「GPU」×「PG-Storm」で爆速PostgreSQLを体験してみよう
連載第5回となる今回は、実際に「PG-Strom」を動かしながら、皆さんにその性能を体験いただくための手順と操作方法を解説します。
2024年6月21日 6:30
はじめに
本連載では、これまでPG-Stromの概要、高速化の原理、ベンチマーク手法やベンチマーク結果などを紹介してきました。大規模での利用になると、NVIDIAのエンタープライズ向けのGPUやNVIDIAのGPUDirect対応の高速なストレージが必要になってきますが、ここまでの連載を通じて、まずはともあれ手元の環境で触ってみたくなってきたのではないかと思います。
そこで今回は、オープンソースで開発され、パッケージも公開されているOSS版のPG-Stromを実際に動かしてみたいと思います。
PG-Stromの動作要件
というわけで、早速触ってみましょう。必要なものは以下のとおりです。なお、WindowsのWSLには対応していないため、Linux版のPostgreSQLとCUDA、GPUドライバーが必要です。
- インストールするバージョンのCUDAと互換性のあるLinux
- CUDA 12.2Update 1以降*1に対応するNVIDIAのGPU
- CUDA 12.2Update 1以降*1に対応するLinuxとLinux kernel
- インストールしたCUDAバージョンと互換性のあるGPUドライバー
PG-Stromは、CUDAとGPUドライバーが正常にLinux上で動作していることが重要です。また、導入するLinuxディストリビューションがCUDAの要件を満たす必要があります。
なお、今回使用するPG-Strom 5.1は、CUDA 12.2以降とPostgreSQL 15以降のバージョンが必要です。今回は例として、PG-Strom 5.1をAlmaLinux 9.3+CUDA 12.4.1 (CUDA 12.4 Update 1)で利用する方法を紹介します。
AlmaLinuxはNVIDIA CUDAがサポートしているOSの一覧には含まれていませんが、基本的に他のRHELクローンディストリビューションと同等なので、Rocky Linuxの手順を参考にインストールしてみてください。
また、他のLinuxディストリビューションを使う場合は、上記のほか、開発ツールのインストールをしたうえでソースビルドによるインストールをお試しください。著者の環境ではRHEL 8および9、Rocky Linux、AlmaLinux、MIRACLELINUX、UbuntuなどでソースビルドしたPG-Stromの正常動作を確認しています。基本的にはCUDAをサポートするx86_64なLinuxで、CUDA 12.2以降と適切なGPUドライバー、PostgreSQL 15以降がインストールされていれば、どのLinuxディストリビューションでも動作するはずです。
事前準備
RHELやRHELクローンではデフォルトで有効化されているパッケージリポジトリーの他、いくつかのリポジトリーの有効化が必要です。1つはEPEL(Extra Packages for Enterprise Linux)で、もう1つはRed Hat CodeReady Linux Builderです。RHELクローンの場合はpowertoolsやCRBという名前のリポジトリーです。
AlmaLinux 9の場合は、次のように実行してください。
$ sudo dnf -y install epel-release
$ sudo dnf config-manager --set-enabled crb開発ツールのインストールも必要です。その他、関連するパッケージをインストールします。
$ sudo dnf -y groupinstall 'Development Tools'
$ sudo dnf -y install wget gitなお、このガイドに従ってインストールする場合は、SELinuxについては標準設定から変更する必要はありません。
CUDAのインストール
CUDAは公式サイトの手順に従ってインストールします。Linux版は様々なディストリビューションに対応しているため、導入する「Distribution」を選択すると手順が示されます。AlmaLinuxの場合は(同じRHELクローンである)「Rocky」を選ぶと表示される手順と同様のコマンドを実行すればOKです。
バージョンはインストールしたOSのバージョンを選択します。今回の場合は「9」を選び、Installer Typeは「rpm(local)」を選択します。もしrunfileを使ったCUDAのインストールに慣れている場合は、そちらでインストールしても構いません。
「rpm(local)」を選んだ場合は、次のように実行します。
