目次
- はじめに
- RBAC(Role Base Access Control)
ここでは、Kubernetesから少し離れて、まずシステムへのアクセス制御方法の話をします。
RBACは「Role Base Access Control」の略称で、名前の通り個々のユーザーのアカウントではなくロール(役割)を軸にポリシーを柔軟に設定できるアクセス制御方法です。そのため、RBACは組織内での意味を考慮して、ロールに割り当てる操作そのものにオブジェクト(物)へのアクセス権を設定します。
組織内では、さまざまな職務権限に応じて複数のロールが作成されます。従業員(またはその他のシステムユーザー)には特定のロールが割り当てられ、システムの特定の機能を実行するための権限を取得します。ユーザーの権限は直接割り当てられるのではなく、ロールを通じて取得するだけなので、個々のユーザーのアカウントに適切なロールを割り当てることでユーザー権限を管理します。このような方法により、ユーザーの追加や部署変更などの一般的な操作が簡単になります。
RBACを会社の組織、つまり部門ごとの管理資料への操作とアクセス権に当てはめて考えてみましょう。例えば、ある会社の営業部長、営業部社員、開発部長、開発部社員に、売上を管理する営業部管理資料と開発工程を管理する開発部管理資料への操作およびアクセス権を割り振るとします。部長は部内資料に限り全操作が行え、社員は部内資料の参照と更新のみが行えます。
このような役割と権限の分割がある場合、営業部の竹村さんが営業部から開発部へ異動をすると役割が変わるため、竹村さんは営業部の資料が見られなくなります(図1)。図1:RBAC→役割(Role)ベースのアクセスコントロールシステムKubernetesの話に戻りましょう。Kubernetesでは、このRBACを用いてリソースへのアクセス制御を行っています。 RBACに関連するリソースにはRole、ClusterRole、RoleBinding、ClusterRoleBindingがあり、それぞれ与える影響範囲と機能が異なります。