Oracle Cloud Hangout Cafe Season6 #1「Service Mesh がっつり入門!」(2022年9月7日開催)
連載第6回の今回は、2022年9月7日に開催された「Oracle Cloud Hangout Cafe Season6 #1『Service Mesh がっつり入門!』」の発表内容に基づいて紹介していきます。
2023年6月22日 6:30
はじめに
「Oracle Cloud Hangout Cafe」(通称「おちゃかふぇ」/以降、OCHaCafe)は、日本オラクルが主催するコミュニティの1つです。定期的に、開発者・エンジニアに向けたクラウドネイティブな時代に身につけておくべきテクノロジーを深堀する勉強会を開催しています。
連載第6回の今回は、2022年9月7日に開催された「Oracle Cloud Hangout Cafe Season6 #1 『Service Mesh がっつり入門!』」の発表内容に基づいて紹介していきます。アジェンダ
今回は、以下アジェンダの流れに従って解説します。
- マイクロサービスにおける課題とService Mesh
- Service Meshを実現するプロダクト
- Istio Deep Dive
- まとめ
発表資料と動画については、下記のリンクを参照してください。
【資料リンク】
【動画リンク】
マイクロサービスにおける課題と
Service Mesh
Service Meshのトピックに入る前に、まず分散アプリケーション、特にマイクロサービスの運用で課題となる内容を踏まえた上で、Service Meshについて解説します。
マイクロサービスを運用するには様々な課題がありますが、今回は以下の4つの課題を解決策も含めて取り上げます。
- 高度なデプロイ戦略への追従
- カスケード障害
- Observabilityの複雑さ
- セキュリティの煩雑さ
高度なデプロイ戦略への追従