$ wget https://developer.download.nvidia.com/compute/cuda/12.4.1/local_installers/cuda-repo-rhel9-12-4-local-12.4.1_550.54.15-1.x86_64.rpm
$ sudo rpm -i cuda-repo-rhel9-12-4-local-12.4.1_550.54.15-1.x86_64.rpm
$ sudo dnf clean all
$ sudo dnf -y install cuda-toolkit-12-4CUDAのインストール後は互換性のあるGPUドライバーをインストールします。Turing世代以降のGPUの場合は「open kernel module flavor」が利用できます。それより古い世代のGPUを使う場合は「legacy kernel module flavor」を選択してください。
OSS版では特に考慮する必要はありませんが、商用版を使う場合は「open kernel module flavor」が使える世代のGPUを選択しないと、GPU Direct Storageを使うことが難しくなります。
Turing世代以降のGPUでは、次のようにOpen kernel moduleの方をインストールします。
$ sudo dnf -y module install nvidia-driver:open-dkmsTuring世代以前のGPUでは、従来のドライバーをインストールします。
$ sudo dnf -y module install nvidia-driver:latest-dkmsGPUドライバーがインストールされたら、いったん再起動します。再起動後nvida-smiコマンドを実行して、エラーが出ないことを確認してください。
Nouveauドライバーの無効化
LinuxはNVIDIAのGPUが認識されるとデフォルトでNouveauドライバーを有効にします。これは2Dグラフィックのレンダリングには充分機能するドライバーですが、今回はGPUコンピューティングのために使うのと、このドライバーが有効だと困ることもあるため、次の方法で起動時にNouveauドライバーを読み込まないように設定します。
$ sudo su -
# cat > /etc/modprobe.d/disable-nouveau.conf <<EOF
blacklist nouveau
options nouveau modeset=0
EOF
# dracut -f && rebootPostgreSQLのインストール
次に、PostgreSQLをインストールします。PG-Strom 5.xでサポートされているPostgreSQLは15以降のバージョンです。今回はPostgreSQL 16をインストールする場合を例とします。PostgreSQL 15を使いたい場合は、以下16のところを15に置き換えて実行してください。
インストールするには、PostgreSQLのリポジトリーのパッケージを利用します。AlmaLinux 9の場合は、次のように実行します。
$ sudo dnf -y install https://download.postgresql.org/pub/repos/yum/reporpms/EL-9-x86_64/pgdg-redhat-repo-latest.noarch.rpm
$ sudo dnf -qy module disable postgresql
$ sudo dnf -y install postgresql16-server postgresql16-devel
$ sudo /usr/pgsql-16/bin/postgresql-16-setup initdb
$ sudo systemctl enable --now postgresql-16PG-Stromのインストール
PG-StromのパッケージはRHELおよびRHELクローン向けのrpmパッケージが用意されています。RHELおよびRHELクローンのバージョン8や9であればrpmパッケージでインストールできます。
本連載でこれまで説明してきたように、PG-StromはPostgreSQLの拡張機能として動作します。したがってPG-Stromをインストールする前にPostgreSQLがインストールされている必要があります。例えばPostgreSQL 16がインストールされている環境では、次のようにコマンドを実行します。
$ sudo dnf -y install https://heterodb.github.io/swdc/yum/rhel9-noarch/heterodb-swdc-1.3-1.el9.noarch.rpm
$ sudo dnf -y install pg_strom-PG16
...