RoleとClusterRoleは、どのKubernetesのリソースにどのような操作を許可するかを定義し、RoleBindingとClusterRoleBindingは、どのRoleやClusterRoleをどのアカウントに紐付けるかを定義します。
- Kubernetesの周辺ツール
- おわりに
はじめに
前回に引き続き、今回もコンテナマネジメントのデファクトスタンダードといわれる「Kubernetes」について、Kubernetes編の後編としてKubernetesにおけるアクセスコントロールの仕組みや、Kubernetesと一緒に使用するツール群を紹介します。
RBAC(Role Base Access Control)
ここでは、Kubernetesから少し離れて、まずシステムへのアクセス制御方法の話をします。
RBACは「Role Base Access Control」の略称で、名前の通り個々のユーザーのアカウントではなくロール(役割)を軸にポリシーを柔軟に設定できるアクセス制御方法です。そのため、RBACは組織内での意味を考慮して、ロールに割り当てる操作そのものにオブジェクト(物)へのアクセス権を設定します。
組織内では、さまざまな職務権限に応じて複数のロールが作成されます。従業員(またはその他のシステムユーザー)には特定のロールが割り当てられ、システムの特定の機能を実行するための権限を取得します。ユーザーの権限は直接割り当てられるのではなく、ロールを通じて取得するだけなので、個々のユーザーのアカウントに適切なロールを割り当てることでユーザー権限を管理します。このような方法により、ユーザーの追加や部署変更などの一般的な操作が簡単になります。
RBACを会社の組織、つまり部門ごとの管理資料への操作とアクセス権に当てはめて考えてみましょう。例えば、ある会社の営業部長、営業部社員、開発部長、開発部社員に、売上を管理する営業部管理資料と開発工程を管理する開発部管理資料への操作およびアクセス権を割り振るとします。部長は部内資料に限り全操作が行え、社員は部内資料の参照と更新のみが行えます。
