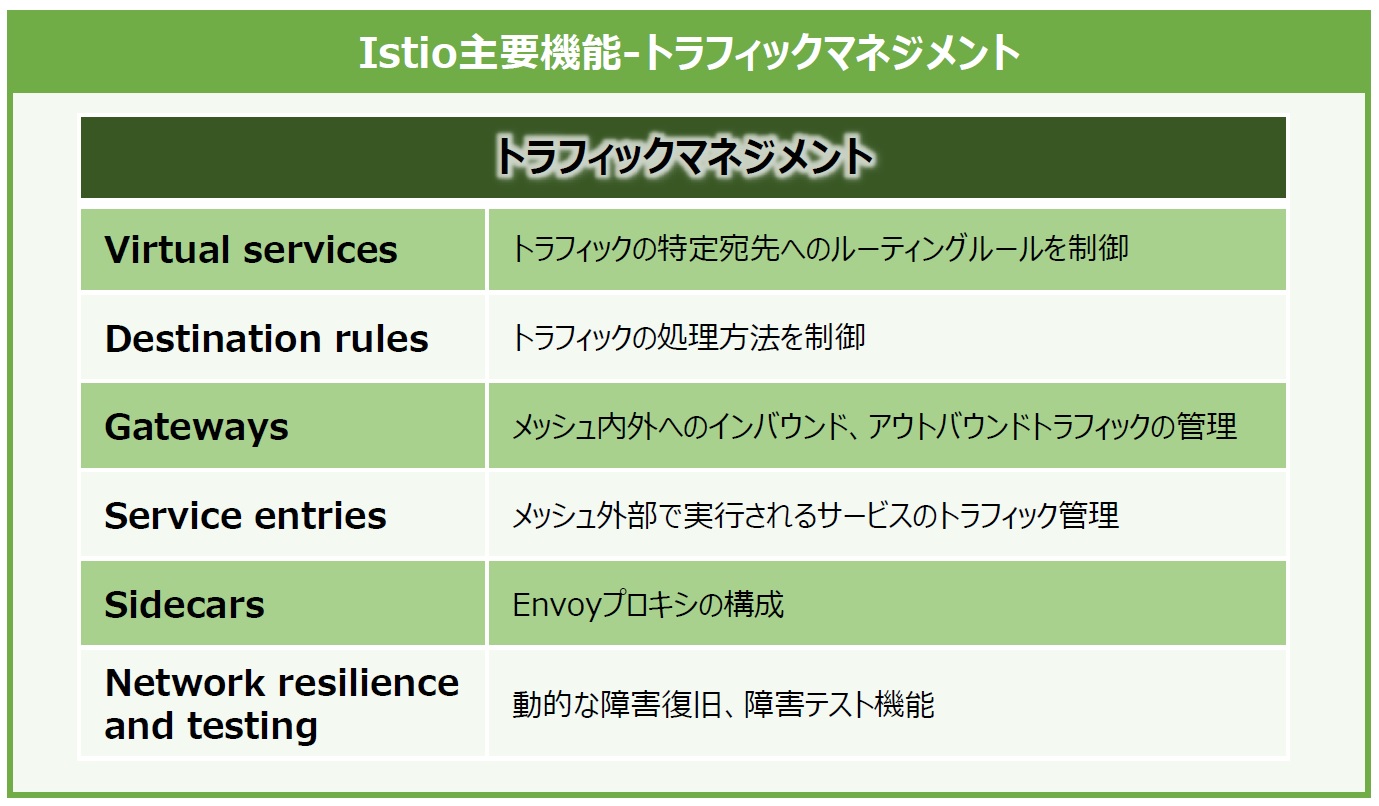
図6:Istio主要機能-トラフィックマネジメント
セキュリティ機能(図7)では、IDやポリシー、TLS暗号化、認証・認可、監査ツールを提供することでサービスとデータを保護してくれます。

図7:Istio主要機能-セキュリティ
可観測性機能(図8)では、サービスメッシュ内通信の全てのテレメトリを生成します。テレメトリには3種類あり、プロキシレベル、あるいはサービスレベルにおけるトラフィックの全体量やエラー率、要求の応答時間などの情報を提供する「メトリクス」や、サービスメッシュ内を通過するリクエストを監視してサービスの依存関係やレイテンシの原因を把握するために利用できる「分散トレース」、サービスメッシュ内トラフィックのアクセスログを生成する「アクセスログ」があります。

図8:Istio主要機能-可観測性
ここでは、Istioなどのサービスメッシュコントロールプレーンを使用すると、Kubernetesなどによるマイクロサービスアーキテクチャが抱えるサービス間通信の課題を解決できることを覚えておきましょう。

サーバーレスアーキテクチャと
FaaS(Function as a Service)
ここからは、サーバーレスアーキテクチャについて説明していきましょう。「サーバーレス」という言葉には「広義のサーバーレス」と「狭義のサーバーレス」の2種類があります。
広義のサーバーレスは、サーバーレスという言葉から「サーバが全くない」ような印象を受けますが、実際には存在します。利用者側はリソースを意識せず、クラウドベンダーが提供するマネージドサービス利用するためサーバーレスと呼んでいるのであり、クラウドベンダー側がそのサービスを動かすためのサーバを管理してくれているのです。