マイクロサービスを運用すると「せっかくマイクロサービスにしたなら、ユーザ体験や開発生産性を向上させたい」というモチベーションが高まってくることは珍しくありません。例えば「サービスダウンタイムなしでデプロイを実施したい」であるとか「本番環境でテストを実施したい」といったようなものです。
これらを実現するデプロイ手法として、以下のようなものがあります。
- A/B Test:旧バージョン(A)と新バージョン(B)を同時にデプロイし、どちらがより効果的かを見極める
- Canary Release:一部の限られたユーザを被検体として局所的に新機能(カナリア*1)を有効化してテスト
- Dark Launch(Shadow Test):本番トランザクションをデプロイした新バージョンにミラーリングし、新機能をテスト(ユーザには影響しない)
*1:カナリアとは、かつて炭鉱でのガス漏れ事故を防ぐために無臭ガスに敏感な鳥であるカナリアを鳥かごに入れて炭鉱に持ち込んだことに由来し、一部のユーザを「カナリア」に見立ててこの名称が付けられている
カスケード障害
マイクロサービスでは「カスケード障害」が発生することがあります。カスケード障害とは、局所的に発生した障害がその周辺コンポーネント、もしくはシステム全体まで伝播してしまう障害のことです*2。カスケード障害の原因のほとんどは、サーバやコンポーネントの過負荷によるリソースの枯渇であると言われています。
カスケード障害への防止策は、適切な時間を設定したタイムアウトやリトライ回数上限の設定があります。また、もう少し高度な防止策ではサーキットブレイカー*3の導入があります。これは、障害発生時のリトライなどによる大量トラフィックによるサービスダウン防止や障害時の通信を遮断/復旧を制御する仕組みです。
具体的には、外れ値検出による流量制限やコネクションプールによる流量制御などがあります。後者は後述するので、ここでは前者について少し補足します。
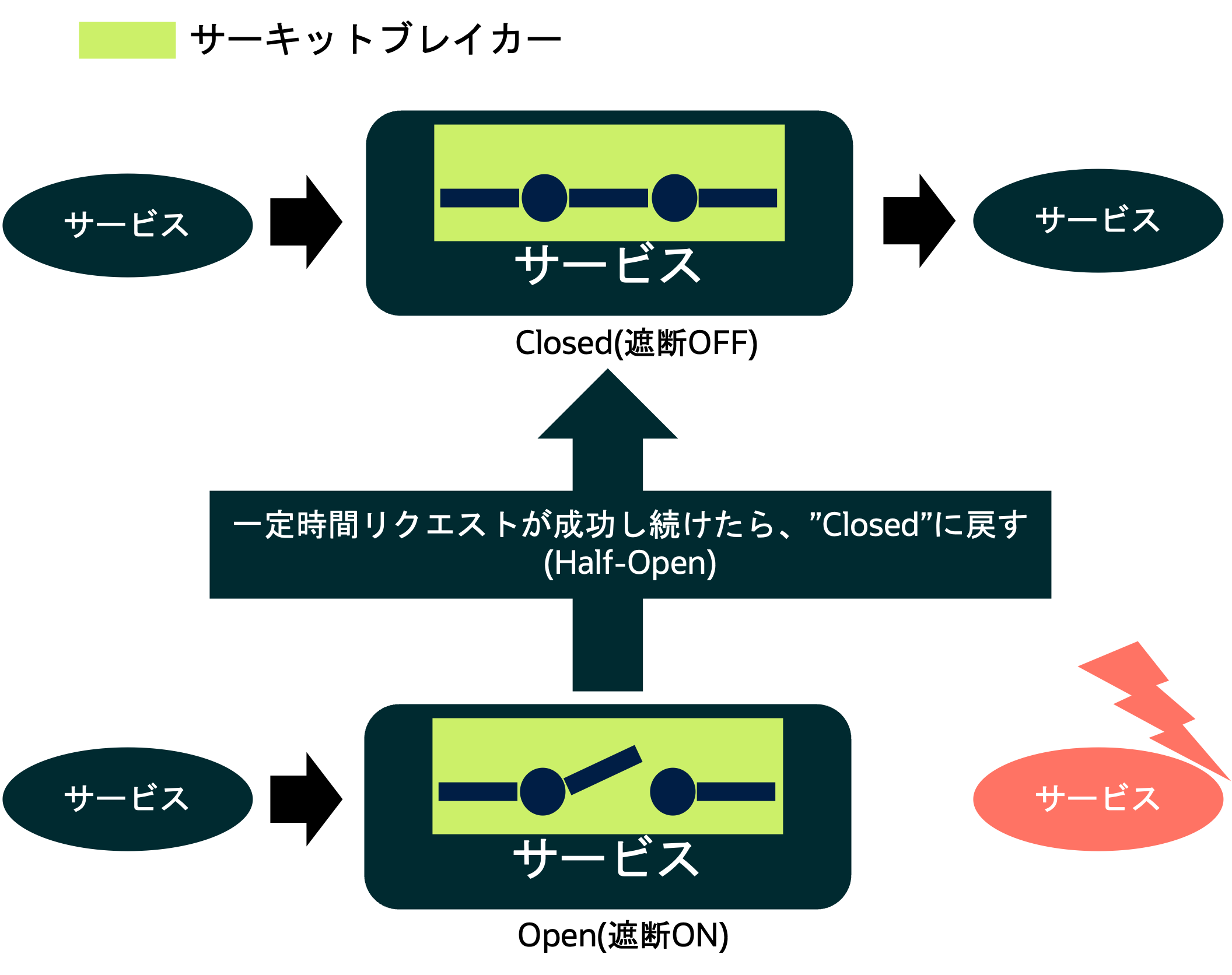
