PostgreSQLとは
PostgreSQLはオープンソースソフトウェア(OSS)のデータベース管理システム(DBMS)です。高機能・高性能なエンジンを持ち有用な関数を多く実装するほか、様々な開発言語にも対応するため、技術者にとって扱いやすいDBMSでもあります。機能面でも性能面でも商用DBMSに見劣りしない「OSS DBMSの代表格の1つ」という位置付けです。
またPostgreSQLを利用する上で留意すべきOSSのライセンスは、BSDライセンス(Berkeley Software Distribution License)をベースとした独自の「PostgreSQLライセンス」という形態をとっています。このライセンスは商用・非商用を問わず無償で利用でき、著作権表記とライセンス全文を含めれば改変および再配布は自由となっています。さらにソースコードの公開義務もなく、商用製品への組み込みも容易です。
OSSの台頭により、近年急速に注目を集めているPostgreSQLですが、その歴史は古くRDBMSの草分け的な存在である「Ingres」の後継として1980年代にプロジェクトが開始されました。以後、PostgreSQLは精力的なコミュニティによって、毎年メジャーバージョンアップが行われています(図1)。
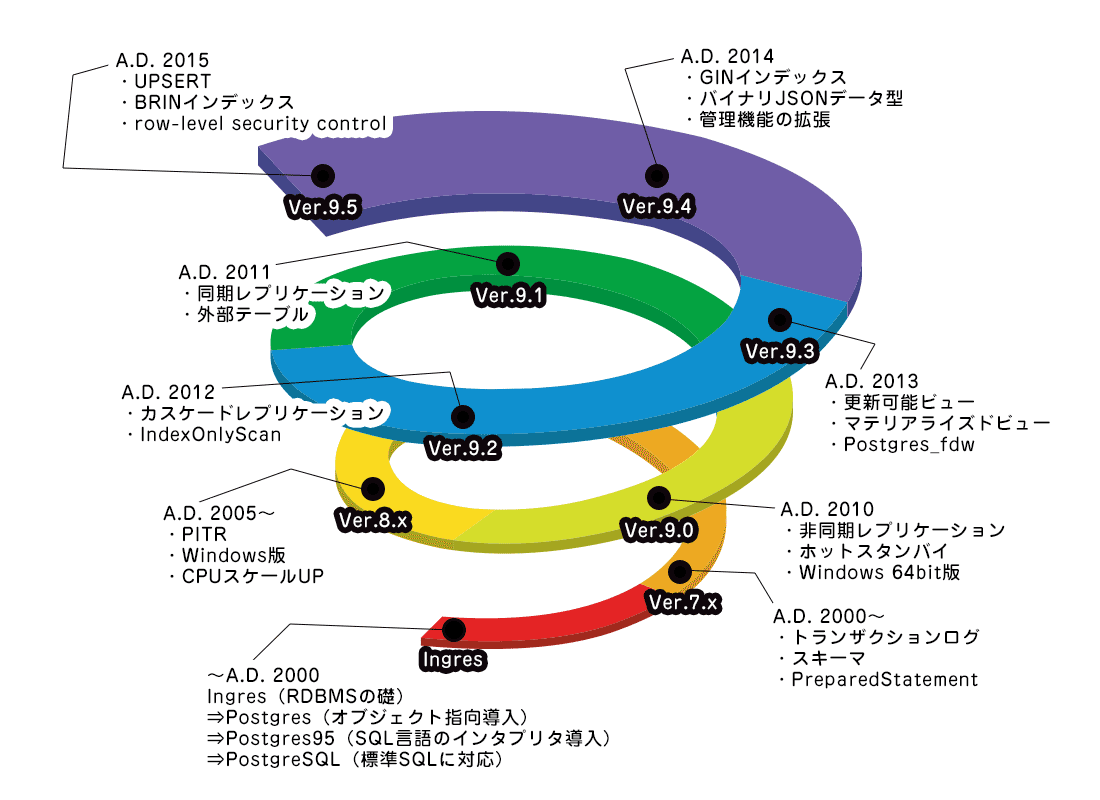
直近では、2016年1月に待望の新バージョン、PostgreSQL 9.5(以下、9.5)がリリースされました。ここでは、9.5で実装された主な新機能を簡単に紹介します。
9.5の新機能
9.5では、UPSERTの実装やGROUP BY機能の強化などの利便性向上、昨今のセキュリティ事情に対応するための機能強化、大規模データベースを見据えたパフォーマンスの改善などを中心に160ほどの機能追加と変更が行われています。
UPSERT(ON CONFLICT句)の実装
INSERT文にON CONFLICT句が追加されました。これにより、今までキー値の重複等でエラーとなっていた挿入処理を更新処理へと自動的に代替して実行できるようになりました。言い換えれば、データがまだ存在しない場合は挿入、データがすでに存在する場合は更新といった切り替えを自動で実施してくれる機能です。
これまで、この仕組みを実装するにはアプリケーション側などで複雑な処理の記述が必要でしたが、この機能によりデータベース管理者は容易にこの仕組みを実現できます。
なお、これは一般的にUPSERTとして知られている機能と同様のものです。
GROUPING SETS句、CUBE句、ROLLUP句の実装
GROUP BY句の拡張機能として、SQL標準(SQL99)のGROUPING SETS句、CUBE句、ROLLUP句の機能が追加されました。これにより、これまでは複数のSQL文を用いて求めなければならなかった小計値等を単独のクエリで算出できます。
JSONBの機能強化
JSONBデータ型の特定のメンバ(キーと値の組み合わせ)に対する更新処理が可能となりました。
JSONBデータ型は9.4で導入されたJSONデータ(JavaScript Object Notation:テキストベースのフォーマット)をバイナリ形式で格納するためのデータ型です。9.4では特定のメンバのみを更新することはできず、UPDATE文を用いる場合は変更不要な個所も含めてJSONデータ全体を更新するしかありませんでした。また、このような機能をユーザ定義関数で実現するためには複雑なプログラムを記述する必要がありました。