一方、狭義のサーバーレスが今回取り上げるサーバーレスアーキテクチャで「サーバーレスコンピューティング」というものですが、最も代表的なサービスは「FaaS(Function as a Service)」です。
Functionは日本語で表すと関数という意味で、ITの世界では入力した値に対して何かしらの処理を実行し、その結果を返してくれるプログラムの部品と捉えることができます。その入力イベントを起点としてプログラムの処理がクラウド上で実行されるサービスがFaaSなのです。AWSの「Lambda」、Googleの「Cloud Functions」、Microsoftの「Azure Functions」などが有名ですね(図9)。

図9:それぞれのクラウドベンダーのFaaS

クラウドベンダーに依らない
サーバーレスアーキテクチャ
とある機能を実行するためのリソース(サーバやストレージなど)をユーザが意識しなくても良いFaaSはクラウドとの相性が抜群といえます。しかしながら、その相性の良さは、それを提供するクラウドベンダーのサービス仕様(サービスのスペック、アプリケーションのデプロイ方法、管理方法、実行環境のバージョンなど)に依存してしまう課題を内包していました。
そこでクラウドベンダーに捉われずに、コンテナの特徴の1つである「どの環境でも動かすことができる」メリットを活かしてサーバーレスアーキテクチャを実現してくれるのが「Knative」です。
Knativeはシステム基盤がオンプレミスでもクラウドでも、あるいはサーバーレスアーキテクチャを提供できないサードパーティのデータセンタでも、Kubernetesが作れる環境であれば同じ条件で動かすことができるのです。
Knative
Knativeを使用することで、以下のようなことを実現できます。
- Deployment、Serviceなど複数のKubernetesリソースの設定が1つで完結