Running transaction
Preparing : 1/1
Installing : pg_strom-PG16-5.1-0.el9.x86_64 1/1
Running scriptlet: pg_strom-PG16-5.1-0.el9.x86_64 1/1
Verifying : pg_strom-PG16-5.1-0.el9.x86_64 1/1
Installed:
pg_strom-PG15-5.1-0.el9.x86_64
Complete!PG-Strom 5.xはPostgreSQL 15および16に対応しています。PostgreSQL 15をインストールした場合、上記はpg_strom-PG15パッケージをインストールすればOKです。
詳細は取り上げませんが、次の方法でソースからPG-Stromをインストールすることも可能です。ソースビルドを行う場合は、RHELおよびRHELクローン以外のLinuxディストリビューションでも対応するCUDAとCUDAドライバーさえ導入できればPG-Stromを動かすことができます。ソースビルドについては公式のインストールガイドをご覧ください。
PG-Stromインストール後の設定
PG-Stormをインストールしただけでは、まだPostgreSQLでPG-Strom拡張機能は利用できていない状態です。次の設定を行って、PG-Strom拡張機能を有効化できるように、PostgreSQLの設定にPG-Stromに必要な設定を追記します。
$ sudo su - postgres
$ vi /var/lib/pgsql/16/data/postgresql.conf
... (最終行に追記)
shared_preload_libraries = '$libdir/pg_strom'
max_worker_processes = 100
shared_buffers = 8GB
work_mem = 1GB追記した設定をPostgreSQLに反映させるため、PostgreSQLサービスを再起動します。
$ exit
$ sudo systemctl restart postgresql-16
$ journalctl -u postgresql-16journalctl -u postgresql-16を実行した結果、次のような出力があればOKです。
systemd[1]: Starting PostgreSQL 16 database server...
postmaster[1326]: 2024-04-09 17:24:06.355 JST [1326] LOG: redirecting log output to logging collector process
postmaster[1326]: 2024-04-09 17:24:06.355 JST [1326] HINT: Future log output will appear in directory "log".
Apr 09 17:24:07 inspiron-3881.local.tooyama.org systemd[1]: Started PostgreSQL 15 database server.
systemd[1]: Stopping PostgreSQL 16 database server...
systemd[1]: postgresql-16.service: Killing process 1516 (postmaster) with signal SIGKILL.
systemd[1]: postgresql-16.service: Deactivated successfully.
systemd[1]: Stopped PostgreSQL 16 database server.
systemd[1]: Starting PostgreSQL 16 database server...
postmaster[5626]: 2024-04-09 17:40:01.447 JST [5626] LOG: HeteroDB Extra module is not available
postmaster[5626]: 2024-04-09 17:40:01.447 JST [5626] LOG: PG-Strom version 5.1.0 built for PostgreSQL 15 (githash: )
postmaster[5626]: 2024-04-09 17:40:03.483 JST [5626] LOG: PG-Strom binary built for CUDA 12.4 (CUDA runtime 12.4, nvidia kmod: 550.54.15)
postmaster[5626]: 2024-04-09 17:40:03.483 JST [5626] LOG: PG-Strom: GPU0 NVIDIA GeForce GTX 1650 SUPER (20 SMs; 1725MHz, L2 1024kB), RAM 3732MB (128bits, 5.72GHz), PCI-E Bar1 0MB, CC 7.5
postmaster[5626]: 2024-04-09 17:40:03.485 JST [5626] LOG: [0000:00:00.0]
postmaster[5626]: 2024-04-09 17:40:03.485 JST [5626] LOG: - [0000:00:01.0]
postmaster[5626]: 2024-04-09 17:40:03.485 JST [5626] LOG: - [0000:01:00.0] ... GPU0 (NVIDIA GeForce GTX 1650 SUPER)
postmaster[5626]: 2024-04-09 17:40:03.485 JST [5626] LOG: - [0000:00:1b.0]
postmaster[5626]: 2024-04-09 17:40:03.485 JST [5626] LOG: - [0000:02:00.0] ... nvme0 (CL1-3D256-Q11 NVMe SSSTC 256GB --> GPU0 [dist=5])
postmaster[5626]: 2024-04-09 17:40:03.564 JST [5626] LOG: redirecting log output to logging collector process
postmaster[5626]: 2024-04-09 17:40:03.564 JST [5626] HINT: Future log output will appear in directory "log".