このような役割と権限の分割がある場合、営業部の竹村さんが営業部から開発部へ異動をすると役割が変わるため、竹村さんは営業部の資料が見られなくなります(図1)。

図1:RBAC→役割(Role)ベースのアクセスコントロールシステム
Kubernetesの話に戻りましょう。Kubernetesでは、このRBACを用いてリソースへのアクセス制御を行っています。
RBACに関連するリソースにはRole、ClusterRole、RoleBinding、ClusterRoleBindingがあり、それぞれ与える影響範囲と機能が異なります。RoleとClusterRoleは、どのKubernetesのリソースにどのような操作を許可するかを定義し、RoleBindingとClusterRoleBindingは、どのRoleやClusterRoleをどのアカウントに紐付けるかを定義します。

Kubernetesの周辺ツール
ここからは、Kubernetesと一緒に使用されるツール群を紹介していきます。
Helm
「Helm」はCNCFのプロジェクトの中でも成熟したプロジェクトとして扱われる「Graduated Project」の1つで、Helmの公式サイトのトップに書かれている通り、Kubernetes向けのパッケージマネージャにあたります(※「Helm is the best way to find, share, and use software built for Kubernetes.」(訳:Helmは、Kubernetesのために構築されたソフトウェアを検索・共有・使用するための最良の方法です)。パッケージマネージャは、OS上にソフトウェアをインストール/アンインストールする際にソフトウェア間やライブラリとの依存関係を包括管理してくれます。ディストリビューションによって違いはありますが、Linuxでは「yum」や「apt」が有名ですね。