一般的に、サーキットブレイカーの外れ値検出には“Open(遮断)”、“Half-Open(確認中)”、“Close(遮断なし)”という3つのステータスがあります。障害発生後に任意の閾値(エラーレスポンスの回数など)を超過した場合はOpen(遮断)のステータスとなり、トラフィックを遮断します。
トラフィックの遮断を検知したクライアントはエラーを返したり、最新のキャッシュを返すなどのハンドリングを実施できます。その後、一定時間経過後にHalf-Open(確認中)となります。一定時間リクエストが成功し続けたらClose(遮断なし)となり、障害が復旧したと判断されます。
なお、Close(遮断なし)のステータス中にリクエストに失敗すると再度Open(遮断)のステータスとなります。この動きを繰り返すことで、余計なトラフィックの流れや負荷の発生を防ぎます。
*2:カスケード障害とは、本来は電力送電網内の一部で発生した障害が送電網全体に波及することで発生する大規模停電を指す
*3:サーキットブレイカーとは、本来は電力回路・電力機器などにおける短絡(ショート)や過負荷による過電流を防止するための遮断器を指す
Observabilityの複雑さ
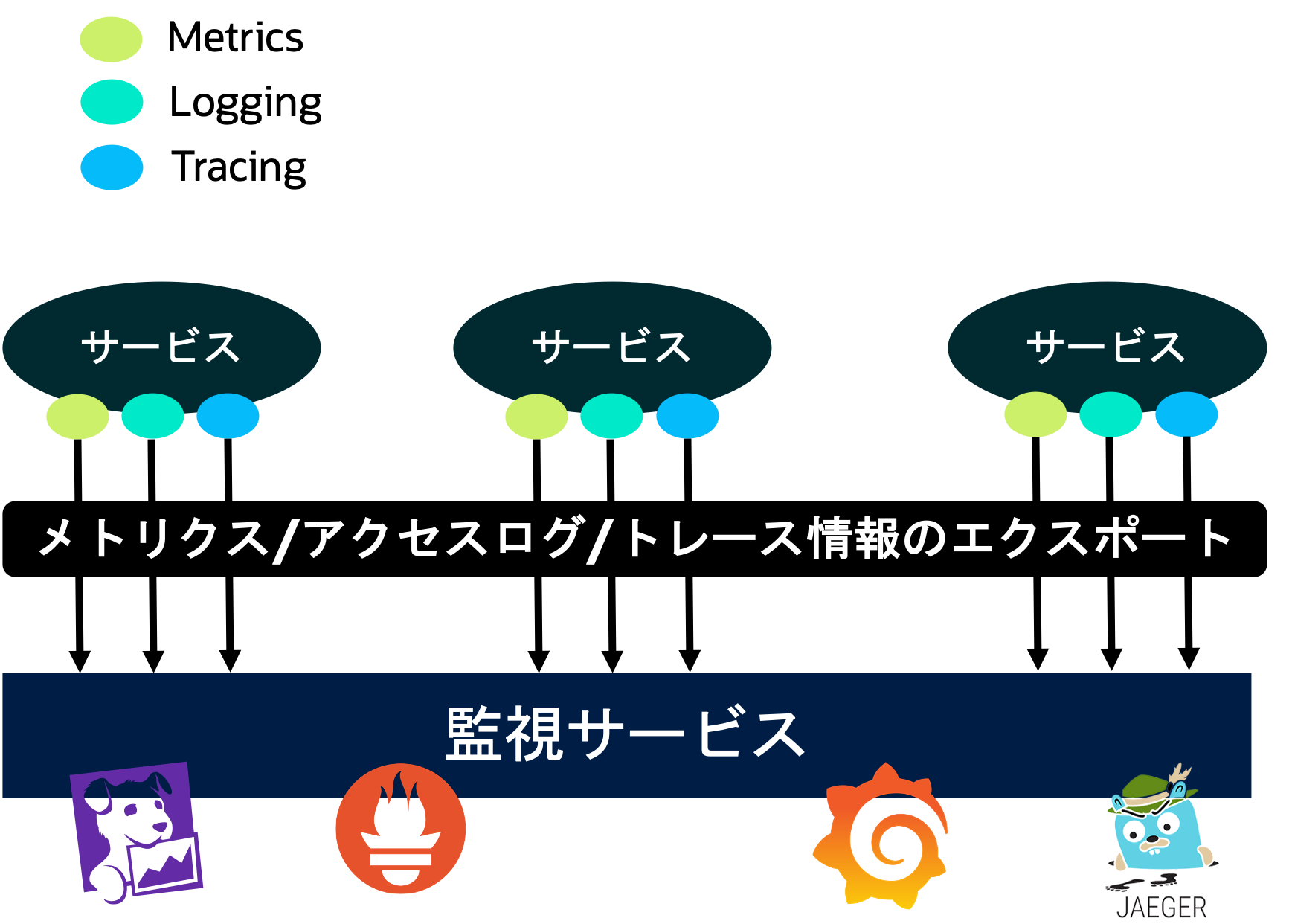
Observabilityは、マイクローサビスをはじめとする分散システムの可観測性です。「Metrics」「Tracing」「Logging」を中心とした要素があります*4。
MetricsとTracingは、原則として手動で実装する必要があります。Loggingは、従来通りアプリケーションからログを出力することでカバーできます。ただし、マイクロサービスでは大量の通信が発生するため、その状況を記録するにはアクセスログが必要です。
このようなObservabilityの要素を効率的に実装するには、共通的なインフラとして自動的にObservabilityの要素が適用される仕組みが必要です。この仕組みにより、ある程度のMetrics、Tracing、Loggingの情報を確認できます。
