分散処理システムの検証をサービスとして提供するJepsenに注目
分散処理システムの検証をビジネスにしたJepsenのサービスを紹介する動画を解説する。
2020年5月13日 6:00
昨今クラウドネイティブなシステムが注目されている理由は、オンプレミスのコンピューティング資源とパブリッククラウドと組み合わせて使うことで、開発から実装までの時間を短縮できること、安価なサーバーを複数使用した分散型システムによって、突然のアクセススパイクなどにも対応できることなどが挙げられるだろう。
しかしスケールアウトできるシステムを構築することは、実際にはシングルサーバーとモノリシックなアプリケーションによるシステム開発と比較すると、はるかに難しい。複数のサーバーを協調させ、いつでも障害やバグによってサーバーやソフトウェアが動かなくなることを前提としてシステムを実装する必要があるからだ。これはサーバーというハードウェアだけではなく、OS、ミドルウェア、ネットワークコンポーネント、アプリケーション、さらにはモニタリングなどのシステムに至るまで、多くのムービングパーツが連動して動くことを常に意識しなければいけないことを示している。
そのようなクラウドネイティブなシステムを実装する上で、カオスエンジニアリングという概念がNetflixという動画配信サービスを行う企業から出てきたのは必然だろう。複数のサーバーから構成されるクラスター、その上で動くデータベースやアプリケーション、それらが常に100%の状態で稼働していると想定するのではなく「何かが壊れても動き続けるシステム」を目指すことで、現実の稼働状況に近い状態をいかに維持するか? これを実現するのがカオスエンジニアリングだ。
カオスエンジニアリングのリーディングベンダーであるGremlinは「システムが壊れても動き続ける」ために「Break things on purpose(わざとモノを壊す)」というマントラを掲げ、Chaos Toolkitというシステムを壊すツールを開発し、ビジネスとして運用している。しかしGremlinの提供するツールではシステム全体を俯瞰して一部を壊すことを目的としているため、システムの中で使われる分散型システムを構築するためのコンポーネント自体にバグがあるかどうかは検知できない。
今回は「分散型ソフトウェア単体が分散型システムの要件に適合するのか?」の検証をビジネスとして提供するJepsenを紹介したい。筆者がJepsenに注目したのは、CNCF(Cloud Native Computing Foundation)がetcdの検証のためにJepsenに検証テストを依頼し、そのテストにパスしたというニュースに触れたからだ。
参考:Jepsenによるetcd 3.4.3のテストレポート
CNCFはThe Linux Foundation配下のオープンソースソフトウェアのための非営利団体、そしてCNCFにホストされている最も大きいソフトウェアがKubernetesであり、Kubernetesの中核にetcdが使われていることに説明は不要だろう。
複数のサーバーをまたいでデータを保存し、サーバーが追加、削除されたとしても常に最低3台のシステムにデータを分散させることで分散処理を行う仕掛けの大本は、分散合意アルゴリズムであるPaxos、そしてそのシンプルな実装であるRaftだ。そのRaftを元にして開発されたのが、分散型Key-Value Storeであるetcdというわけだ。
Jepsenによれば、etcdの初期バージョン0.4.1には多くの不具合が発見されたという。しかし3.4.3というバージョンに至って、多くの機能が実装され確実に分散処理に利用可能なプラットフォームとして稼働できることを証明している。このレポートで重要なのは、ドキュメンテーションについても言及していることだろう。分散システムを実装する際に、プラットフォームがどこまで機能として実装しているのかを簡単に実機で試すのはコストが高い。そのためドキュメントとして明記されていることを信じて実装することになるが、その際に「その仕様書がどこまで正しいのか?」についても検証しているのは徹底していると言える。コードの実装に対して常にドキュメンテーションの更新が遅れがちなオープンソースプロジェクトには、耳が痛い話だろう。
今回は、2018年に行われたGoto2018カンファレンスでJepsenのKyle Kingsbury氏が行ったプレゼンテーションをベースに、分散システムの必要要件について紹介したい。
GOTO2018の動画:GOTO 2018 ? Jepsen 9: A Fsyncing Feeling ? Kyle Kingsbury
公式サイト:Jepsen
Jepsenはetcd以外にもMongoDB、中国のPingCAPが開発をリードするNoSQLのTiDB、TwitterとCouchbaseに所属していたエンジニアが作ったFaunaDBなど、多くの分散処理系システムの検証を行っている。

プレゼンテーションを行うJepsenのKyle Kingsbury氏
Kingsbury氏は分散型システムにおいて「正常」を保つことの難しさを強調した。複数のプロセスが同時にデータベースにアクセスすることなどを例に挙げて説明を行ったが、過去のモノリシックなシステムからさらに複雑になっている要点として、アプリケーションだけではなくWebサーバーやロードバランサー、セキュリティのためのプロセスなど、多くのプロセスが一つのデータアクセスに関与しており、結果として「何が悪くて失敗したのか?」「どこまでが正常に実行されたのか?」の可視化が困難だということを解説した。

どのレベルで失敗が発生したのかを検知することが必要
そのためにシステムが安全に実行されていると知ることが必要であり、そのシステム自体を計測することが重要だと語った。

