目次
- コンテナといえばあの「クジラ」?
- Dockerを知ろう! Dockerが登場したのは2013年頃です(図3)。Dockerの登場によりコンテナを使用するユーザが増え、システムエンジニア界隈でコンテナ技術が広まりました。コンテナの活用が広がることで、その管理ツールも多く開発されるようになりました。例えば、複数のコンテナ群を一括管理する「コンテナオーケストレーション」と呼ばれる分野の製品群が登場します。その中でも代表的なものが「Kubernetes」です(2014年 / Google)。同じ年にDocker社も「Docker swarm」を公開しました。この二つのオーケストレーションツールにより、複数のコンテナを効率よく維持・管理できるようになりました。 Dockerの大きな特徴は、どんなアプリケーションでも、場所を問わずに構築・移動・実行できるプラットフォームを提供することです。場所を問わずとは、物理環境でも、仮想化基盤でも、クラウド環境でも、さらにLinuxでもWindowsでも対応可能という意味です。その実現に欠かせない要素が「Docker Engine」と「Docker Hub」です。Docker Engineは、アプリケーション本体とそれを実行するための環境を1つのDockerイメージにまとめることができます。そして、移動先でDockerイメージに基づいてコンテナを実行させ、簡単かつ高速にアプリケーションを起動できます。 また、Docker HubはDockerイメージの移動や管理、Dockerイメージを共有する場としての役割を果たします(いわゆるリポジトリ)。Docker Hubの「Automated Build」の機能でGitHubと連携させれば、自動でDockerイメージを作成することもできます。 Dockerイメージを生成するための手順を定義したものを「Dockerfile」といいます。アプリケーションが動作する土台となるインフラ環境を構築するコマンドや手順などを所定の書き方でDockerfileに記載すれば、その作業は全部Dockerが自動でやってくれます。 昨今のコンテナ技術の広まりは、もはやコンテナ旋風とも言えるような、ITインフラ業界における大きな動きとなっています。その動きに拍車をかけるようにGoogle社が2014年に自社サービスをコンテナ化していることを公表し、コンテナ技術をトレンドとして世間に認識させました。これからもコンテナ技術、そしてコンテナの代表格であるDockerからますます目が離せませんね。Dockerイメージとは DockerイメージはUFS(Union File System)という、複数のファイルやディレクトリをレイヤ(層)として積み重ねて、仮想的に1つのファイルシステムとして扱う技術を用いています。土台となるベースレイヤの上にファイルやディレクトリなど複数のレイヤを積み重ねた読み取り専用のイメージレイヤがまとめられており、コンテナの起動時に読み書きが可能なコンテナレイヤが追加されてアプリケーションを実行します(図5)。 また、イメージレイヤの内容が変更される場合には、変更対象のレイヤを一度コンテナレイヤにコピーしてから変更内容を反映します。これをコピーオンライトと呼びます。さらにもう一つの特徴として、同一のホスト上で動く複数のコンテナがある場合は、イメージレイヤを共有できます。これにより、ホストのストレージ容量の圧迫を抑制できるようになります(図6)。前述したように、DockerイメージはDockerfileの記述に基づいて作成されますが、Dockerfileからベースイメージを使用してDockerイメージを作成することをビルドといいます。また、既に起動されたDockerコンテナからイメージを作成することをコミットと呼びます。 そして、作成したDockerイメージをプロジェクトメンバー間で共有する場合は、独自にイメージを登録するためのプライベートレジストリサーバを構築するか、DockerHubを使用します。DockerHubには誰でもDockerイメージを無料で保管や共有ができるパブリックリポジトリと、自分やプロジェクトメンバーだけが扱えるように制御できる有料のプライベートリポジトリの2種類があります。 DockerイメージをプライベートレジストリやDockerHubなどへアップロードすることをプッシュといい、逆にダウンロードすることをプルといいます。DockerにはDockerイメージにタグを付与してイメージを区別できる機能があり、イメージ毎にバージョンで管理したい場合にはタグにバージョン番号を指定します。ちなみにDockerイメージをプルする際に特定のタグを指定しない場合、Dockerはデフォルトで最新のという意味の”latest”タグを使用します(図7)。そのほかにも、DockerHubにはAutomated Buildという機能があり、GitHubなどと連携してDockerfileから自動でイメージを作成し公開することもできます(図8)。これらの技術を理解することでDockerイメージを効率よく管理でき、コンテナを上手に活用できるようになります。コンテナの性質を理解しよう! コンテナはホストOS上の1つのプロセスとして扱われます。プロセスなので、例えばプロセスがデータ処理の途中で削除されてしまえば、そこで処理していたデータは保存されず、なかったものとして消えてしまいます。このようにコンテナが削除され、再度起動しても削除前に実行していたデータが戻らないことを「状態を持たない」、あるいはステートレスといいます(図9)。コンテナはその性質上ステートレスであると言えます。一方で、Dockerではデータボリュームとデータボリュームコンテナの2つのボリュームにより、コンテナが削除されてもデータは残し、他のコンテナとデータを共有できます。このように、データをコンテナの削除から退避させることをデータの永続化といいます。またコンテナが削除されても退避していたデータに引き続きアクセスできる状態をステートフルといいます(図10)。ここで、データの永続化によるコンテナのライフサイクルの例を見てみましょう。まず、コンテナの中には、ECサイト(Webサービス)で使用するアプリケーションが入っているとします。また、そのアプリケーションはWebサービスが続いている間はずっと商品データを参照する必要がありますが、機能追加やバグ修正などのためのアップデートが発生し、頻繁にコンテナの入れ替えが行われるとします。 都度、入れ替えが発生するコンテナと、常に商品データを参照したいアプリケーションとでは、お互いのライフサイクルにズレがあります。このズレを合わせるために、データボリュームやデータボリュームコンテナを使用してデータの永続化を図る必要があるのです(図11)。 余談ですが、Dockerコンテナ内の状態は明示的にコンテナを削除しない限り維持されます。つまり一時停止や停止コマンドでは、まだデータは保たれているということです。 このように、コンテナは性質上ステートレスですが、データを永続化することにより活用の幅が広がっていったのです。複数のコンテナを効率よく管理しよう! さて、ここまでの説明でDockerによるコンテナの基本的な扱い方をある程度イメージできたかと思います。ここからは複数のコンテナを管理する方法を解説します。
- Dockerイメージとは
- コンテナの性質を理解しよう!