*4:最近では、Observabilityに4つ目の要素としてProfileやContextなども含まれたり、Observabilityは要素ではなく探索可能性やカーディナリティが重要という意見もある。しかし、本記事のメイントピックではないのと、Service Meshのメリットを簡潔に説明するため、本記事ではObservabilityの3要素を取り上げる
セキュリティの煩雑さ
マイクロサービスでは、各サービス間の通信をRESTやRPC(gRPC)といったプロトコルで実施します。モノリスなアプリケーションではサービス間はメソッド/関数呼び出しとなるためセキュリティ上の考慮は不要ですが、マイクロサービスの場合は通信暗号化や認証認可などの考慮が必要です。
これらを効率的に実施するには、Observabilityと同様に、共通的なインフラとして自動的にセキュリティポリシーが適用される仕組みが必要です。この仕組みにより、セキュアなトラフィック制御やデフォルトでの通信暗号化、認証認可を実現できます。
マイクロサービス運用における
課題解決の救世主「Service Mesh」
ここまでマイクロサービスにおける4つの課題とそれぞれの解決策を見てきましたが、これら全てを手動で実装するのは現実的ではありません。そこで、これらの課題を解決する手段の1つとして「Service Mesh」があります。
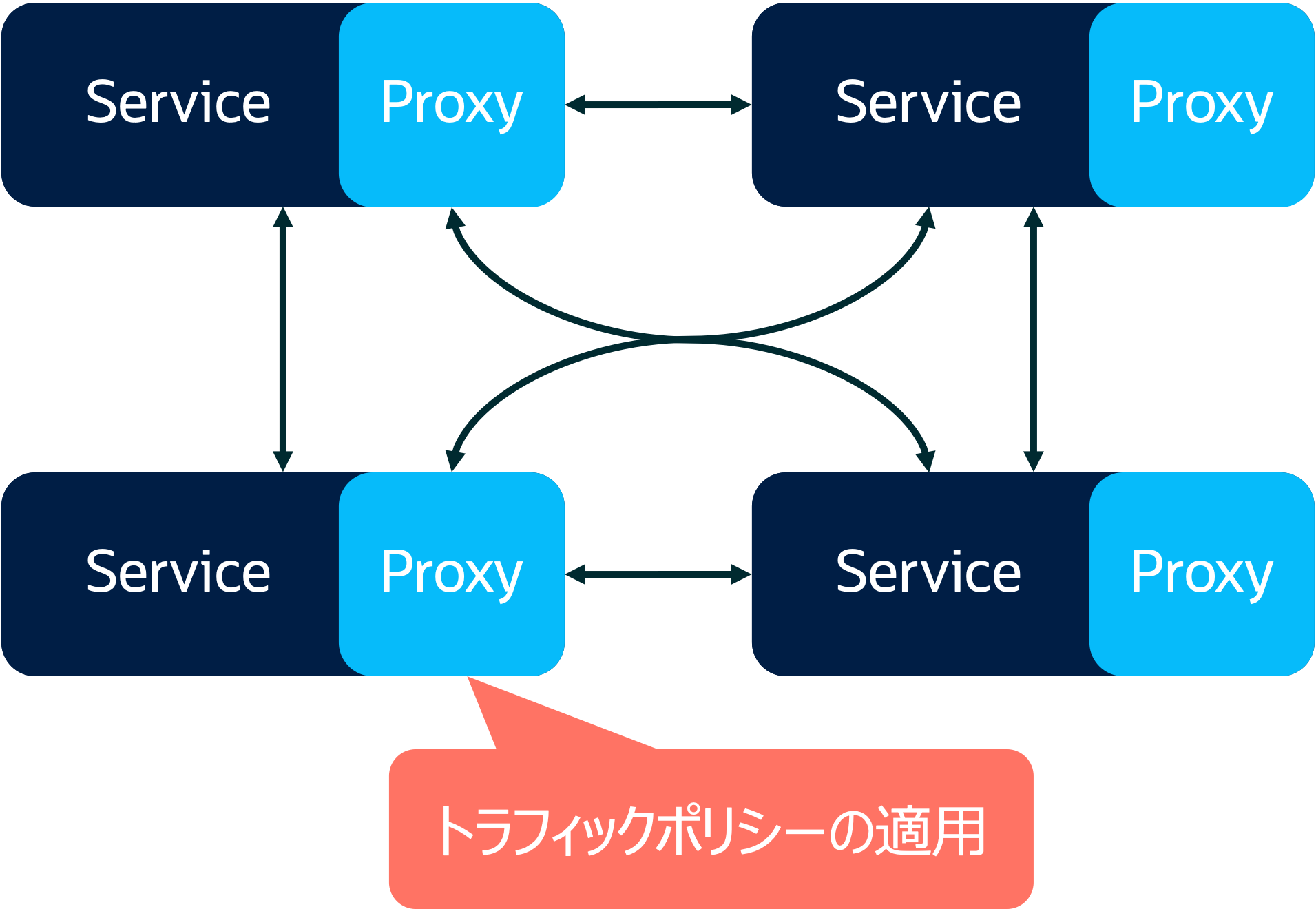
Service Meshは分散システム(マイクロサービス)におけるデザインパターンの1つであり、アプリケーション側に余分な実装を行うことなく、トラフィックの管理をシームレスに実施できる仕組みです。具体的には、各サービス間のトラフィック制御をプロキシにアウトソーシングすることで実現します。
