CloudNative Days Tokyo 2023から、クラウドネイティブなトラブルシューティングのノウハウを紹介
CloudNative Days Tokyo 2023から、メルペイのSRE Tech Leadによるクラウドネイティブ環境におけるトラブルシューティングの手法を解説したセッションを紹介する。
2024年4月26日 6:00
2023年12月11日、12日の両日にハイブリッド形式で開催されたCloudNative Days Tokyo 2023から、株式会社メルペイのSRE Tech LeadのJunichiro Takagi氏が発表したセッションを紹介する。

株式会社メルペイのJunichiro Takagi氏
タイトルは「CloudNative環境におけるトラブルシューティングガイド」。クラウドネイティブなWeb系システムの障害をどのように検知して対応するかについて、大規模クラウドネイティブサービスのSREとしての経験から得たノウハウが語られた。
オートスケーリングやオートヒーリングでも防げないトラブルもある
クラウドネイティブな環境では、オートスケーリングやオートヒーリングの機能などで、ある程度は負荷増大やインスタンスの障害に対応できる。
ただし、そうした環境でもトラブルは必ず起きる、というのが今回の話だ。

クラウドネイティブな環境でもトラブルは必ず起きる
クラウドネイティブな環境でも防げないトラブルとしては、まずクラウド自体の障害がある。Takagi氏によると、実際には何分かサービスが使えないようなことはあまりなく、「数秒や数マイクロ秒などの短い時間での停止がちょこちょこあるような感じ」だという。

クラウドの障害
次にオートスケーリングで救えないケース。よくあるパターンとして、予想以上に負荷が上がった結果、事前に設定したオートスケールの上限値に達するケースや、クラウドリソースの上限(Quota)に達するケースがあるという。
またKubernetesでPodはすぐにオートスケールできても、ノードなどのオートスケールに数分の時間がかかるといったケースもある。
そのほか、CPU使用率をもとにオートスケールを設定していても、先にメモリ使用率が増えてしまい、オートスケールできずに再起動を繰り返すケースもある。

オートスケーリングで救えないケース
Kubernetesなどでは、障害を検知して自動的に問題のあるPodを再起動するオートヒーリングもある。このオートヒーリングでも、再起動しても同じ問題が起きてしまうケースなど、救えないケースもたくさんあるそうだ。

オートヒーリングで救えないケース
準備としてSLOを定義し、モニタリングやログなどを整備する
こうしたトラブルへの対応の前に、まずはトラブルに遭遇する前の準備の話だ。
準備0番としてTakagi氏が挙げたのは、「自分が運用しているシステムの構成を理解する」ことだ。大きなシステムでは、細かく把握するというより、リクエストがどのように来てどのようなシステムを経由してレスポンスを返すか、までのざっくりとした流れを理解している必要があるという。

準備0:自分が運用しているシステムの構成を理解する
準備1は、「自分たちのシステムの正常な状態を定義する」ことだ。SLO(Service Level Objective)を設定して、どこまで対応するかを決めるものだ。
ここで高すぎる目標を設定すると、アラートが増えて運用の負担も増えてしまうほか、クラウドサービスのSLAより高くても達成できない。「高すぎる目標には気をつけたほうがいい」とTakagi氏は語った。
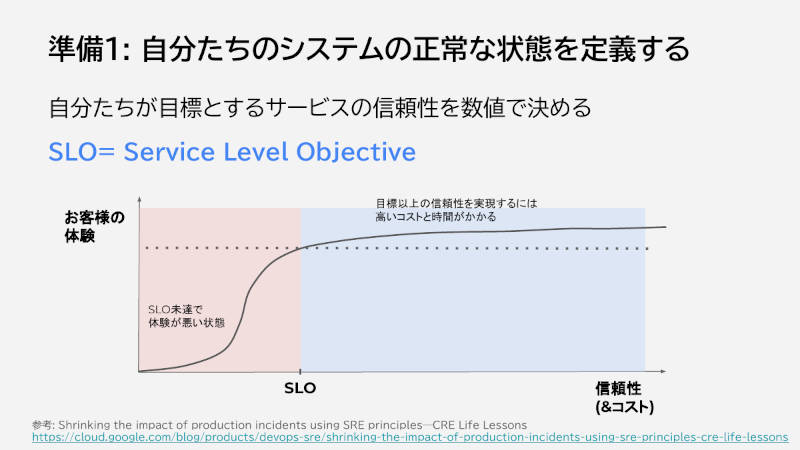
準備1:自分たちのシステムの正常な状態を定義する
準備2は、「トラブルを観測できるようにする」こと。設定したSLOを達成できているか、またSLOの構成要素となる各種メトリクスを取得し、必要に応じて通知できているかということだ。