- 複数のコンテナを効率よく管理しよう!
- おわりに
コンテナといえばあの「クジラ」?
今回は、コンテナの動作に不可欠なコンテナエンジンについて、今やその実質的なデファクトスタンダードとして名を轟かせている「Docker」について紹介します。
前回で、図1のようにコンテナ技術を使った仮想化方式をコンテナ型仮想化と表現したことを憶えていますか。コンテナ型仮想化では、その実行基盤としてハードウェアとOSを共有し、コンテナを動作させるためのコンテナエンジンが必要となります。
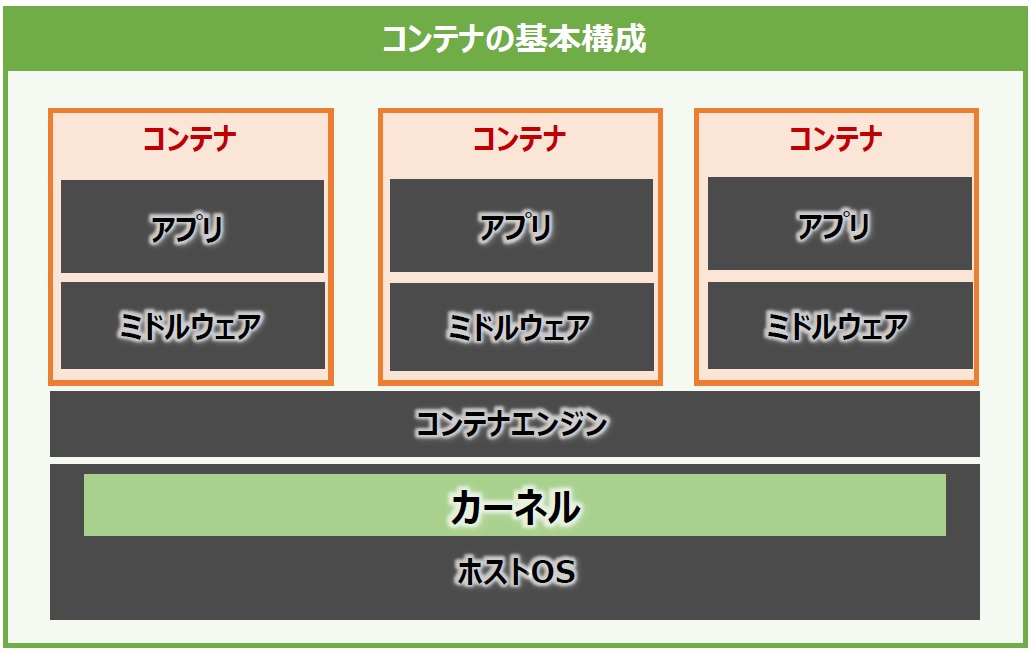
図1:コンテナの基本構成
これまで、コンテナエンジンには実に様々な製品が登場してきました。前回で紹介したIBM社の「LXC」(LinuX Containers / 2008年)は、コンテナエンジンに求められる「コンテナの分離」と「システムリソースの分割」の2つの機能を備えた最初のLinuxコンテナエンジンです。その後、Google社の「LMCTFY」(Let Me Contain That For You / 2013年)や、同年にDocker社が発表した「Docker」などが登場しました(後述)。
その中でも、大きな青いクジラが背中に大量のコンテナを載せたロゴのDockerは、Linuxコンテナエンジン界(?)では超がつくほど有名です(図2)。

図2:青いクジラのDockerロゴ
Dockerを知ろう!