Helmは「Chart」と呼ばれるパッケージテンプレートを用いてソフトウェア構成を定義していきます(図2)。また、Chartは公式のレジストリで公開されているものであれば、誰でもそれらを利用してKubernetes上にアプリケーションをデプロイできます。なお、自身で作成したChartを公開せずにプライベートレジストリを構築して管理するといった使い方もできます。
HelmによってChart化されているアプリケーションであれば、複雑な記述が必要なManifestファイルを用意しなくても、コマンド1つで容易にKubernetes上にアプリケーションをデプロイできるようになります。
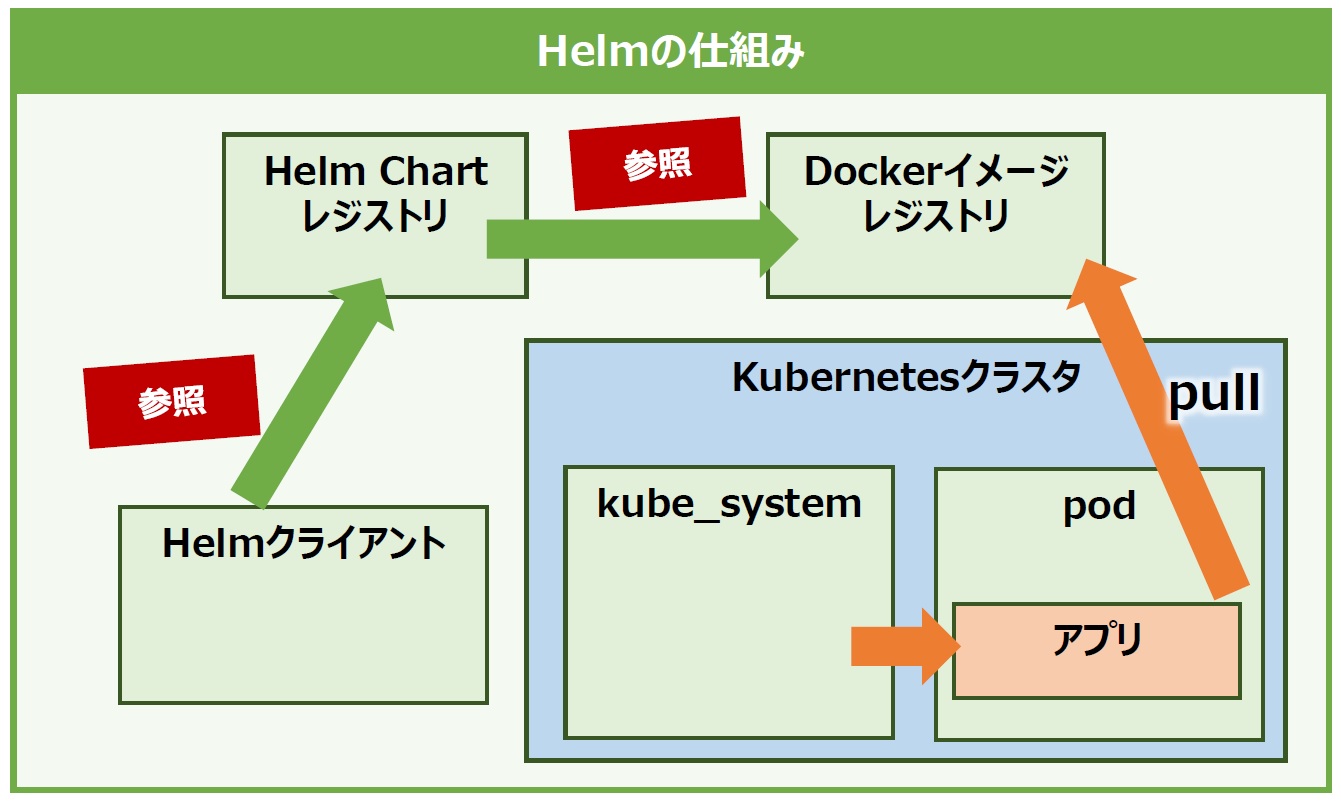
図2:Helmの仕組み

CoreDNS
TCP/IPの世界ではIPアドレスを使ってアクセスしたいサーバと通信を行っています。一方、私たちがWebへアクセスする際は、URLをブラウザのアドレスバーに打ち込んだり、URLリンクをクリックしたりすると思います。
もちろん、アドレスバーにIPアドレスを打ち込んでアクセスすることもできますが、普段からアクセスするサイトのIPアドレスを覚えておくことは難しいでしょう。
この問題を解決するために「DNS」と呼ばれる仕組みがあります。DNSサーバはDNSレコードを元にIPアドレスとURL(正確にはドメイン部分)を相互変換するサービスです。普段私たちがURLを使って簡単にWebサイトへアクセスできるのは、このDNSサーバがIPアドレスに変換してくれるおかげなのです。
KubernetesクラスタにおいてDNSの役割を果たしてくれているコンポーネントが「CoreDNS」です。CoreDNSはクラウドネイティブなDNSで、KubernetesクラスタにおけるDNSサービス(名前解決およびサービスディスカバリ)を担っています。CoreDNSはレガシーなkube-dnsを置き換えるもので、現在のKubernetes(v1.13以降)ではデフォルトのDNSサービスとして採用されています。