9.5で追加されたjsonb_set()を用いると特定のメンバに対するUPDATEが可能となり、容易に更新処理を行えます。
【9.4まで】行全体の更新(赤字が実際の更新箇所)
'{"id":100, "dept":"sales", massage:"hello world! hello world! hello world!"}'
【9.5から】特定のメンバだけの更新(赤字が実際の更新箇所)
'{"id":100, "dept":"sales", massage:"hello world! hello world! hello world!"}'
Foreign Data Wrapper(FDW)の機能強化
SQLを利用して外部データ(PostgreSQLの外側に存在する様々なデータ)へアクセスするためのFDWにIMPORT FOREIGN SCHEMA文が追加されました。これを利用すると、外部テーブルを作成する際に外部サーバからテーブル定義をインポートできます。対象の外部サーバのテーブル定義をすべて調査してローカルテーブルに再定義するという煩わしい作業を省き、簡単に実行できるようになります。
また、ローカルテーブルと外部テーブルで継承が定義できるようになりました。例えば、ローカルテーブルを親、外部テーブルを子とした場合、ローカルテーブルの参照結果に外部テーブルのデータが含まれるようになります。これにより、データを複数のテーブルに分割するパーティショニング機能を、外部テーブルを含めた構成で実現できます。
Block Range Indexes(BRIN)の実装
巨大なテーブル内の検索に効果を発揮するBRINインデックス(公式ドキュメントではBRIN Indexesと表記)が追加されました。BRINインデックスには物理的に隣接するブロック(ページ)の集合を1グループとして、各グループの値の範囲が登録されます。これにより、検索時に実際にスキャンする範囲を絞り込むことができます。なお、このインデックスは物理データが整列されている(更新処理が発生しない)テーブルほど効果が高くなります。
wal_compressionパラメータの追加
パラメータにwal_compressionが追加されました。通常、更新処理が発生すると変更された行のみがWAL(トランザクションログ)に書き出されます。このときfull_page_writesパラメータが有効(デフォルト)になっていると、チェックポイント後に変更されたページはそれぞれ初回の書き出しにおいてのみ、ページのすべての内容(フルページ・イメージ)をWALに書き出します。wal_compressionを有効にすると、このときに書き出されるフルページ・イメージが圧縮され、WAL量を低減できます。
row-level security controlの実装
ユーザがアクセスできるデータの範囲を行ごとに設定可能となりました。これまではテーブルやカラムを対象としたアクセス権の設定しかなく、行レベルのアクセス権と同等の機能を実現するためにはアプリケーション等で制御する必要がありました。9.5からはテーブル定義にセキュリティポリシィを記述することで容易に実現できます。また、この機能は特定のコマンド(SELECT、INSERT、UPDATE、DELETE)に対してのみアクセス権を付与することもできます。
pg_rewindの実装
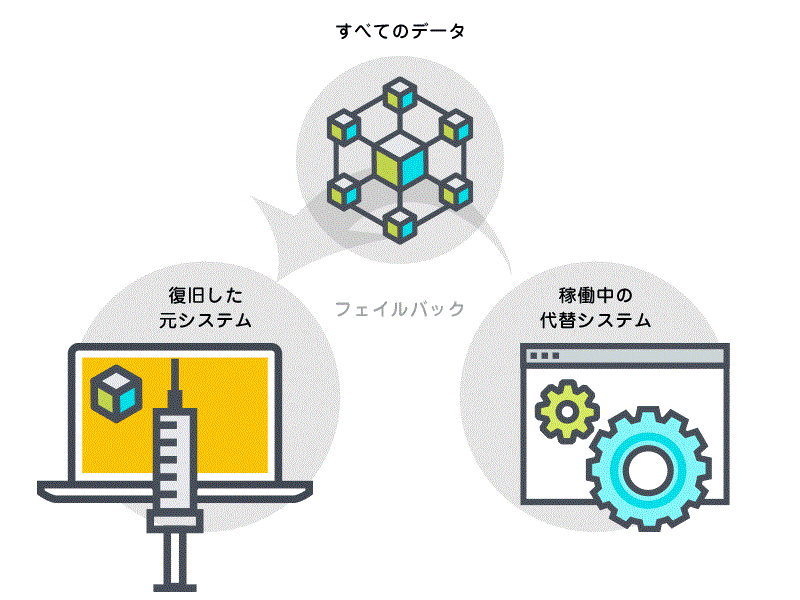