Dockerが登場したのは2013年頃です(図3)。Dockerの登場によりコンテナを使用するユーザが増え、システムエンジニア界隈でコンテナ技術が広まりました。
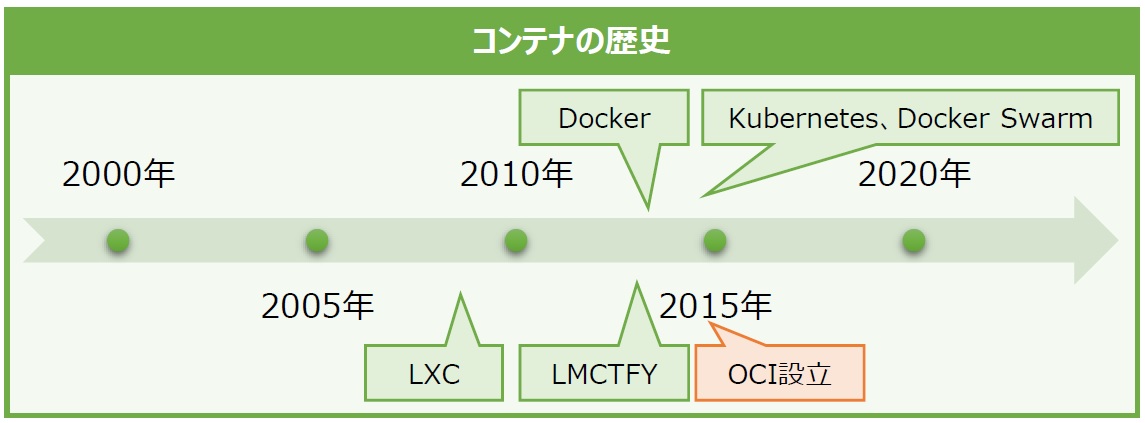
図3:コンテナの歴史(2000年代以降)
コンテナの活用が広がることで、その管理ツールも多く開発されるようになりました。例えば、複数のコンテナ群を一括管理する「コンテナオーケストレーション」と呼ばれる分野の製品群が登場します。その中でも代表的なものが「Kubernetes」です(2014年 / Google)。同じ年にDocker社も「Docker swarm」を公開しました。この二つのオーケストレーションツールにより、複数のコンテナを効率よく維持・管理できるようになりました。
Dockerの大きな特徴は、どんなアプリケーションでも、場所を問わずに構築・移動・実行できるプラットフォームを提供することです。場所を問わずとは、物理環境でも、仮想化基盤でも、クラウド環境でも、さらにLinuxでもWindowsでも対応可能という意味です。
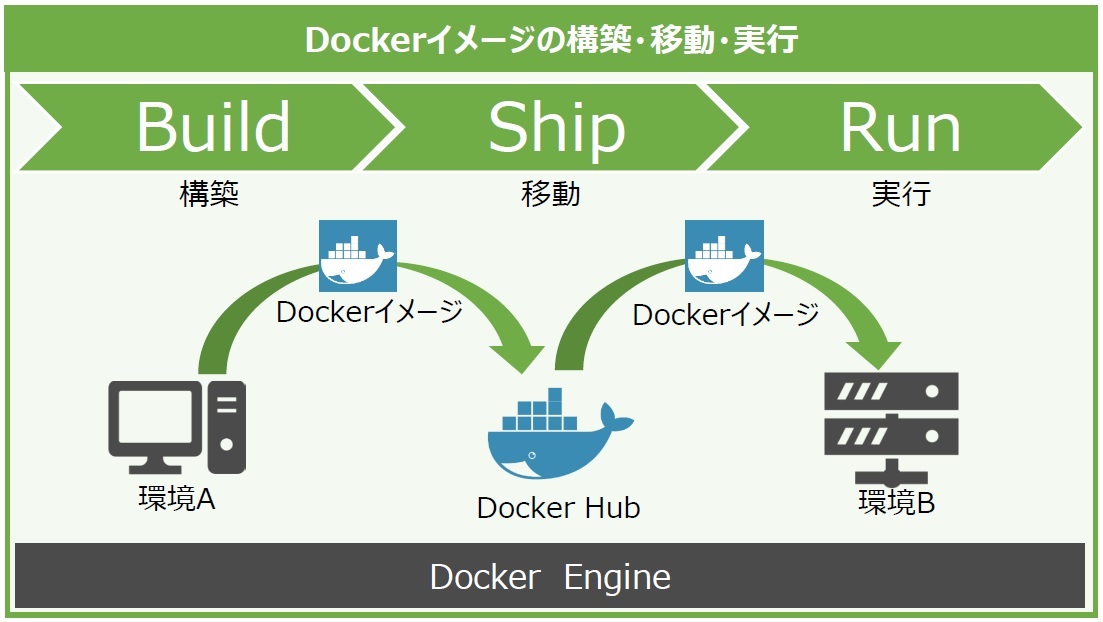
図4:Dockerイメージの構築・移動・実行
その実現に欠かせない要素が「Docker Engine」と「Docker Hub」です。Docker Engineは、アプリケーション本体とそれを実行するための環境を1つのDockerイメージにまとめることができます。そして、移動先でDockerイメージに基づいてコンテナを実行させ、簡単かつ高速にアプリケーションを起動できます。
また、Docker HubはDockerイメージの移動や管理、Dockerイメージを共有する場としての役割を果たします(いわゆるリポジトリ)。Docker Hubの「Automated Build」の機能でGitHubと連携させれば、自動でDockerイメージを作成することもできます。
Dockerイメージを生成するための手順を定義したものを「Dockerfile」といいます。アプリケーションが動作する土台となるインフラ環境を構築するコマンドや手順などを所定の書き方でDockerfileに記載すれば、その作業は全部Dockerが自動でやってくれます。
昨今のコンテナ技術の広まりは、もはやコンテナ旋風とも言えるような、ITインフラ業界における大きな動きとなっています。その動きに拍車をかけるようにGoogle社が2014年に自社サービスをコンテナ化していることを公表し、コンテナ技術をトレンドとして世間に認識させました。これからもコンテナ技術、そしてコンテナの代表格であるDockerからますます目が離せませんね。

Dockerイメージとは