CoreDNSの特徴は非常に軽量なこと、プラグイン方式を採用することでetcdやhostsなどの様々なバックエンドに設定を格納・管理できる拡張性の高さです。Kubernetesにおいても、デフォルトでConfigMapに設定情報を格納したり、etcdを利用すればコマンド1つで設定情報を編集できたりなど、様々な展開方法があります。
またKubernetesクラスタ内にCoreDNS用のPodを複数展開することで、CoreDNSへのDNSリクエストを分散させて処理能力を向上できるほか、クラスタのSelf-Healing機能を利用して高可用性を確保することもできます(図3)。
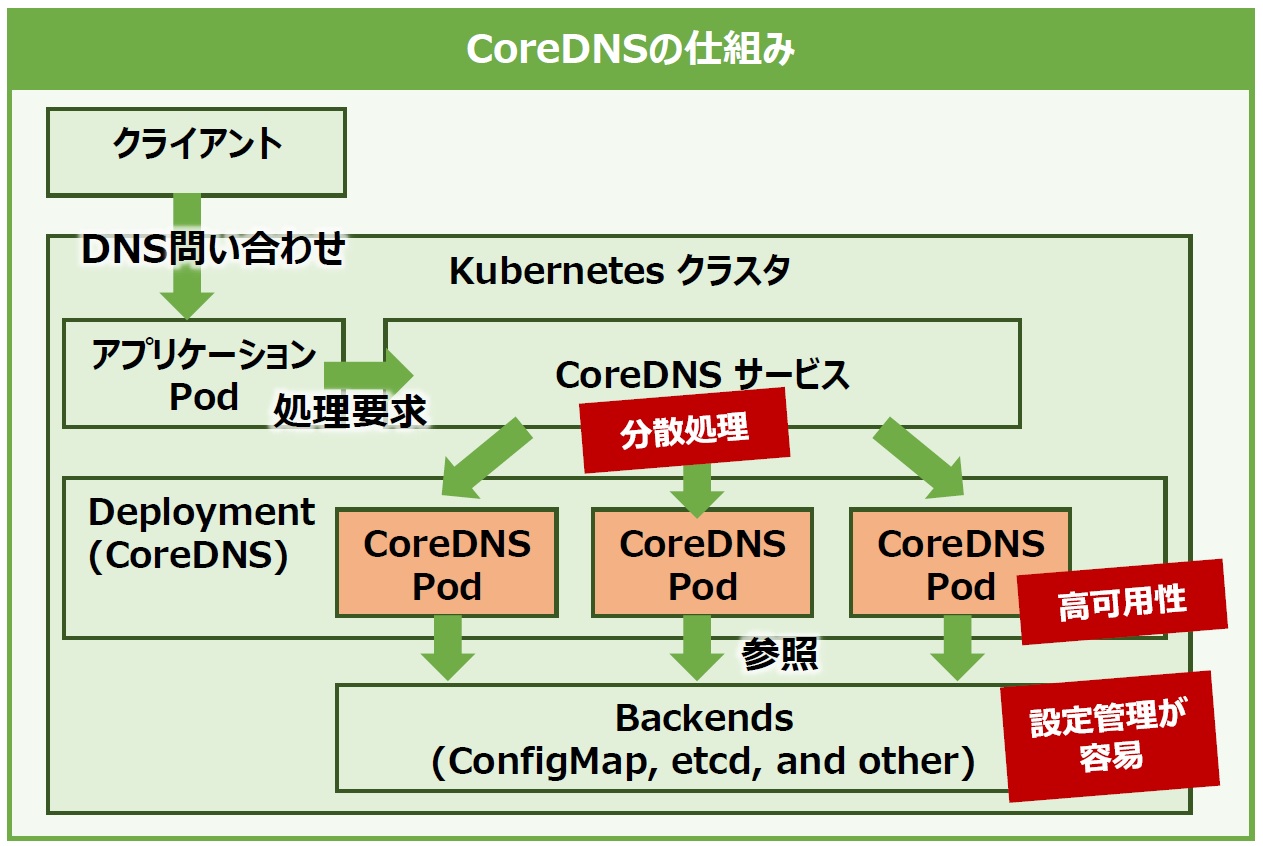
図3:CoreDNSの仕組み

Prometheus
少し前までのシステムは、サーバ毎に役割が固定化されていました。そのため、監視ツールも特に考えることなく監視用Agentを入れることで容易に監視が可能でした。
一方、現在ではコンテナやサーバが高負荷となった場合に自動でサーバを増やしてくれるオートスケール機能を備えるサービスが増えてきています。このようなシステムでは、従来通りのAgentによる監視が難しくなりました。
このような状況の変化により、動的なサービスにも適用できる「Prometeus」が注目されるようになりました。Prometheusは、元々Google社で使用されている社内監視ツール「Borgmon」をベースに作成されたオープンソースソフトウェアです。
その特徴はPull型という監視方法を採用している点です。これまでの固定的なサーバだけでなく、オートスケール機能を搭載したサーバ群やコンテナ群など、動的な対象の監視を得意としています。