systemd[1]: Started PostgreSQL 16 database server.もし正常に起動しなかったら
sudo systemctl restart postgresql-16コマンドを実行してサービスが起動しない場合は、次のあたりを確認してください。
- まず
journalctl -u postgresql-16で状況を確認 postgresql.confに書き加えた設定に間違いがないことを確認- 適切なバージョンのLinux kernelで起動しているか
- 適切なバージョンのCUDAがインストールされているか
- GPUドライバーが適切なバージョンが入っているか
3.についてはdkmsツールを利用することである程度吸収は可能ですが*2、最も適切なのはインストールしたCUDAのインストールガイドに示されたSystem Requirementsを満たす同じバージョンのLinux kernel、GCC、GLibcの組み合わせの環境に導入することです。
*2: バージョンアンマッチの問題は、DKMSが使える環境であればsudo dkms autoinstall && rebootでだいたい回避できます。EPELリポジトリーにdkmsパッケージがあるので、それを使って対応できますPG-StromがPostgreSQLで使えるか確認
次のように実行して、モジュールの読み込みができればPG-Stromの環境は準備できています。
$ sudo su - postgres
$ psql
psql (16.2)
Type "help" for help.
postgres=# CREATE EXTENSION pg_strom;
CREATE EXTENSION
postgres=# \dx
List of installed extensions
Name | Version | Schema | Description
----------+---------+------------+----------------------------------------------------------------
pg_strom | 5.1 | public | PG-Strom - Extension for Big-Data Processing using GPU/DPU/SPU
plpgsql | 1.0 | pg_catalog | PL/pgSQL procedural language
(2 rows)postgresデータベースはインストール時にデフォルトで生成されるデータベースです。以降の解説では使いませんので、この確認が終わったら次を実行しておきましょう。
postgres=# DROP EXTENSION pg_strom;PG-Stromを使ってみよう
ここまででセットアップが終わったので、いよいよ早速使ってみましょう! …と言っても、処理するデータがなければ使えませんよね。そこで、次の方法でテスト用データを手元のPG-Strom環境に作ってみてください。
ログインとデータベースの作成
PostgreSQLをインストールすると、デフォルトでpostgresというユーザーが作られます。今回はpostgresユーザーを使ってアクセスしますが*3、アクセス方法は通常PostgreSQLを使うときと同じです。suコマンドでpostgresユーザーに切り替えてから実行します。
*3: セキュリティーを考慮すればデフォルトユーザーの利用は極力避けるべきという声が上がりそうですが、今回はローカルでのみ利用することを想定しているためpostgresユーザーを使っていきますデータベースを作成したら\cコマンドでそのデータベースに切り替えて、CREATE EXTENSION pg_stromを実行します。これで、このデータベース内のテーブルでPG-Strom拡張機能を使えるようになります。
$ sudo su - postgres
$ psql
psql (16.2)
Type "help" for help.
postgres=# CREATE DATABASE testdb;
postgres=# \c testdb
testdb=# CREATE EXTENSION pg_strom;テストデータを使ってPG-Stromに触れてみる
次のようなコードを使って、テストデータを作成します。GENERATE_SERIESで指定する数値が大きいほどデータサイズも大きくなるため、あらかじめそれらのデータを格納できるだけのストレージの空き領域が必要です。今回の例ではおおよそ2,000万件、1GBくらいのデータが作成されます。
=# CREATE TABLE uriage1
(
number SERIAL,
name VARCHAR(128) NOT NULL,
okashi VARCHAR(128) NOT NULL,
amount_sold INTEGER NOT NULL
);
=# INSERT INTO
uriage1 (name,okashi,amount_sold)
SELECT
(array['Alice', 'Jane', 'Ted', 'Bob'])[ceil(random() * 4)] AS name,
(array['Candy', 'Cookie', 'Chocolate', 'Icecream'])[ceil(random() * 4)] AS okashi,
ceil(random() * 100) *10 amount_sold
FROM
GENERATE_SERIES(1, 20000000);
=# VACUUM uriage1;
=# \db+
testdb=# \db+
テーブル空間一覧
名前 | 所有者 | 場所 | アクセス権限 | オプション | サイズ | 説明