- 長時間使用していないサービスを0個にスケールイン
- 同一リクエストを複数のコンテナに対してトラフィック分割が可能
- クラスタ内でコンテナをビルド
- Pub/SubトピックへのPublishイベントを検知してコンテナでメッセージを処理
Knativeを使えば、アプリケーション開発者にとって単調で難しいビルドやデプロイ、管理など、の作業から解放され、コーディングに集中することができます。
次に、Knativeの主なコンポーネントを紹介します。以前は、図10のように3つのコンポーネントが存在していました。
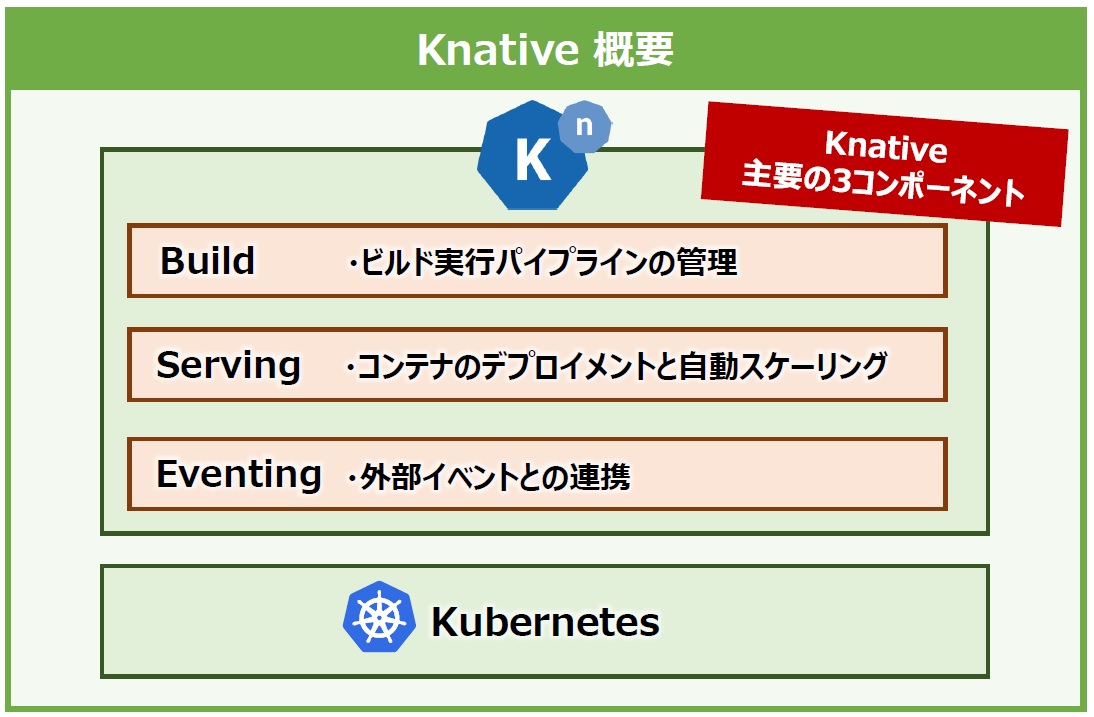
図10:Knative概要
「Knative Build」は「Tekton」という名前のCI/CDパイプラインツールとして独立して存在するようになり、現在のKnativeでは「Knative Build」「Knative Serving」と「Knative Eventing」のみで構成されます(※Tektonを含めた3つのCI/CDパイプラインツールを組み合わせてサーバーレス環境を作り上げるため、最後にTektonも併せて取り上げます)。また、これらのコンポーネントはKubernetesの拡張リソースであるCRD(Custom Resource Definition)で組み立てられているため、他のKubernetesのリソースのマニフェストと同じようにYAML形式で記述できます。
それでは、各コンポーネントについて説明していきましょう。
・Knative Serving
Knative Servingを支えているのはIstioです。Istioの通信制御や認証・認可の機能によりサービス間接続を制御し、コンテナのアプリケーションと関数のデプロイをサポートします。またKnative Servingは簡単に開始でき、高度なシナリオをサポートするように拡張もできます。
