いよいよ本連載も最終回となります。今回は、PostgreSQL 9.5(以下、9.5)で機能強化されたForeign Data Wrapper(FDW)について、実際に動かしながら紹介します。
Foreign Data Wrapper(FDW)の機能強化
PostgreSQLには標準SQLで定義されているSQL/MEDの実装系として、Foreign Data Wrapper(FDW)という外部データへアクセスするための仕組みが用意されています。この仕組みにより、PostgreSQLからSQLで他のデータベースにアクセスすることが可能になります。
9.5にはOS上のファイルに直接アクセスする「file_fdw」と、外部のPostgreSQLのテーブルにアクセスする「postgresql_fdw」の2つのFDWが標準のcontribモジュールとして提供されています。この他にも、非公式ですがOracleやMySQL、MongoDB、TwitterなどさまざまなFDWが登場しており、それら外部ソースのデータをPostgreSQLのテーブルとしてアクセスできるようになります。
9.5では、このFDWについて2つの重要な機能強化が行われました。
IMPORT FOREIGN SCHEMAコマンド
機能強化の1つ目は「IMPORT FOREIGN SCHEMAコマンドの追加」です。FDWを使って外部データにアクセスするためには、通常はCREATE FOREIGN TABLEコマンドでPostgreSQL上にForeign Table(外部テーブル)を作る必要があります。
以下は、リモートサーバ上のemp表をローカル上に外部テーブルとして定義する例です。

SERVERで指定している'svr_remote'は、CREATE SERVERコマンドで定義したFDW用の外部サーバです。
この例を見てもわかるように、外部テーブルの作成ではリモート側のemp表をローカル側で再定義することになります。この作業は思いのほか面倒で、作業中にカラムの属性を間違えてしまうことが多々あります。
また外部テーブルの定義時にはリモート側のテーブル属性がチェックされないため、間違いに気付くタイミングは実際にこの外部テーブルへアクセスする時点になります。9.5ではIMPORT FOREIGN SCHEMAコマンドが導入され、この状況が改善されました。
それでは、IMPORT FOREIGN SCHEMAの構文から見てみましょう。

IMPORT FOREIGN SCHEMAは、スキーマ単位でリモートにあるテーブルの外部テーブルを一括でローカルのスキーマに作成します。この時に必要な外部テーブルのカラム情報はリモートのテーブルから持ってきます。
例えば、リモートサーバのスキーマ'sc_corp'にある全てのテーブルの外部テーブルを作成する場合は次のように記述します。

また、便利なオプションとして「LIMIT TO」と「EXCEPT」があります。LIMIT TOは指定スキーマに属するテーブルを個別に指定する場合に使います。EXCEPTは指定スキーマに属するテーブルのうち除外したいテーブルを指定します。
FDWを使うまでの手順について
ここで、簡単にリモートサーバ上のテーブルに外部テーブルからアクセスする手順をおさらいしておきましょう。基本的には次の3段階で行います。
(1)外部サーバの作成
CREATE SERVERコマンドでアクセス対象のソースを持つ外部サーバを定義します。オプションを使って外部サーバのホスト名、接続ポート、データベース名を指定します。

(2)外部サーバのユーザマップの作成
CREATE USER MAPPINGコマンドでローカルユーザと外部サーバ上のユーザを紐づけます。オプションでリモートユーザのユーザ名やパスワードを指定します。

(3)外部テーブルの作成
CREATE FOREIGN TABLEコマンドで外部サーバ上のリモートテーブルに対応する外部テーブルを作成します。今回のFDW強化でIMPORT FOREIGN SCHEMAコマンドが実装されたことにより、この段階の作業が大変便利になりました!
PostgreSQLのコンサルティングや方式設計業務を行っていて感じることですが、実システムでは思いのほかスキーマを意識しないでデータベースを構築していることが多いです。これにはいくつかの要因があると考えていますが、1つはPostgreSQLで構築するデータベースは比較的小規模のものが多いため、スキーマを意識する必要がないといったことがあります。またPostgreSQLを使う以前はOracleを使っていたというエンジニアも多く、Oracleではユーザとスキーマが同じ概念であるため、スキーマを意識することが少なかったといったこともあるようです。
このようにスキーマを意識しないままPostgreSQLを利用している場合は、スキーマ名を「public」とすることで外部テーブルのIMPORTが可能です。PostgreSQLの場合は、スキーマ名を指定しないでテーブルを作成するとpublicというデフォルトのスキーマに属することになるからです。
外部テーブルの継承サポート
FDW機能強化の2つ目は「外部テーブルにおける継承のサポート」です。PostgreSQLのテーブル継承はDBMSとしてはかなり尖った特徴的な機能と言えると思いますが、外部テーブルにもついにその機能が備わったことになります。
PostgreSQLの継承機能は、データベースを利用するシステムの特性に応じてさまざまな使われ方をしています。「継承(INHERITANSE)」という呼び方からオブジェクト指向型プログラム言語におけるクラスの継承のように使うことを想像してしまいますが、実務案件ではパーティショニングを実現するために使うことが多いように思います(事実、筆者が扱った案件で継承を使った全てのケースがパーティションテーブル実現でした)。
9.5からは外部テーブルの継承が使えるようになったことで、パーティションテーブルの子テーブルを外部サーバに配置することが可能になり、特に大規模データを扱う上で利便性が高まりました。
今回はある会社の本社と営業所に所属する社員を管理するテーブルの簡易モデルを使って、外部テーブルの継承機能を確認してみます。下図は本社にあるデータベース(本社DB)と営業所にあるデータベース(営業所DB)の構成を表したものです。