------------+----------+------+--------------+------------+---------+------
pg_default | postgres | | | | 1025 MB |
pg_global | postgres | | | | 565 kB |
(2 行)これで、テーブルデータが生成されました。データの準備ができたので、2,000件の中から「Tedさん」が買った商品を検索してみましょう。
=# SELECT count(name) FROM uriage1 WHERE name='Ted';
count
---------
5001056
(1 row)あっという間に結果が現れると思います。データはランダム生成なので、次の結果は手元で実行したときとは異なる可能性がありますが、実行してすぐ結果が表示されます。
これだけでは分からないのでEXPLAIN ANALYZEを頭に付けて、もう一度クエリを実行してみましょう。GPUという文字が見えていれば、PG-Stromを使ってPostgreSQLのデータを処理できています。
testdb=# EXPLAIN ANALYZE SELECT count(name) FROM uriage1 WHERE name='Ted';
QUERY PLAN
----------------------------------------------------------------------------------------------------
Aggregate (cost=55050.48..55050.49 rows=1 width=8) (actual time=669.369..675.559 rows=1 loops=1)
-> Gather (cost=55050.37..55050.48 rows=1 width=8) (actual time=669.118..675.553 rows=1 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Parallel Custom Scan (GpuPreAgg) on uriage1 (cost=54050.37..54050.38 rows=1 width=8) (actual time=651.687..651.689 rows=0 loops=3)
GPU Projection: pgstrom.nrows(name)
GPU Scan Quals: ((name)::text = 'Ted'::text) [plan: 20000070 -> 2106119, exec: 20000000 -> 4997303]
Planning Time: 0.070 ms
Execution Time: 675.746 ms
(9 rows)Arrow形式のデータをPG-Stromで利用する
PG-Stromの「arrow-fdw」というモジュールを使うと、PostgreSQLでArrowデータを扱えるようになります。先ほどのデータをArrowデータにして比較してみましょう。
次のような方法で、まずpg2arrowをインストールしてください。ここではPostgreSQL 15をインストールしていることを例に、インストール方法を紹介します。
重要なポイントは「PG-Stromと同じバージョンのソースからビルドする」ことです。PG-StromのソースはGitHubのPG-Stromプロジェクトで公開されていますが、パッケージについてはHeteroDB Software Distribution Centerで公開されています。ここからソースをダウンロードして、pg2arrowをビルドしてみましょう。
//インストールしているのはPG-Strom 5.1.0なので
$ rpm -q pg_strom-PG16
pg_strom-PG16-5.1-0.el9.x86_64
//PG-Strom 5.1.0のpg2arrowを導入する
$ wget https://heterodb.github.io/swdc/tgz/pg_strom-5.1.0.tar.gz
$ tar zvxf pg_strom-5.1.0.tar.gz
$ cd pg_strom-5.1.0/arrow-tools
$ make pg2arrow PG_CONFIG=/usr/pgsql-16/bin/pg_config
$ sudo install -o root pg2arrow /usr/local/bin/pg2arrow
//pg2arrow CLIが使えるか確認
$ pg2arrow --help
Usage:
pg2arrow [OPTION] [database] [username]
...インストールが終わったら、pg2arrow CLIを使って用意したテストデータをArrowデータに変換します。pg2arrowのコマンドオプションは大文字小文字の多少の違いはありますが、psql CLIと使い勝手は同じです。
$ sudo su - postgres
$ cd /opt/
$ mkdir arrow1
$ cd arrow1
$ time pg2arrow -u postgres -d testdb -c "SELECT * FROM uriage1" -o ./uriage1.arrow
real 0m6.480s
user 0m2.552s
sys 0m0.776sこれで/opt/arrow1/uriage1.arrowにPostgreSQLのテーブルデータがApache Arrowファイルとして出力されます。これをPG-Stromのarrow_fdwでPostgreSQLの外部テーブルとして登録してみましょう。
$ psql -d testdb
psql (16.2)
Type "help" for help.