DockerイメージはUFS(Union File System)という、複数のファイルやディレクトリをレイヤ(層)として積み重ねて、仮想的に1つのファイルシステムとして扱う技術を用いています。土台となるベースレイヤの上にファイルやディレクトリなど複数のレイヤを積み重ねた読み取り専用のイメージレイヤがまとめられており、コンテナの起動時に読み書きが可能なコンテナレイヤが追加されてアプリケーションを実行します(図5)。
また、イメージレイヤの内容が変更される場合には、変更対象のレイヤを一度コンテナレイヤにコピーしてから変更内容を反映します。これをコピーオンライトと呼びます。

図5:Dockerイメージのレイヤ図
さらにもう一つの特徴として、同一のホスト上で動く複数のコンテナがある場合は、イメージレイヤを共有できます。これにより、ホストのストレージ容量の圧迫を抑制できるようになります(図6)。

図6:イメージレイヤの共有図
前述したように、DockerイメージはDockerfileの記述に基づいて作成されますが、Dockerfileからベースイメージを使用してDockerイメージを作成することをビルドといいます。また、既に起動されたDockerコンテナからイメージを作成することをコミットと呼びます。
そして、作成したDockerイメージをプロジェクトメンバー間で共有する場合は、独自にイメージを登録するためのプライベートレジストリサーバを構築するか、DockerHubを使用します。DockerHubには誰でもDockerイメージを無料で保管や共有ができるパブリックリポジトリと、自分やプロジェクトメンバーだけが扱えるように制御できる有料のプライベートリポジトリの2種類があります。
DockerイメージをプライベートレジストリやDockerHubなどへアップロードすることをプッシュといい、逆にダウンロードすることをプルといいます。DockerにはDockerイメージにタグを付与してイメージを区別できる機能があり、イメージ毎にバージョンで管理したい場合にはタグにバージョン番号を指定します。ちなみにDockerイメージをプルする際に特定のタグを指定しない場合、Dockerはデフォルトで最新のという意味の”latest”タグを使用します(図7)。
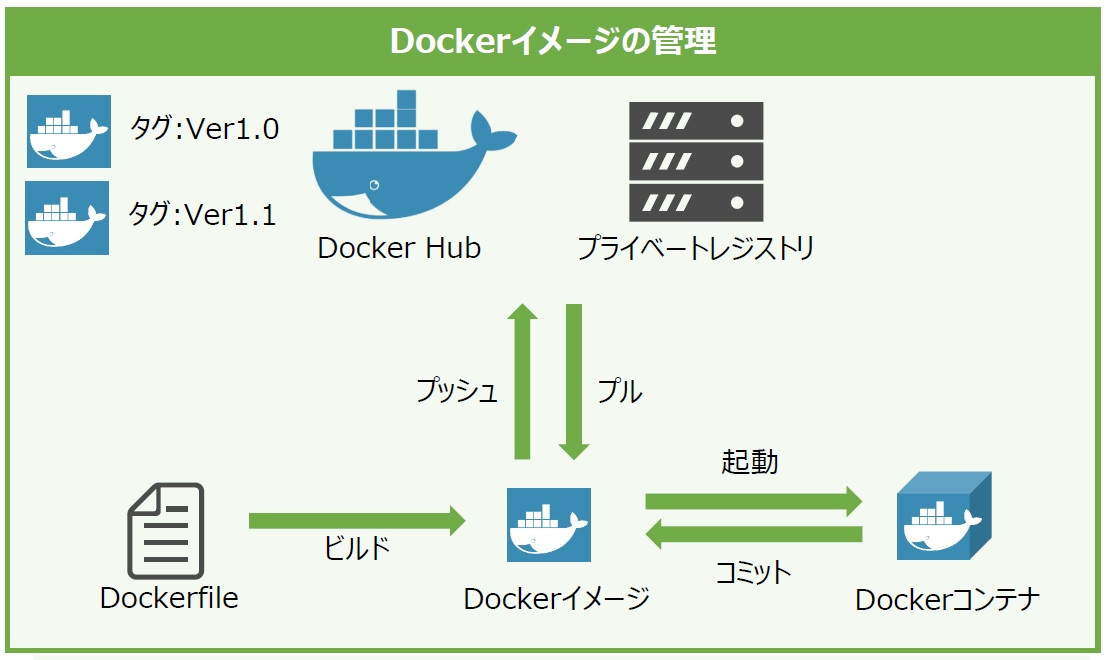
図7:Dockerイメージの管理
そのほかにも、DockerHubにはAutomated Buildという機能があり、GitHubなどと連携してDockerfileから自動でイメージを作成し公開することもできます(図8)。

図8:Dockerイメージの自動作成
これらの技術を理解することでDockerイメージを効率よく管理でき、コンテナを上手に活用できるようになります。

コンテナの性質を理解しよう!
