UPSERT(ON CONFLICT句)とGROUPING SETS句/CUBE句/ROLLUP句の実装
2016年4月26日 0:00
今回は、PostgreSQL 9.5(以下、9.5)で実装された以下2つの機能について、実際に動かしながら紹介します。
- UPSERT(ON CONFLICT句)の実装
- GROUPING SETS句/CUBE句/ROLLUP句の実装
UPSERT(ON CONFLICT句)の実装
9.5ではINSERT文にON CONFLICT句が追加されました。これは一般的に「UPSERT」として知られている機能です。この句を利用すると、キー値の重複等でエラーとなっていた挿入処理を自動的に他の処理に代替して実行させることができます。
このON CONFLICT句には2つの動作を指定できます。1つはDO NOTHING句です。ON CONFLICT句にDO NOTHING句を指定すると、テーブルに挿入したい行がまだ存在しない(制約に違反する行が存在しない)場合は通常の挿入処理となります。一方、テーブルに挿入したい行がすでに存在する(制約に違反する行がすでに存在する)場合はエラーとして終了するのではなく、対象行へ何の処理も行わずにそのまま完了します。
もう1つはDO UPDATE句です。ON CONFLICT句にDO UPDATE句を指定すると、テーブルに挿入したい行がまだ存在しない(制約に違反する行が存在しない)場合はDO NOTHING句と同様に通常の挿入処理となります。ただし、テーブルに挿入したい行がすでに存在する(制約に違反する行がすでに存在する)場合は対象行への挿入処理が更新処理として実行されるようになります。
以下のデータがロードされているempテーブルを用いて、それぞれの振る舞いを確認してみましょう。なおempテーブルはid列がプライマリキーとなっており、ユニークな値のみが挿入可能な一意制約が定義されています。
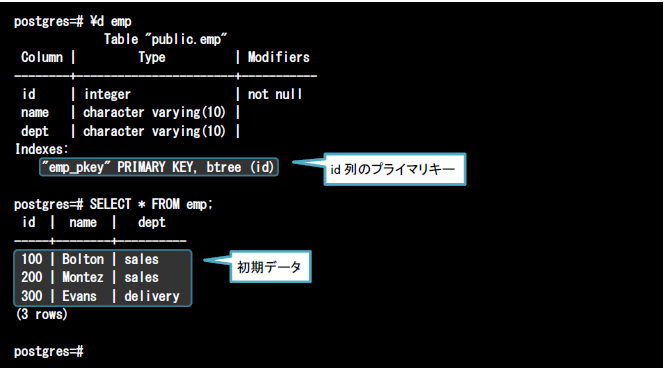
(1)これまでの動作
次のようなINSERT文を実行すると、これまではid=200の列が一意制約違反となり、エラーとなって終了していました。

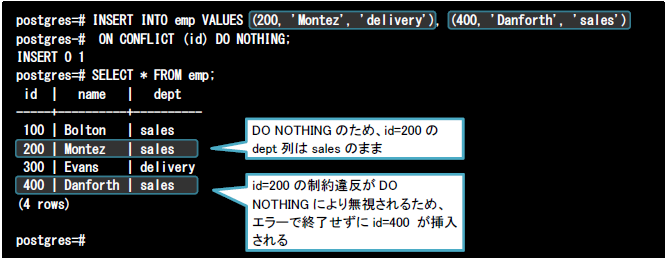
(2)代替処理(DO NOTHING句)
以下はDO NOTHING句を利用した例です。id=200の列は既にテーブルに存在するため、対象行への処理は何も行われずに(エラーとならずに)完了します。一方、id=400の列はテーブルに存在しないため、通常の挿入処理が実行されます。
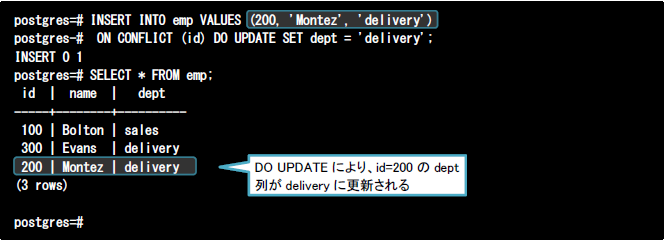
(3)代替処理(DO UPDATE句)