一般的に利用されているJP1やDatadogなどの監視ソフトウェアでは、監視対象サーバにAgentを組み込み、Agentが取得した情報を監視サーバに送ることで監視するAgent型を採用しています(図4)。言い換えれば、Agent型の監視ソフトウェアは、忍者やスパイといったイメージでAgentが取得した各種情報を必要としている相手に送ることで監視できる仕組みと言えます。
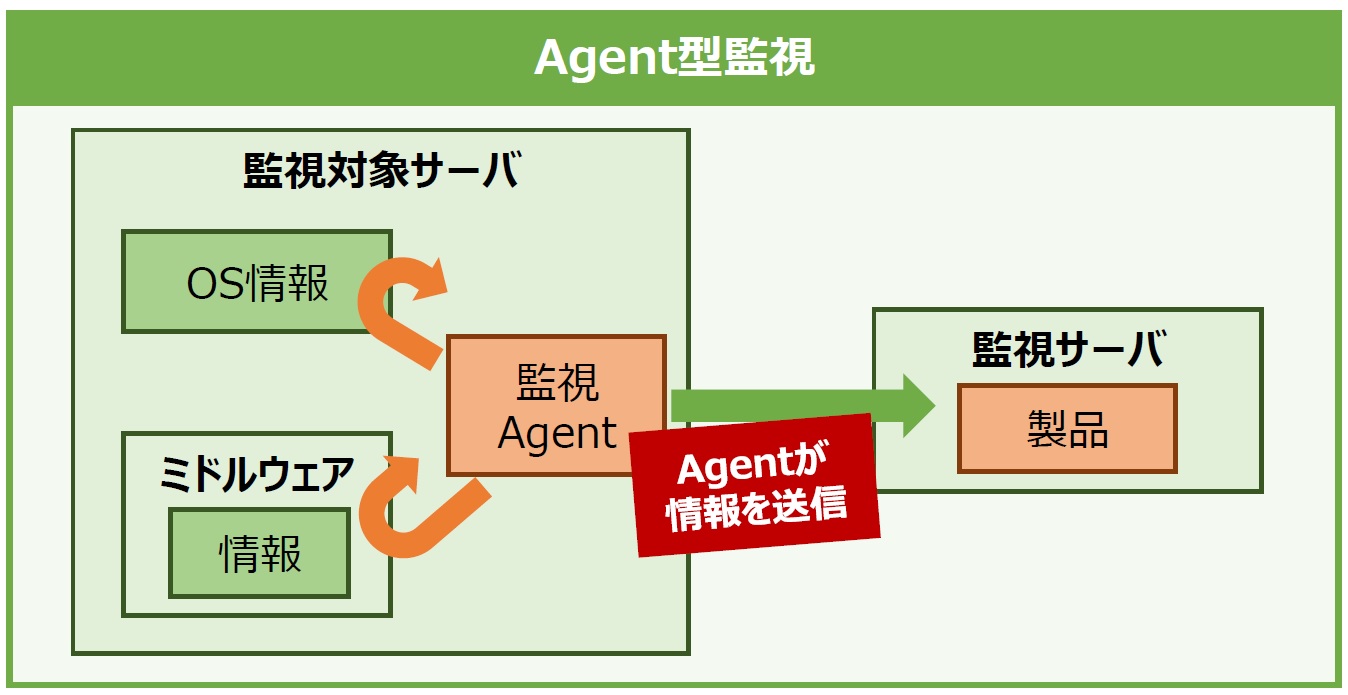
図4:Agent型監視ソフトウェアの監視方式イメージ
Prometeusはこの逆で、監視サーバが自ら監視対象サーバの情報を取得しに行くPull型監視方式を採用しています(図5)。例えるなら監視カメラによる監視と似たようなものです。

図5:Pull型監視ソフトの監視方式イメージ
それでは、Prometheusの仕組みはどのようになっているのでしょうか。Prometheusには、監視対象のサーバやコンテナに導入するexporterと、監視サーバに入れるPrometheusサーバがあります。
exporterは監視したい対象ごとに分かれて動作します。例えば、監視対象サーバのCPUのリソース情報を取得したい場合には、CPU用のexporterを入れることで監視できます。また、ApacheやTomcatなどのミドルウェアの情報も取得できるなど、監視対象の種類は多岐に渡ります。コンテナの場合もexporterを各コンテナに入れることで監視できます。
Prometheusサーバは監視対象から取得した情報の取りまとめをします。Prometheusサーバには、リソース情報をexporterから取得する役割を持つ「Retrieval」、取得したリソース情報を格納する「Storage」、リソース情報を可視化する「PromQL」の3つのコンポーネントがあります(図6)。
ただし、PromQLは単純なグラフしか出力されず非常に見づらくなっているため、「Grafana」や「Kibana」などサードパーティの可視化ツールを使用してPromQLの欠点を補います。
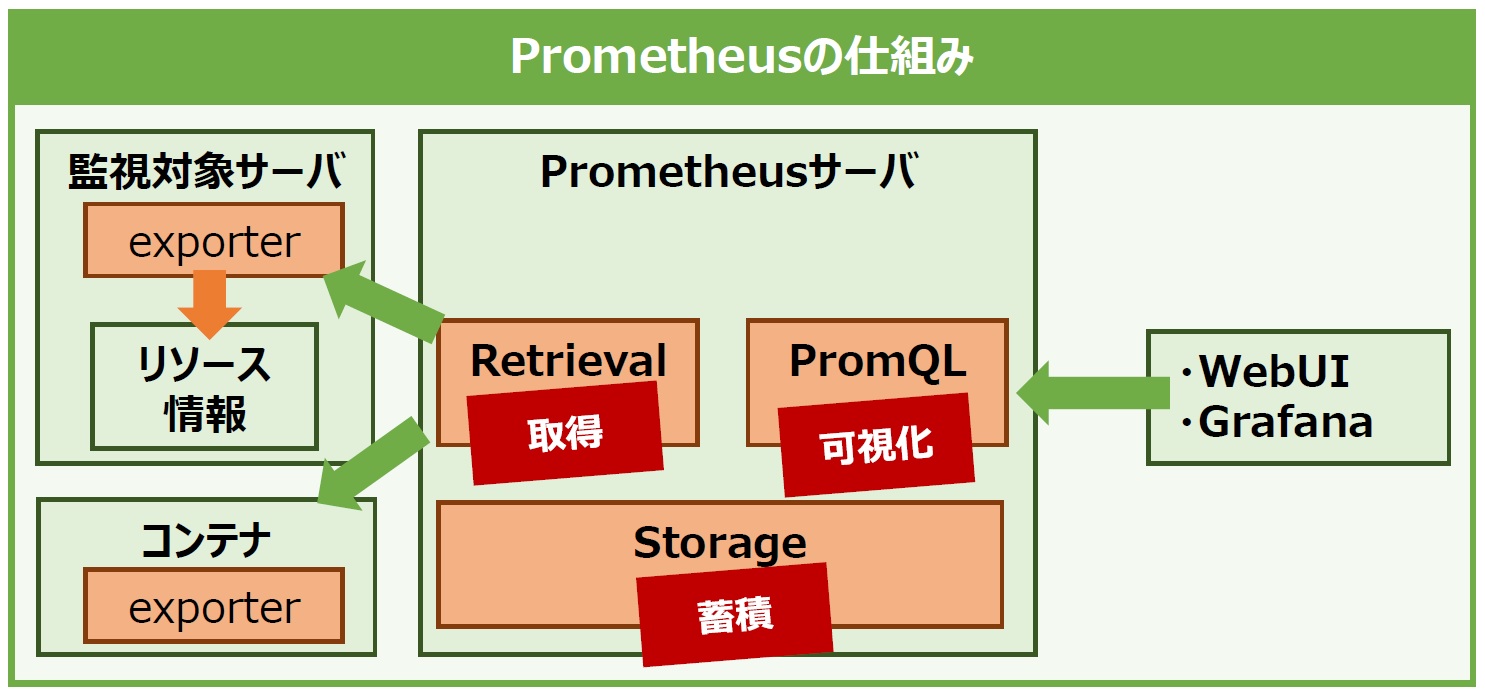
図6:Prometheusの仕組み