コンテナはホストOS上の1つのプロセスとして扱われます。プロセスなので、例えばプロセスがデータ処理の途中で削除されてしまえば、そこで処理していたデータは保存されず、なかったものとして消えてしまいます。このようにコンテナが削除され、再度起動しても削除前に実行していたデータが戻らないことを「状態を持たない」、あるいはステートレスといいます(図9)。コンテナはその性質上ステートレスであると言えます。
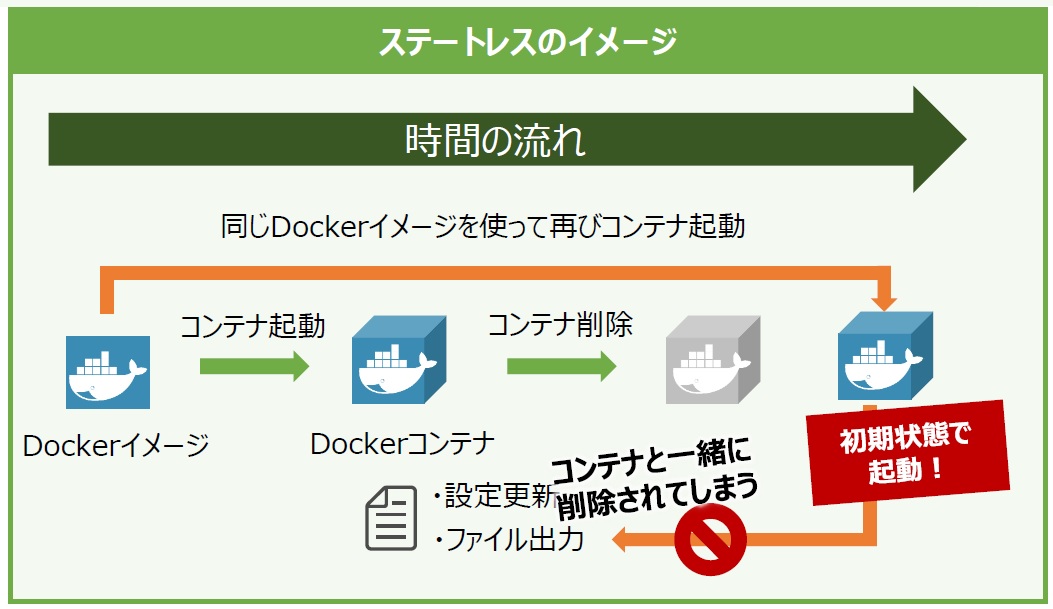
図9:ステートレス動作のイメージ
一方で、Dockerではデータボリュームとデータボリュームコンテナの2つのボリュームにより、コンテナが削除されてもデータは残し、他のコンテナとデータを共有できます。このように、データをコンテナの削除から退避させることをデータの永続化といいます。またコンテナが削除されても退避していたデータに引き続きアクセスできる状態をステートフルといいます(図10)。
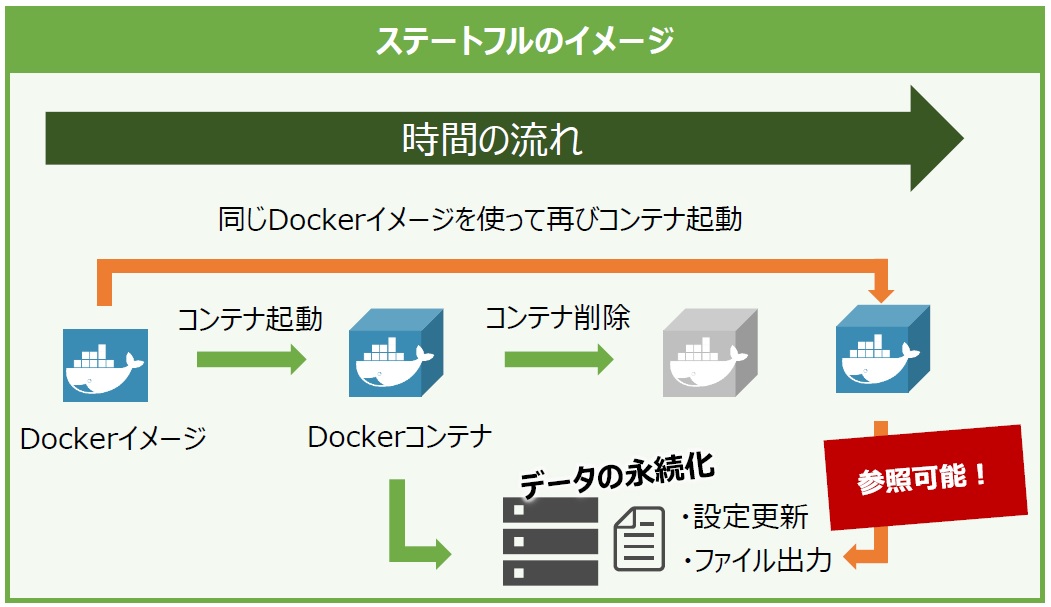
図10:ステートフル動作のイメージ