Knative Servingで実現できることをまとめると、図11のようになります。
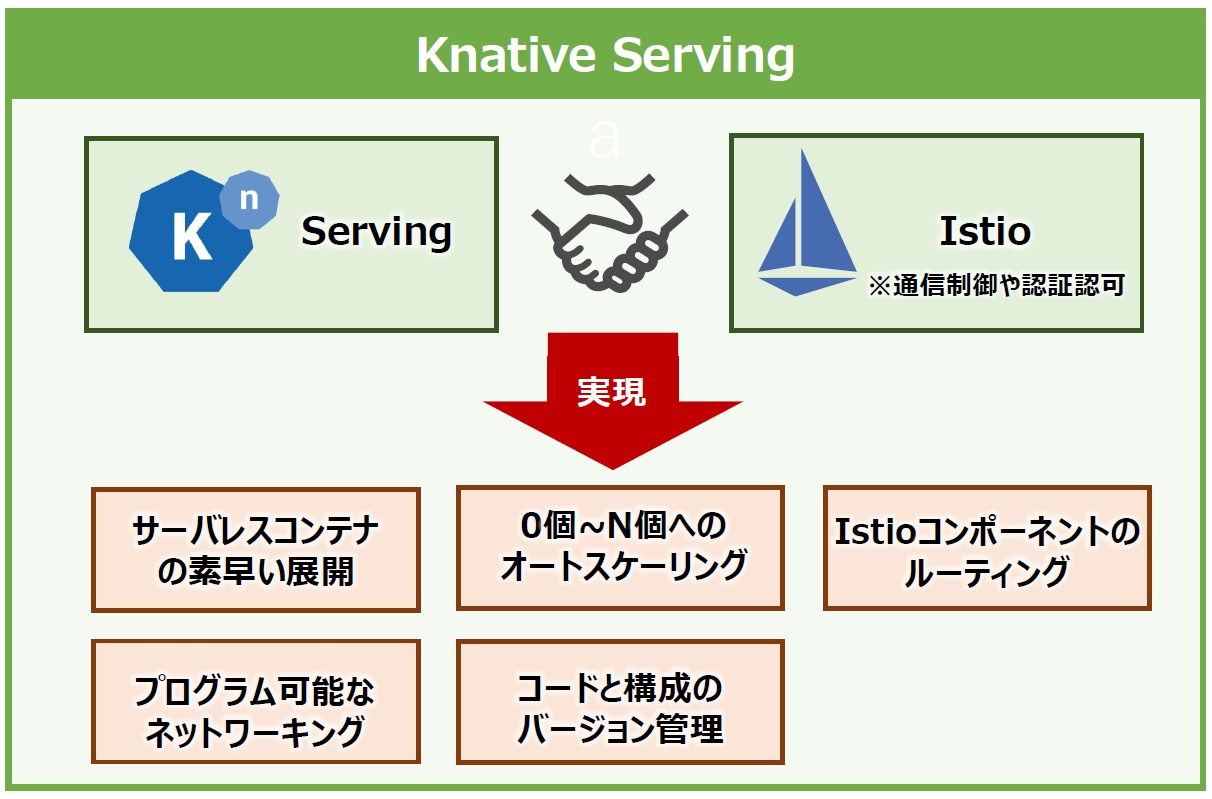
図11:Knative Serving
その中で「0個~N個へのオートスケーリング」が特徴的で、アプリケーションに全くリクエストが来ない状態が続くと、アプリケーションのPod自体が1個も立ち上がらない状態になります。0個の状態で再びアプリケーションへのリクエストが発生すると改めてPodが立ち上がるのです。
・Knative Eventing
Knative Eventingはその名の通りイベント処理を実現します。KnativeをFaaSのようにイベント受信を契機に処理を実行させるために必要なコンポーネントです。Knative Eventingはイベントソースとイベントコンシューマいう概念に分かれており、汎用的なイベント連携インターフェースを備えています。各イベントのデータはイベントソースからBrokerへ送信され、別途設定するTriggerにより適切なConsumerへ振り分けて転送される流れになっています(図12)。

図12:Knative Eventingにおけるイベント送信の流れ
また、Knative Eventingは「CloudEvents」というCNCFで定義されたクラウドで発生するイベントを示し、通知するための標準仕様に準拠しており、様々なサービス同士の疎結合性を高める目的で作られています。
・Tekton
Tektonは、第7回で登場したCI/CDパイプラインをKubernetes上で実行するツールです。現在は「Tekton Pipelines」としてCDF(Continuous Delivery Foundation)というCI/CDを標準化する組織で開発が行われています。