以下はDO UPDATE句を利用した例です。id=200の列は既に存在するため、対象行への挿入処理が更新処理として実行されます。また、例では示していませんがDO NOTHING句と同様にテーブルに存在しない行の場合は通常の挿入処理が実行されます。
(4)代替処理(DO UPDATE句)のEXCLUDED句
DO UPDATE句でVALUES句に2つ以上の値を指定している際は注意が必要です。以下の例では、VALUES句に2つの値を指定しており、id=200のdept列にcollectorを挿入しようとしています。しかし、DO UPDATE文のSET句で指定されているのがdeliveryであるため、すべての更新行のdept列がdeliveryの値に変更されてしまいます。

そこで、このような場合はEXCLUDED句を利用します。EXCLUDED句を用いるとVALUES句で指定した値をSET句で参照できるようになり、行ごとに更新したい値を変更できるようになります。

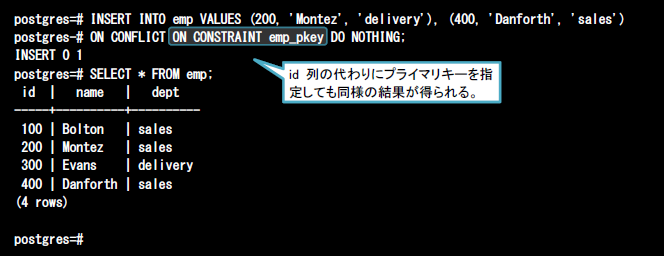
(5)インデックスを利用した指定方法
ON CONFLICT句では、対象カラム名ではなく制約の対象となるインデックスを直接指定することも可能です。下記の例は(2)代替処理(DO NOTHING句)と同一の処理内容となります。
このON CONFLICT句の機能によって、データがまだ存在しない場合は挿入、データがすでに存在する場合は更新といった差分更新をデータベース管理者でも容易に実現できるようになります。これまでは、この仕組みを実現させるためにアプリケーション側などで複雑な処理を設計する必要がありました。
なお、この機能は、Oracleデータベースの「MERGE」処理やMySQLの「REPLACE」処理、「INSERT ON DUPLICATE KEY UPDATE」処理といった機能とほぼ同義の機能となります。
GROUPING SETS句/CUBE句/ROLLUP句の実装
GROUP BY句の拡張機能として、SQL標準(SQL99)のGROUPING SETS句/CUBE句/ROLLUP句の機能が追加されました。これまで、グループ化した値の小計や合計を求めるには複数のクエリを実行して中間クエリの値を保持しておく必要があるなど、DBMSにとってもユーザにとってもコストの高い処理となっていました。今回追加された機能を利用すると、単独のクエリでこれらの値を容易に導出できるようになります。
以下のデータがロードされているempテーブルを用いて、それぞれの振る舞いを確認してみましょう。

ROLLUP句
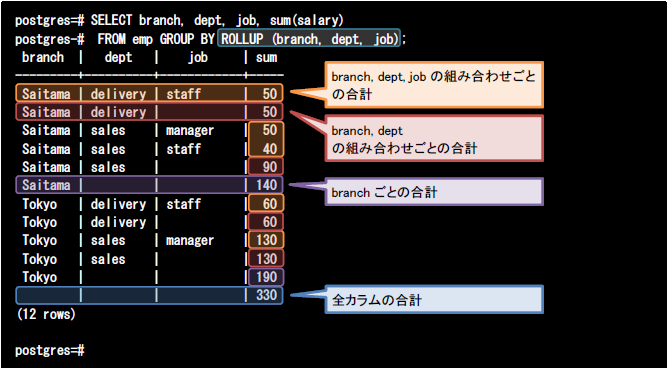