これまでフェイルバック(代替システムから復旧が完了した元システムへ処理を移行する作業)時には元システムに代替システムからのフルベースバックアップ(差分ではなく全データ)が必要となり(図2)、データの転送等でフェイルバックに長時間を要していました。
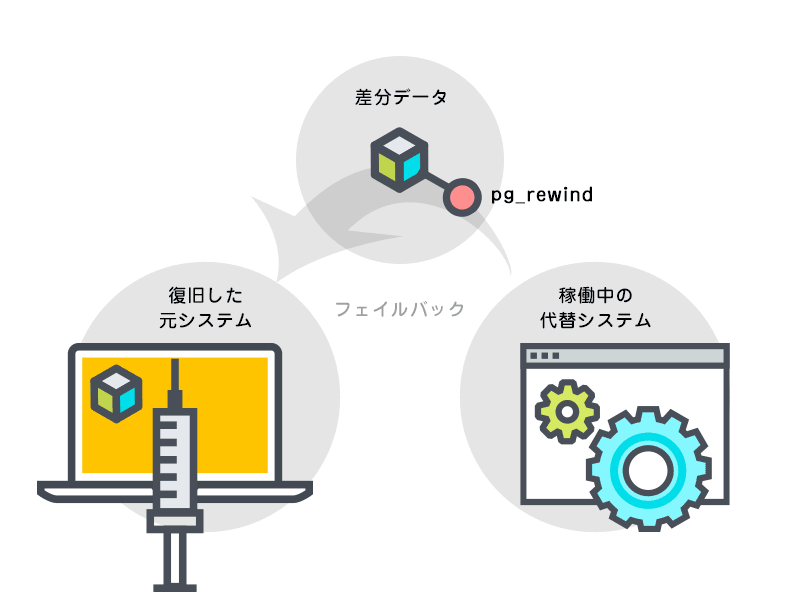
しかし、フェイルバック時にpg_rewindを利用すると元システムのデータに代替システムとの差分(元システムが停止している間に進んだ内容)を適用するだけでフェイルバックが実現できるようになります(図3)。これにより、フェイルバックの高速化が期待されます。
ここまで9.5の新機能について紹介しましたが、次回からは各機能を詳細に解説していきます。なお、次回からの解説には実機によるオペレーションが伴うため、以降ではオペレーションの実行環境と最新版9.5の導入手順も紹介します。
オペレーションの実行環境と9.5の導入
オペレーションの実行環境は表の通りです。本連載では、表のプラットフォームに対応する9.5の導入手順を説明します。
| 種別 | プロダクト名 |
|---|---|
| OS | CentOS release 6.7(x86_64) |
| DBMS | PostgreSQL 9.5.1 |
なお、今回はデータベースサーバが外部ネットワークに接続されていない環境を想定して、あらかじめダウンロードしたrpmパッケージを利用した導入を行います。
(1)公式マニュアルに記載の必要条件を満たす
【公式マニュアル:英語】
http://www.postgresql.org/docs/9.5/static/install-requirements.html
【JPUGマニュアル:日本語】
http://www.postgresql.jp/document/9.5/html/install-requirements.html
※JPUG(日本PostgreSQLユーザ会)は、PostgreSQLの普及促進を目的とした特定非営利活動(NPO)法人です。
(2)公式サイトから対応するOSに必要なパッケージをダウンロードし、導入するDBサーバの任意の場所に配置
【公式サイト】
http://yum.postgresql.org/9.5/
(本環境ではhttp://yum.postgresql.org/9.5/redhat/rhel-6.7-x86_64/)
【必要なパッケージ】
- postgresql95-libs-9.5.1-1PGDG.rhel6.x86_64.rpm (共有ライブラリ)
- postgresql95-9.5.1-1PGDG.rhel6.x86_64.rpm (クライアントプログラム)
- postgresql95-server-9.5.1-1PGDG.rhel6.x86_64.rpm (サーバプログラム)
- postgresql95-contrib-9.5.1-1PGDG.rhel6.x86_64.rpm (拡張モジュール)
(3)DBサーバにログインしroot権限でrpmパッケージを導入
# rpm -ivh postgresql95-libs-9.5.1-1PGDG.rhel6.x86_64.rpm \
postgresql95-9.5.1-1PGDG.rhel6.x86_64.rpm \
postgresql95-server-9.5.1-1PGDG.rhel6.x86_64.rpm \