Service Meshが容易にするものとして、以下のようなものが挙げられます。なお、これらの項目は、あくまでもService Meshを利用して効率的に実装できるものであり、必ずしもService Meshが必須というわけではないことに注意してください。
- 高度なデプロイ戦略の導入
- 流入制限などのトラフィック制御
- 包括的なモニタリング
- 高度なセキュリティの構築(mTLS/認証認可)*5
- サーキットブレイカーなどのカスケード障害を防止する仕組み
*5:マイクロサービスアプリケーションにおけるService Meshを活用したセキュリティはNIST(米国標準技術研究所)が発行しているSP 800-204でも言及されている
ここからは、具体的にService Meshを実現するためのプロダクトを見ていきますが、その前にService Meshの一般的なアーキテクチャを補足します。
Service Meshで最も著名なプロダクトとして「Istio」があります。ここではIstioを参考にアーキテクチャを説明します。
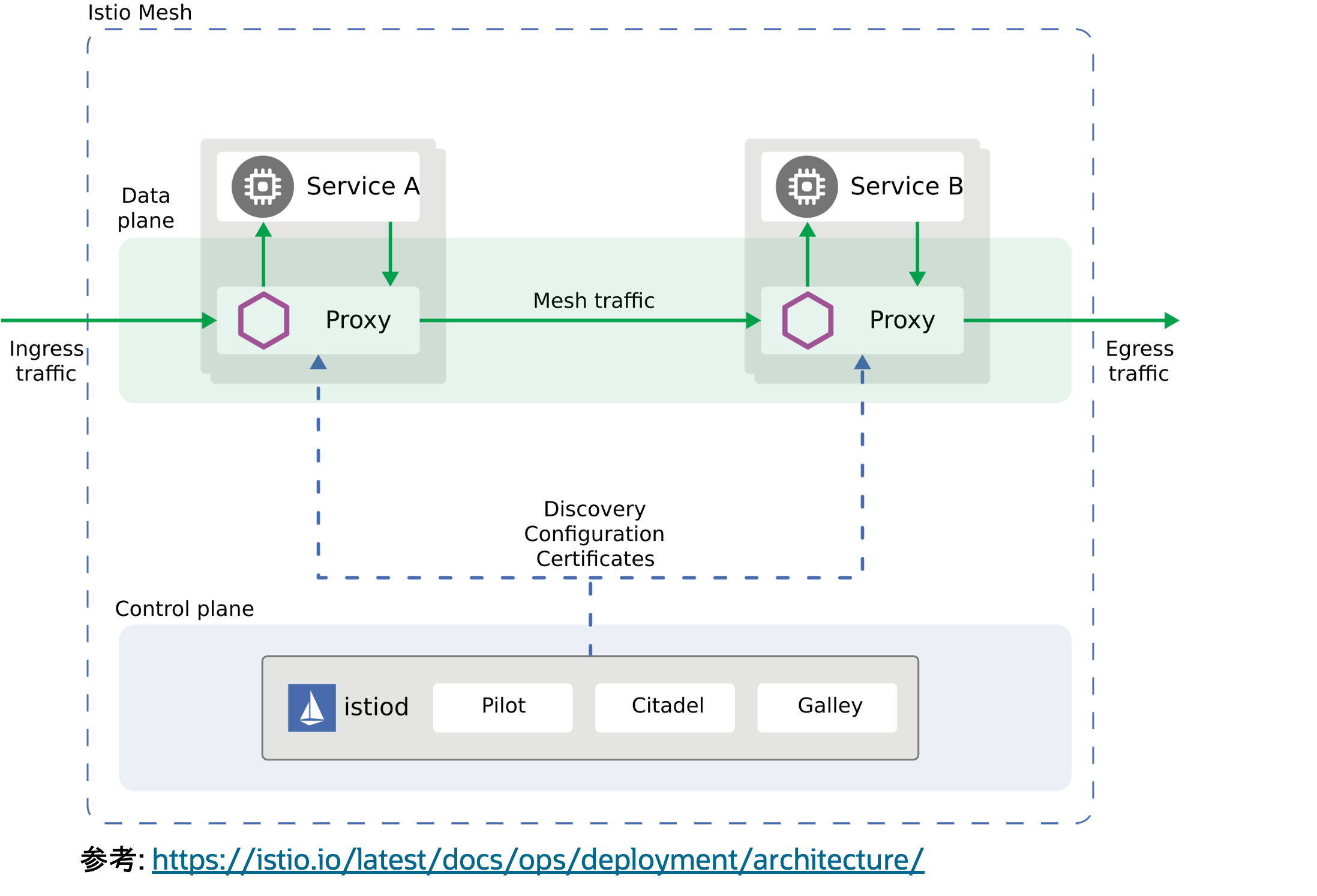
Istioは、主に「データプレーン」と「コントロールプレーン」という2つのコンポーネントから成り立っています。それぞれのコンポーネントの役割は以下の通りです。
- データプレーン
- サービス間通信をプロキシが担うことで通信を制御
- Kubernetesでは「サイドカー*6」としてPodごとに配置
- IstioではEnvoyをプロキシとして利用
- コントロールプレーン
- プロキシに適用するポリシーを一元管理
- Istioでは“istiod”というデーモンに統合
Service Meshを実現するプロダクトは複数存在しますが、基本的には同様のアーキテクチャが利用されています。
*6:サイドカーとは、Pod内のアプリケーションコンテナと連動する独立したコンテナを指す。最近ではサイドカーを利用しないアーキテクチャも存在するが、そちらについては後述する