KubernetesでPrometheusを動かす場合も、exporterを使用するところは前述した通常のサーバと同じ考え方になります。ただし、各ノードのリソース情報なども取得したい場合には、クラスタにPrometheus本体をインストールする必要があります。
コンテナにPrometheusをインストールするには複数の方法があります。1つ目はサーバのようにコンテナに組み込んで起動させる方法です。しかし、この方法ではコンテナが再起動されるとインストールした情報が消えてしまいます。
そこで使われるのが、2つ目のPrometheus専用のpodをそのままデプロイし、クラスタ上で稼動させるという方法です。この方法であれば、1つ目の方法の欠点を補うことができます。
exporterも同様に、監視対象のKubernetesのクラスタに任意のexporter podを稼動させることでリソースを監視できます(図7)。
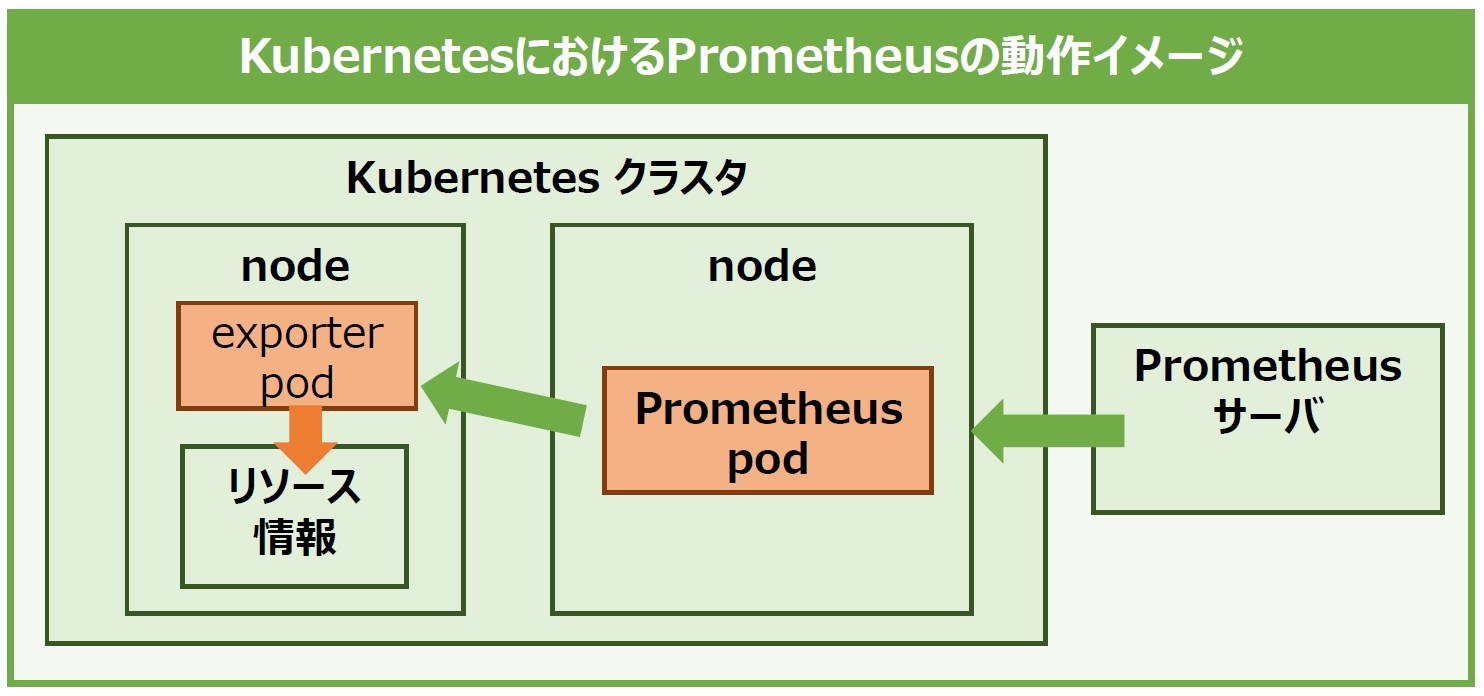
図7:KubernetesにおけるPrometheusの動作イメージ
現在では、Agent型監視ソフトウェアもコンテナなどの動的なサービスを監視できるように開発が進められています。一概に全てのPull型監視ソフトウェアがコンテナ監視に向いているとは言えませんが、Prometheusを使うことでより簡単にコンテナを監視できるのです。

Fluentd
コンテナを利用してアプリケーションを継続的に稼動させるには、運用の観点でいくつか考慮しないといけないところはありますが、その中でとりわけ重要なのは「ログデータの管理」です。
クラスタをより良く管理・運用するためには、コンテナのログデータを効率的に収集してデータストアに格納し、集中管理で問題を発見するために閲覧できる一連の仕組みが必要となります。このコンテナのログデータ収集で定番と言えるのが「Fluentd」です。