postgresql95-contrib-9.5.1-1PGDG.rhel6.x86_64.rpm
(4)環境変数の追加
rpmパッケージを導入するとOSのpostgresユーザが自動生成されます。今回はこのpostgresユーザでオペレーションを行うため、作成されたpostgresユーザに変更し、以下の環境変数を.bash_profile等に追加してください。
PATH=/usr/pgsql-9.5/bin:$PATH
export PATH
PGDATA=/var/lib/pgsql/data
export PGDATA
※PGDATAはデータベース・クラスタ(データベースの格納領域)の配置先
(5)データベース・クラスタを作成
-D:データベース・クラスタの配置ディレクトリ
-E:エンコーディング
-U:スーパーユーザ名
--no-locale:ロケールの設定、-locale=Cと同義
$ initdb -D ${PGDATA} -E UTF-8 -U postgres --no-locale
The files belonging to this database system will be owned by user "postgres".
This user must also own the server process.
~省略~
$
(6)データベース・インスタンスを起動
-D:データベース・クラスタの配置ディレクトリ
-w:起動または停止処理の完了待ち
$ pg_ctl start -D ${PGDATA}
server starting
$
停止するには、下記のコマンドを実行します。
pg_ctl stop -D ${PGDATA}
なお、Red Hat系のOS(CentOSやFedoraなど)では、データベース・クラスタの作成や起動、停止はserviceコマンドを用いて実行することも可能です。
(7)起動したデータベースに接続できることを確認
$ psql
psql (9.5.1)
Type "help" for help.
postgres=#
以上で、PostgreSQLを使用する準備が整いました。
次回は、今回紹介した9.5の新機能の中から、UPSERT(ON CONFLICT句)とGROUP BY句の拡張機能(GROUPING SETS句、CUBE句、ROLLUP句)について、実際に動かしながら詳しく解説します。
- この記事のキーワード
この記事をシェアしてください
関連記事
UPSERT(ON CONFLICT句)とGROUPING SETS句/CUBE句/ROLLUP句の実装
2016年4月26日 0:00
Block Range Indexes(BRIN)の実装とwal_compressionパラメータの追加
2016年5月19日 0:18
row-level security controlとpg_rewindの実装
2016年6月7日 0:00
Foreign Data Wrapper(FDW)の機能強化
2016年7月7日 0:00
PostgreSQL 9.6をエンタープライズで使う性能や方法を検証 〜PGECons活動成果発表会開催
2017年6月13日 10:11
障害や誤操作からデータを守る「MySQL」と「PostgreSQL」の「バックアップ・リカバリ」を理解する
6月23日 6:30
バックナンバー
この記事の筆者
筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