システム自体を計測する仕組みが必要
例えばデータベースであれば、クライアントからのアクセスを受けて結果を返すのが仕事になるが、その詳細な構造を検査するのではなく、あくまでもリクエストと処理結果だけに注目してシステムを評価するというのがJepsenの発想だ。
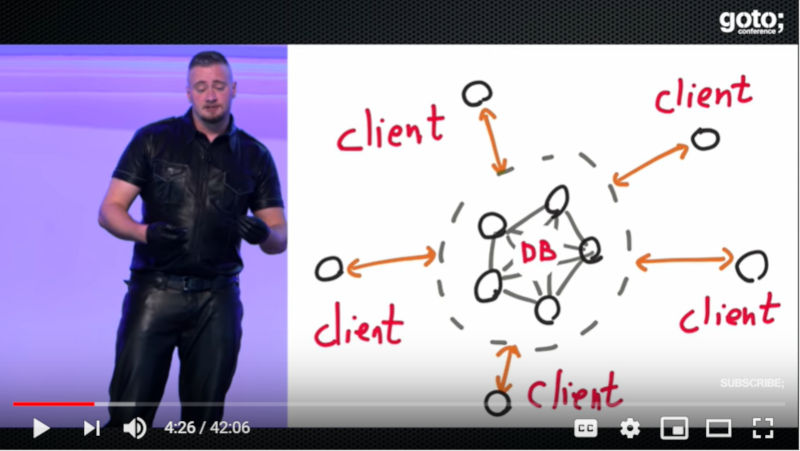
データベースとクライアントの処理に注目
このスライドにあるように、データベースそのものの処理の中身には触れずに「どのようなリクエストを処理したのか?」「その結果は正しかったのか?」だけに注目してテストを行うという。

クライアントがランダムなリクエストを送り、それを処理する結果を検証する
ここで注目したいのは、リクエストの結果として「ok」(成功)と「fail」(失敗)だけではなく、他のレスポンスがあり得ると明記していることだろう。

ok、failともう一つのレスポンスに注目
単にある処理が行われたとしても、正常と失敗以外にもさまざまな結果があることを前提にシステムを検証する。多数のプロセスが関係し合う分散型システムでは、その前提が重要だという指摘だ。

操作を実行し、その結果を記録し、後からモデルに照らして検証する
そしてテストに際してネットワークを切断するという手法を使っていることを紹介した。これはカオスエンジニアリングにも通じる方法で、プロセス間の通信を強制的に遮断することで、どういう結果が返ってくるのかを検証する。そしてここから複数のシステムにおいてJepsenの検証テストの結果を紹介することになった。いくつかのシステムでの分散処理の検証結果があるが、Cassandra、Kafka、etcdなどについて紹介を行った。

Cassandraの結果

Kafkaの結果

Elasticsearchの結果

MongoDBの結果
分散処理で難しいのは複数のプロセスが絡む検証であり、具体的にその難しさを実例で示したのが次のスライドだ。
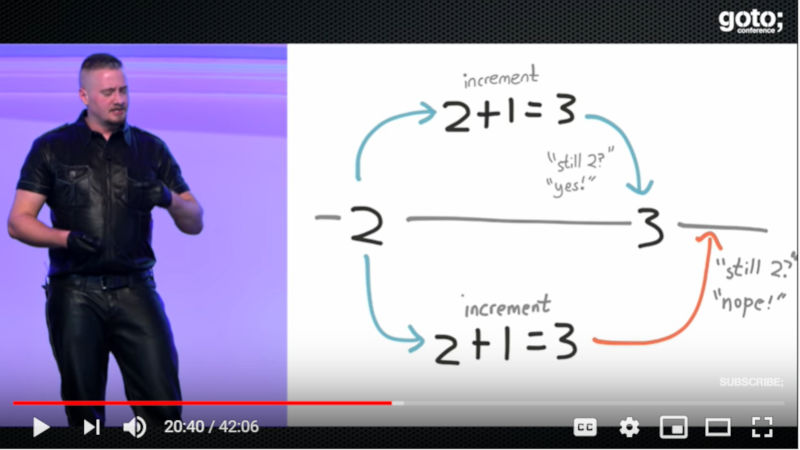
1つの値を更新する2つのプロセス。それぞれが「2+1」を実行
更新に際して、そのデータをロックすることで複数の更新が正しく行われることを保証するのが正しいやり方だが、「どういう時にロックが行われるか?」を検証するのは難しい。特に分散型システムにおけるロックについては、完全なシステムはないと想定するべきだと言うのが次のスライドだ。