Tektonは、以下の単位でパイプラインを組むことができ、再利用性が高いという特徴があります。
- Step : Pod内で実行するコマンドを定義
- Task : 複数のStepをまとめて単一のPod内に処理フローを定義
- Pipeline : 複数のTaskをまとめて処理フローを定義
この3つの関係性は、図13のように表すことができます。
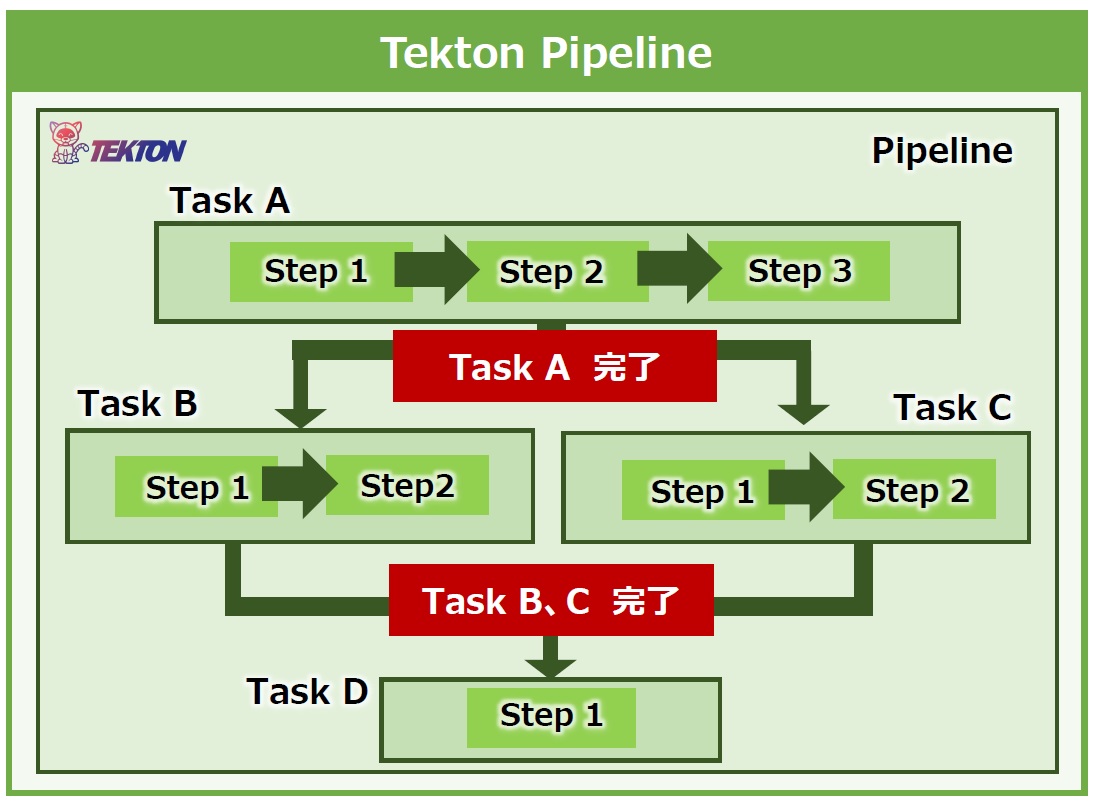
図13:Tekton Pipeline
ほかにも、このパイプラインのインプットを定義する「PipelineResource」や、Taskのみの実行を定義する「TaskRun」、Pipelineの実行を定義する「PipelineRun」を組み合わせることでコンテナのビルドやテストを実行し、イメージをレジストリにPushしてリリースします。

おわりに
今回は、コンテナを使い方の一例として、やや難しめの「マイクロサービス」と「サーバーレス」について紹介しました。ここまでの全10回で本連載はいったん終了にしたいと思います。ざっくりとでも、コンテナがどのようなもので、どこでどうやって使われるかを理解できたのではないでしょうか。
これからさらに理解を深めるには、触って動かしてみることが一番良いでしょう。手始めにDockerを触り、Kubernetesでコンテナの管理を実感し、アプリケーション開発にもコンテナを取り込んでいただければと思います。
本連載では紹介できませんでしたが、皆さんの身の回りにある様々なシステムにも少しずつコンテナが使われつつあります。ぜひ、コンテナを身近な存在として積極的に扱ってみてください。

この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