ROLLUP句では指定したカラム順に小計値を求めることができます。以下のクエリでは、ROLLUP句にbranch, dept, job列の順に指定しています。
このクエリを実行すると、まずbranch, dept, job列の組み合わせごとのsalary列の合計(橙色の値)が導出されます。次にbranch, dept列の組み合わせごとのsalary列の合計(赤色の値)、branch列のごとのsalary列の合計(紫色の値)の順に値が導出され、最後に全カラムのsalary列の合計(青色の値)が導出されます。
CUBE句
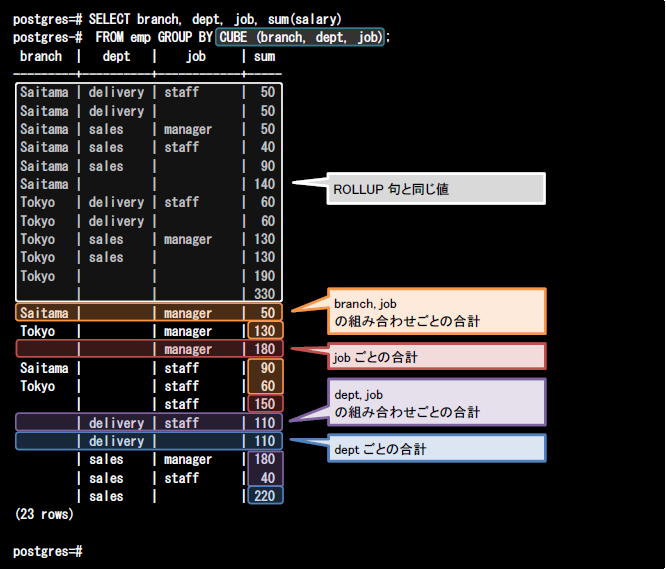
CUBE句では指定したカラムのすべての組み合わせで小計を求めることができます。以下のクエリでは、CUBE句にbranch, dept, job列の順に指定しています。このクエリを実行すると、最初にROLLUP句で指定した組み合わせと同じ値が導出されます。
次に、ROLLUP句では実行されていなかった組合せの合計値が導出されます。1つはbranch, job列の組み合わせごとのsalary列の合計(橙色の値)とjob列ごとのsalary列の合計(赤色の値)、もう1つはdept, job列の組み合わせごとのsalary列の合計(紫色の値)とdept列ごとのsalary列の合計(青色の値)です。
GROUPING SETS句
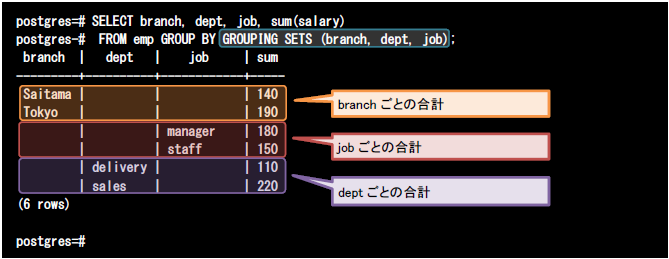
GROUPING SETS句では、指定したカラムの小計のサマリのみを求めることができます。以下のクエリでは、GROUPING SETS句にbranch, dept, job列の順に指定しています。
このクエリを実行すると、branchごとのsalary列の合計(橙色の値)、jobごとのsalary列の合計(赤色の値)、deptごとのsalary列の合計(紫色の値)を導出できます。
今回は、PostgreSQL以外のDBMS経験者から待ち望まれていたUPSERT(ON CONFLICT句)とGROUP BY句の拡張機能(GROUPING SETS句、CUBE句、ROLLUP句)について紹介しました。
皆さんの環境でも動作を確認できたでしょうか。なお、今回のサンプルSQLはこちらからダウンロードできます。
次回は、処理性能に関連するBlock Range Indexes(BRIN)とwal_compressionパラメータについて詳しく解説します。
- この記事のキーワード
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者
筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