Dockerにはコンテナ内プロセスのログ情報(標準出力と標準エラー出力)をJSON形式でログファイルに保存する機能がありますが、予期せぬ障害でコンテナが落ちてしまった場合に、ログファイルも一緒に破棄されてしまうという欠点があります。また、Dockerホストを複数台で運用するような大規模なコンテナ環境では、それぞれのホスト上で個別にログファイルを管理することは困難なため、ログ情報を外部へ転送して集中管理する機構が必要となります。このような課題を解決するため、Dockerにはログの転送を補助する「Logging driver」機能を備えています。
Logging driverをFluentdに指定することで、構造化したログデータは一旦Fluentdに送信されます。また、Fluentdの出力プラグインを用いて収集したログデータを様々な形式に変換して保存することもでき、保存先には外部のストレージやAmazon S3、Google Cloud Storageといったパブリッククラウドのオブジェクトストレージも指定できます(図8)。
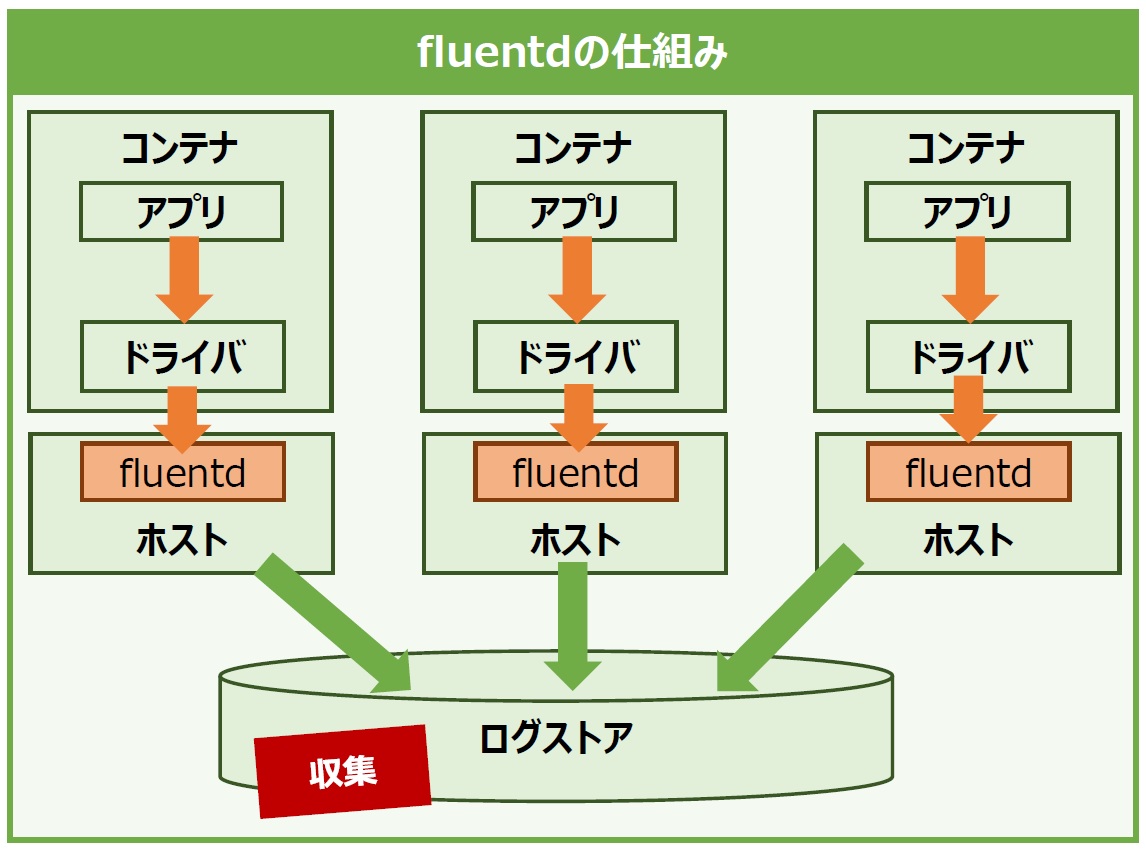
図8:fluentdの仕組み

おわりに
今回は、Kubernetes編の後編として、クラスタ上のリソースに対するアクセス制御システム(RBAC)と、クラスタ管理を効率化するツールを紹介しました。今回の解説で覚えておきたいのは、Kubernetesと連携するツールの利点を知ることで、Kubernetesクラスタをより効率的に管理できるようになることです。クラスタ管理を効率化することは、クラスタの規模が大きくなればなるほど、その重要性を増してきます。Kubernetes内の管理コンポーネントだけでなく、周辺ツールも上手に使いこなすことが大切なのです。
次回はKubernetesから離れ、効率的な開発手法の1つである「DevOps」と「CI/CDパイプライン」について解説します。次回もお楽しみに!

この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