分散型システムにおけるロックは信用するべきではない
ここでは別の例を挙げて複数のプロセスがデータを更新するシステムを解説している。難しいのはetcdのよう複数のノードがリーダーの選出や投票などの細かなプロセスを経て分散処理を実装しているという仕組みを理解しないと、異常時の想定そのものができないという部分だろう。マスター/スレーブという関係ではなく、どのノードもマスターになれるし、いつそのノードがダウンするかはわからないという前提をした上で検証する必要がある。
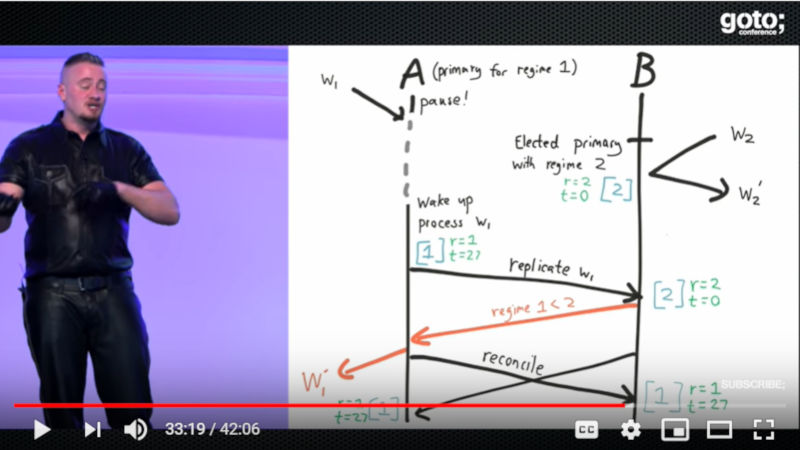
複数のプロセスが絡むシステムのデータ整合性問題
そして分散型システムにおいては、何よりも「ドキュメントを読むことでそのシステムが想定している分散処理の詳細を知るべき」だと提言した。

ドキュメントを読めと提言
またそのドキュメントに書かれているStrictやACID、Strongなどと言った用語には十分に注意を払い、「どういう意味でその用語を使っているのか」「何が実装されているのか」を理解するべきだと語った。
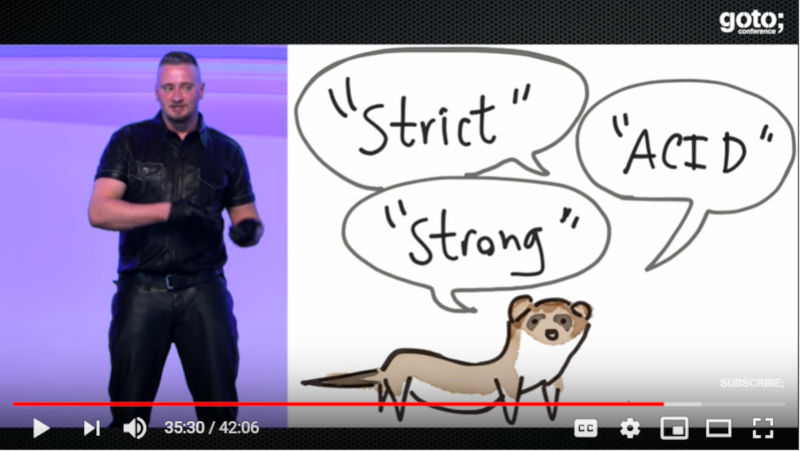
Strict、ACID、Strongなどの詳細は実装に要注意
自社の分散型システムを検証するにはマクロ的にはカオスエンジニアリングのツールを利用するという方法論もあるが、Jepsenのように分散型システムの検証に特化したベンダーが行った検証結果を参考にしながら、利用するソフトウェアの特性と限界を理解した上で利用することを推進するべきだろう。
かつてはベンダーが保証してくれたソフトウェアの仕様も、オープンソースソフトウェアにおいては利用するエンジニア自身の責任になってしまう。特に検証が困難な分散処理においては、Jepsenの検証結果は理解しておいて損はないだろう。
- この記事のキーワード
この記事をシェアしてください
関連記事
KubeCon+CloudNativeCon NA 2020 IntuitとMayaDataによるカオスエンジニアリングのセッション
2021年3月15日 12:07
KubeConサンディエゴ最終日のキーノートはカオスエンジニアリング
2020年3月4日 5:50
Elastic、アプリケーションパフォーマンスモニタリングを公開
2018年3月22日 11:00
KubeConChinaで見たKubernetesエコシステムを支えるツールたち
2018年12月26日 6:00
Kubernetes Forum@ソウル、YouTubeの本番で利用されるVitessのセッションを紹介
2020年3月26日 6:00
Kafka on Kubernetesを実現するStrimziに特化したカンファレンスStrimziCon 2024からキーノートを紹介
2024年7月8日 6:01
バックナンバー
この記事の筆者

筆者の人気記事
SASEのCato Networks、CEOによるセミナーとインタビューを紹介
2020年4月16日 6:00
Rustのエコシステムの拡がりを感じるデスクトップアプリのためのツールキットTauriを紹介
2022年12月16日 6:00
Zabbix式オープンソースの秘密に迫る
2025年1月31日 6:00
WebAssemblyとRustが作るサーバーレスの未来
2020年4月21日 6:00
三菱電機が設立したOSPOのメンバーにインタビュー。「インナーソース」を戦略的に使う背景とは?
2025年10月3日 6:00
エンタープライズLinuxを目指すSUSE、Red Hatとの違いを強調
2015年2月3日 19:00
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