ここで、データの永続化によるコンテナのライフサイクルの例を見てみましょう。まず、コンテナの中には、ECサイト(Webサービス)で使用するアプリケーションが入っているとします。また、そのアプリケーションはWebサービスが続いている間はずっと商品データを参照する必要がありますが、機能追加やバグ修正などのためのアップデートが発生し、頻繁にコンテナの入れ替えが行われるとします。
都度、入れ替えが発生するコンテナと、常に商品データを参照したいアプリケーションとでは、お互いのライフサイクルにズレがあります。このズレを合わせるために、データボリュームやデータボリュームコンテナを使用してデータの永続化を図る必要があるのです(図11)。
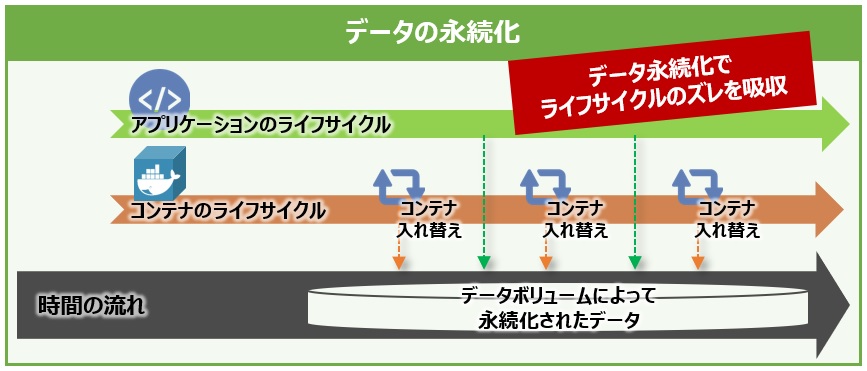
図11:データの永続化
余談ですが、Dockerコンテナ内の状態は明示的にコンテナを削除しない限り維持されます。つまり一時停止や停止コマンドでは、まだデータは保たれているということです。
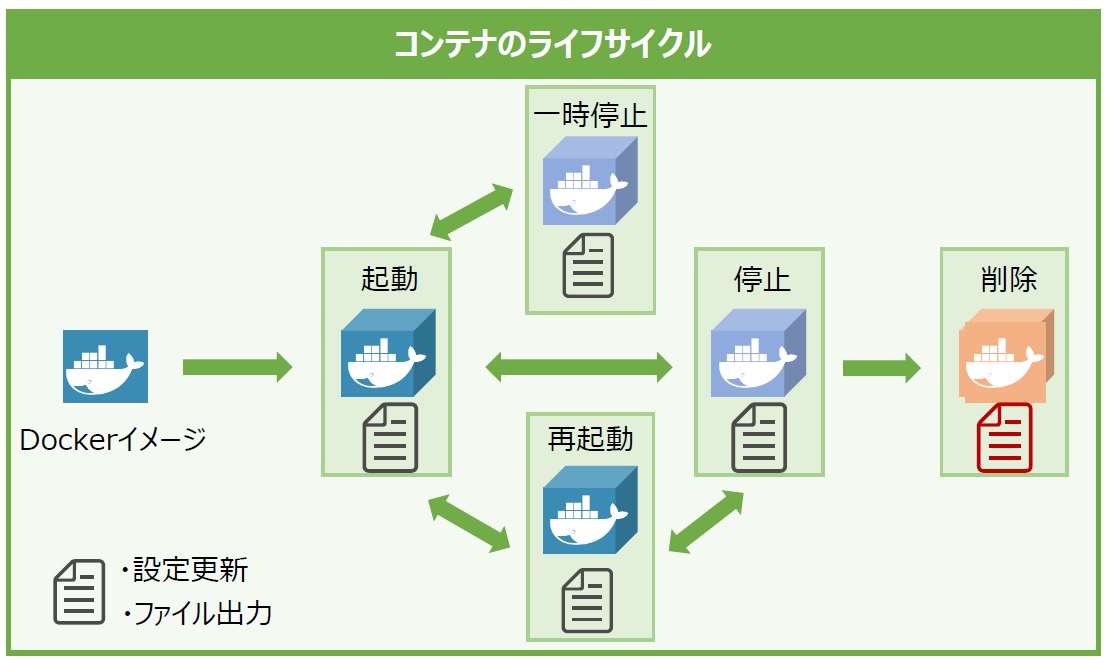
図12:コンテナのライフサイクル
このように、コンテナは性質上ステートレスですが、データを永続化することにより活用の幅が広がっていったのです。

複数のコンテナを効率よく管理しよう!