準備2:トラブルを観測できるようにする
準備3は、「観測できるようになったトラブルを調査できるようにする」こと。サービスのエラー率が増えているといったトラブルが観測されたときに、メトリクスやログ、トレーシングから原因を深掘りできるデータを用意する。「個人的には特にログが大事だと思っている」とTakagi氏は付け加えた。

準備3:トラブルを調査できるようにする
把握:ほかの変化や境界の部分も確認する
こうした準備ができたうえで、次はトラブルシューティングだ。
トラブルシューティングは問題が発生したら、それを検知し、どのシステムで何が起こっているかを把握し、根本原因を調査して特定し、暫定的な対応をして、復旧を確認するという流れとなる。

トラブルシューティングの流れ
検知については準備のところで触れたので、まずは問題の把握から。ここで気をつけることは、焦らずに客観的な目で冷静に把握することだ。原因の特定を急いで、多分これが原因だろうと断定して調べたが実はそこは原因ではなかった、というパターンもよくあるという。
まず考えるのは、いつからどこで問題が発生し、具体的にどのような問題が起きているかを把握することだ。このときのポイントとして、リクエスト数の変化やオートスケールの状況など、ほかに変化がないかもあわせて見ることをTakagi氏は挙げた。
そのほか、ここまでは正常に動いているという境界の部分を確認することも、問題の切り分けのためのポイントとして挙げられた。
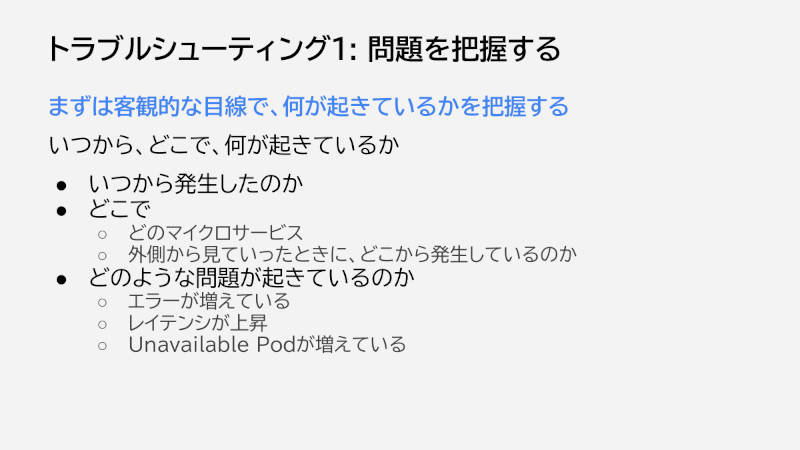
トラブルシューティング1:問題を把握する
この記事をシェアしてください
関連記事
CNDT2020シリーズ:メルペイのマイクロサービスの現状をSREが解説
2021年1月5日 8:16
【CNDW2025】クラウド時代の設計と検証を再構築し、Kubernetesでエンタープライズのインフラ設計とテスト手法を整理
1月21日 6:00
CloudNative Days Tokyo 2019:メルペイのマイクロサービス化の目的とは?
2019年10月3日 6:00
CloudNative Days Tokyo 2023から、クラウドネイティブセキュリティの脅威や論点を紹介
2024年2月19日 6:00
テレメトリーシグナルの相関に基づくデバッグにより、オブザーバビリティの真価を発揮
2024年8月13日 6:00
CNDT 2022、ChatworkのSREがSLO策定にカオスエンジニアリングを使った経験を解説
2023年5月29日 12:37
バックナンバー
この記事の筆者

筆者の人気記事
使って分かった国産クラウド「K5」のメリットとは
2018年1月31日 6:30
初めてでも安心! OCIチュートリアルを活用して、MySQLのマネージド・データベース・サービスを体験してみよう
2021年4月21日 12:39
Dockerを理解するための8つの軸
2015年7月29日 22:00
Dockerの誤解と神話。識者が語るDockerの使いどころとは? Docker座談会(前編)
2016年2月22日 0:00
【イベントリポート:Red Hat Summit: Connect | Japan 2022】クラウドネイティブ開発の進展を追い風に存在感を増すRed Hatの「オープンハイブリッドクラウド」とは
2022年11月10日 8:45
Kubernetes、PaaS、Serverlessのどれを選ぶのか? 機能比較と使い分けのポイント
2018年5月23日 6:30
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