- この記事のキーワード
この記事をシェアしてください
関連記事
コンテナをさらに活用しよう! 「マイクロサービス」と「サーバーレス」
2021年4月6日 7:06
Oracle Cloud Hangout Cafe Season 4 #2「Kubernetesのネットワーク」(2021年5月12日開催)
2024年2月20日 6:30
サービスメッシュを使ってみよう
2020年10月15日 6:30
Oracle Cloud Hangout Cafe Season5 #5「実験! カオスエンジニアリング」(2022年5月11日開催)
2023年5月18日 6:30
Gateway API(「kgateway」+「agentgateway」)でKubernetes上のAIツール接続を制御する
2月10日 6:30
サービスメッシュのLinkerd 2.9を紹介。EWMA実装のロードバランサー機能とは
2021年4月7日 7:18
バックナンバー
この記事の筆者

筆者の人気記事
Oracle Cloud Hangout Cafe Season5 #1「Kubernetes Operator 超入門」(2022年1月19日開催)
2023年3月17日 6:30
Oracle Cloud Hangout Cafe Season 4 #2「Kubernetesのネットワーク」(2021年5月12日開催)
2024年2月20日 6:30
Oracle Cloud Hangout Cafe Season6 #1「Service Mesh がっつり入門!」(2022年9月7日開催)
2023年6月22日 6:30
Oracle Cloud Hangout Cafe Season 4 #5「Kubernetesのオートスケーリング」(2021年8月4日開催)
2024年5月29日 6:30
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