このとき、データベースオブジェクトは下表の通りです。
| データベース | オブジェクト | 説明 |
|---|---|---|
| 本社DB | all_emp | 全社員を参照するパーティション親テーブル |
| hp_emp | 本社社員のデータを持つテーブル(emp_no: 11~) | |
| eigyo_emp | 営業所DBのテーブルを参照する外部テーブル | |
| 営業所DB | eigyo_emp | 営業所社員のデータを持つテーブル(emp_no: 101~) |
※各テーブルはカラムとしてemp_noとemp_nameを持つ
それでは、簡易モデルの通りにオブジェクトを作成します。まずリモートサーバ上にある営業所DBに営業所社員テーブルを作成し、社員データを登録します。

次に、ローカルサーバ上の本社DBに全ての社員テーブルの親となるテーブルを作成します。
続いて、本社社員テーブル(hq_emp)を作成して社員データを登録します。このとき、INHERITS句で親テーブルを指定します。

さらに、本社DB上に営業所社員テーブルを外部テーブルとして作成します。このときもINHERITS句で親テーブルを指定します。この部分が9.5の新機能です。注意点は、親テーブルの構成がリモートのテーブル構成と同じであることです。
以上で、簡易モデルの実装は終了です。さっそく、動作を確認してみましょう。
まず、親テーブルの定義をpsqlの’\d+’コマンドで確認してみます。

子テーブルとして、eigyo_empとhq_empに継承していることがわかります。
次に、全社員テーブルを検索してみましょう。外部テーブルがうまく継承されていれば、本社と営業所の社員が検索できるはずです。
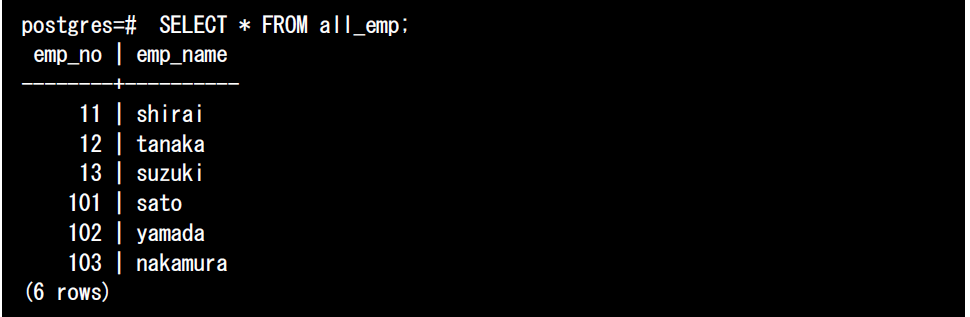
本社(emp_noが10番台)と営業所(emp_noが100番台)両方の社員データが検索できました。続いて、EXPLAIN VERBOSEコマンドを使って実行計画も確認してみます。

外部テーブルを親とする場合
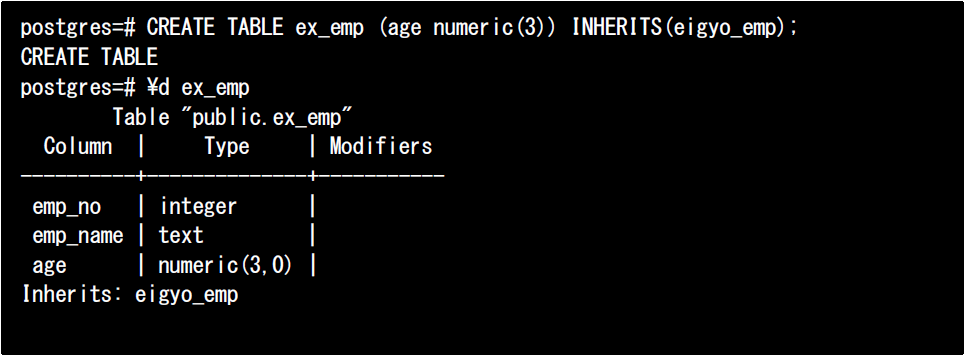
外部テーブルの継承は、外部テーブルを親としてローカルのテーブルを作成することも可能です。その場合は通常のテーブルを作るのと同じ要領で子テーブルを作成し、INHERITS句で外部テーブルを指定します。
以下は、本社DB上にある外部テーブルeigyo_empから継承したテーブルを作成し、その定義を表示した例です。
シャーディングとしての利用について
「シャーディング(sharding)」とは、データを複数のサーバに水平分散させる機能です。シャーディングを行うことでCPUやI/Oの負荷が分散され、結果的にスループットの向上が期待できます。
9.5から外部テーブルの継承がサポートされたことで、パーティションテーブルによるシャーディングが可能となりました。先述の本社DBと営業所DBのモデルもシャーディングの実装といえます。
では、期待するスループット向上は得られるのでしょうか? 筆者の手元にある環境で試してみましたが、残念ながら期待した結果は確認できませんでした。おそらくFDWの機構およびデータ通信のオーバーヘッドが大きく、水平分散によるメリットを活かせなかったものと思われます。しかしデータの規模や検索条件によっては性能向上が十分期待できると思います。
今回のサンプルSQLはこちらからダウンロードできます。ぜひ、皆さんもお手元の環境で動作確認を実行してみてください。
おわりに
本連載も今回で終了となります。この連載が多くの方に役立ち、また1人でも多くの方がPostgreSQLに興味を持っていただけるようになれば幸いです。
長期間にわたりご愛読いただき、ありがとうございました!
- この記事のキーワード
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