さて、ここまでの説明でDockerによるコンテナの基本的な扱い方をある程度イメージできたかと思います。ここからは複数のコンテナを管理する方法を解説します。
一般的に、コンテナには「1つのコンテナが扱うプロセスは1つのみ」とする考え方があります。例えば、2つの異なるプロセスを1つのコンテナに内包させたとしましょう。もし片方のプロセスのアップデートに伴ってコンテナを入れ替える必要性が出てきた場合、関係のないもう片方のプロセスまで影響を受けてしまいます。これは良いやり方とは言えません。そのような理由もあって、基本的に「1コンテナ1プロセス」が推奨されているのです(図12)。
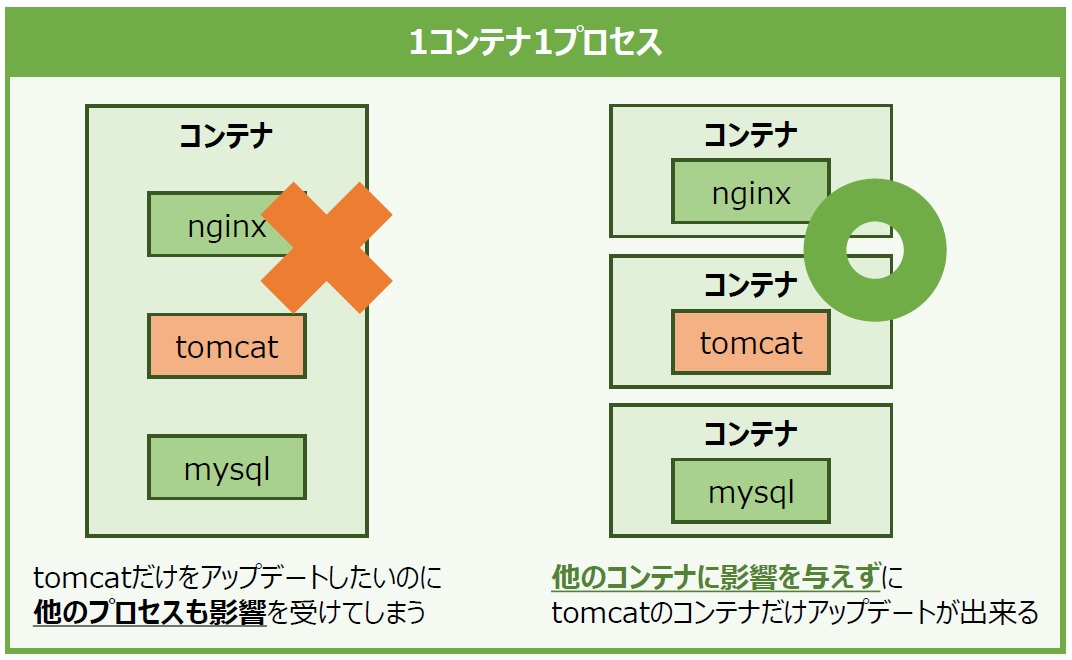
図13:1コンテナ1プロセス
では「1コンテナ1プロセス」の考えに基づいてアプリケーションを開発するとしましょう。小規模なものであればコンテナの運用に大きな問題は起こらないと思いますが、扱うコンテナが増えていけば管理の負担も大きくなり、アプリケーション開発に専念できなくなってしまいます。
そこで、Dockerコンテナ管理を楽にする「Docker compose」や「Docker swarm」といったツールの出番です。Docker composeは簡単にいうと複数のコンテナを一括で管理できるツールです。アプリケーションが使用するDockerイメージやネットワーク、ボリューム、再起動ポリシーなどをそれぞれYAML形式でcomposeファイルとして定義します。
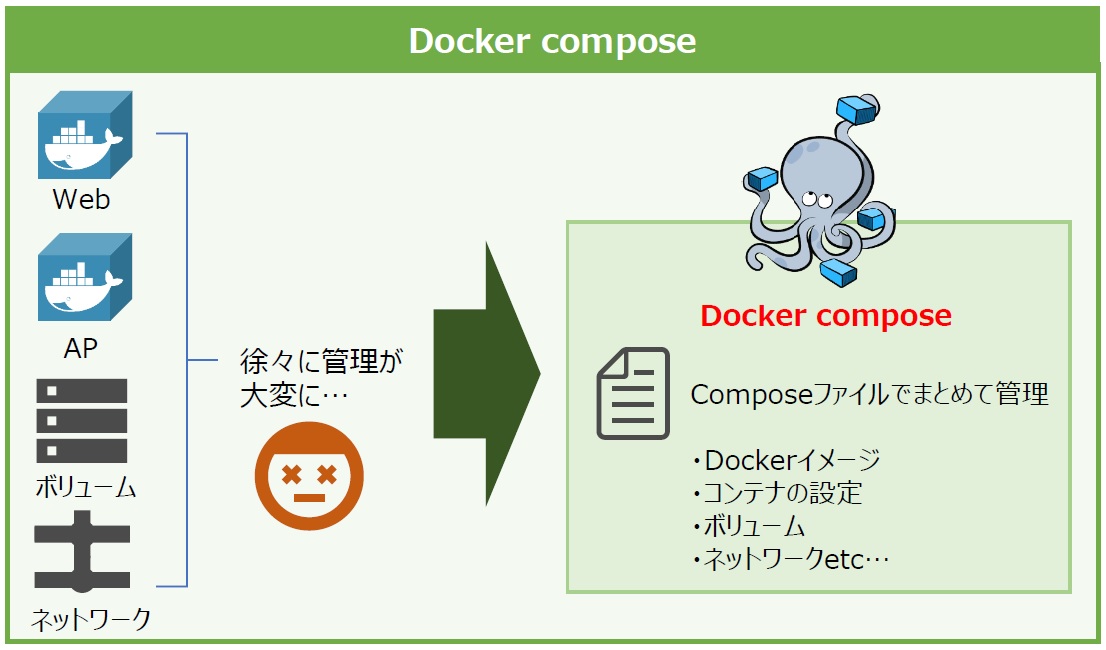
図14:Docker composeのイメージ
※YAMLとはスペースやインデントにより構造化されたデータを階層的に表現するフォーマットの1種です。よく比較されるものにJSONがありますが、JSONとの違いはコメントが記入できること、階層的な表現で可読性が高いことです。
composeファイルを使用すると、1つのコマンドでコンテナのビルドや複数コンテナをまとめて起できるようになります。Docker composeで使用するコマンドはDockerコマンドと似ているため、簡単に覚えられることも特徴の1つです。一方のDocker swarmは、Dockerが備えるクラスタ管理機能です。
例えば、扱うDockerコンテナが増えて1つのホストではまかないきれなくなり、追加で別のホストを用意したとしましょう。Docker swarmには、これらの複数のホストを仮想的に束ねて1つのホストとして扱う機能があります。この束ねられた複数のホストを“クラスタ”と呼びます。
Docker swarmにより、Docker composeで定義した複数のコンテナをクラスタ上(複数のホスト)に起動することで、ホストへの負荷を分散できるようになります(図14)。このほかにも、Docker swarmにはコンテナ管理者の負担を軽減してくれる様々な機能があります。
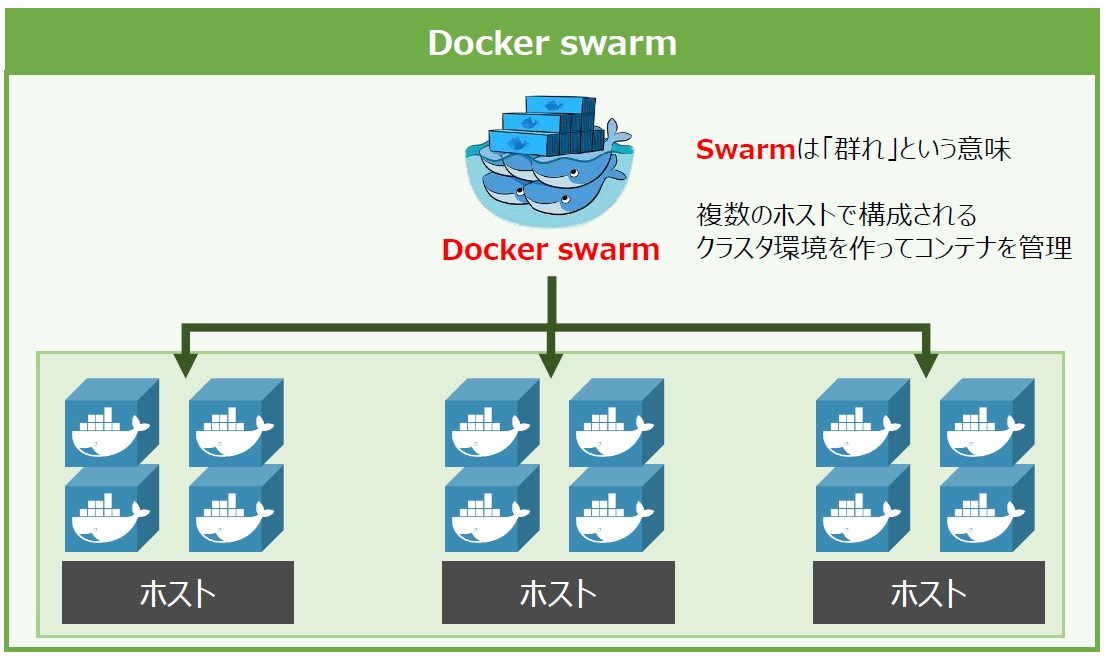
図15:Docker swarmのイメージ

おわりに
今回は、コンテナの動作を支えるコンテナエンジンの中でも代表格といえるDockerを紹介しました。コンテナをよく知らないエンジニアの方でも、Dockerという名前くらいは聞いたことがあると思います。そのくらい、Dockerは今日のコンテナ界を代表する製品へと成長を遂げたのです。
次回はいよいよ、コンテナオーケストレーションプラットフォーム「Kubernetes」の登場です。次回もお楽しみに!

この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者

Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