testdb=# IMPORT FOREIGN SCHEMA arrow_uriage1
FROM SERVER arrow_fdw
INTO public
OPTIONS (file '/opt/arrow1/uriage1.arrow');複数のテーブルデータを1つのデータとして利用したい場合は、fileの代わりにdirでディレクトリーを指定できます。この場合、ディレクトリーには複数のApache Arrow形式のデータを保存します。Apache Arrow形式はデータの圧縮もサポートしますが、PG-Stromで利用できるのは非圧縮のデータのみです。また混乱の元になるので、ディレクトリーにはApache Arrow形式のデータ以外は置かないようにしてください。
IMPORT FOREIGN SCHEMA arrow_uriage_dirs
postgres-# FROM SERVER arrow_fdw INTO public
postgres-# OPTIONS(dir '/opt/arrow1');Arrow形式のデータをPG-Stromで使ってみる
先ほど登録したデータを使ってみましょう。使い方はこれまでの普通にテーブルデータを参照するときと一緒です。同じデータから生成したので当たり前ではありますが、クエリーを実行すると同じ結果になります。
testdb=# SELECT count(name) FROM uriage1 WHERE name='Ted';
count
---------
5001056
(1 row)
testdb=# SELECT count(name) FROM arrow_uriage1 WHERE name='Ted';
count
---------
5001056
(1 row)テーブルデータとArrowテーブルの比較
次に、テーブルデータとArrowデータを使って、同じクエリを実行してみましょう。1回目は少し時間がかかる傾向がありますが、おおよそ通常のテーブルのデータをArrow化することで、2倍高速にデータ処理できることが分かります。
//テーブルデータ
testdb=# EXPLAIN ANALYZE SELECT count(name) FROM uriage1 WHERE name='Ted';
...
Execution Time: 661.437 ms
...
Execution Time: 514.639 ms
...
Execution Time: 534.081 ms
//Arrowデータ
testdb=# EXPLAIN ANALYZE SELECT count(name) FROM arrow_uriage1 WHERE name='Ted';
...
Execution Time: 422.378 ms
...
Execution Time: 247.716 ms
...
Execution Time: 235.581 msArrowの結果に注目して、もう1度クエリーを実行してみましょう。注目すべきはfile0の列で、Arrowデータとしては510.22MBの容量のデータですが、今回の検索では147.82MBのサイズだけを読み込んでいるということが分かります。データをフルスキャンして、その中から検索した結果を出すわけではないため速いというわけです。
testdb=# EXPLAIN ANALYZE SELECT count(name) FROM arrow_uriage1 WHERE name='Ted';
QUERY PLAN
--------------------------------------------------------------------------------
Aggregate (cost=9532.49..9532.50 rows=1 width=8) (actual time=409.240..409.282
rows=1 loops=1)
-> Gather (cost=9532.38..9532.49 rows=1 width=8) (actual time=409.233..409.
277 rows=1 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Parallel Custom Scan (GpuPreAgg) on arrow_uriage1 (cost=8532.38..8
532.39 rows=1 width=8) (actual time=239.874..239.875 rows=0 loops=3)
GPU Projection: pgstrom.nrows(name)
GPU Scan Quals: (name = 'Ted'::text) [plan: 20000000 -> 41667, ex
ec: 20000000 -> 4999138]
referenced: name
file0: /opt/arrow1/uriage1.arrow (read: 147.82MB, size: 510.21MB)
GPU-Direct SQL: disabled (GPU-0; vfs=18922, ntuples=20000000)
Planning Time: 0.080 ms
Execution Time: 409.384 ms
(12 行)簡単な集計をしてみる
用意したデータを使って、簡単な集計を行ってみましょう。ストレージの応答なども関わってきますが、おおよそ最初は少し時間がかかるものの、それ以降は、そのだいたい半分の時間で同じ集計処理を実現できることが分かります。
test1: Icecreamの売上
testdb=# SELECT sum(amount_sold) FROM arrow_uriage1 WHERE okashi='Icecream';
sum
------------
2526466530
(1 row)
testdb=# EXPLAIN ANALYZE SELECT sum(amount_sold) FROM arrow_uriage1 WHERE okashi='Icecream';
...
Execution Time: 443.496 ms
Execution Time: 266.840 ms
Execution Time: 262.736 mstest2: Aliceさんが買ってくれたものの売上合計
testdb=# SELECT sum(amount_sold) FROM arrow_uriage1 WHERE name='Alice';
sum
------------
2523957610
(1 row)
testdb=# EXPLAIN ANALYZE SELECT sum(amount_sold) FROM arrow_uriage1 WHERE name='Alice';
...
Execution Time: 421.119 ms
Execution Time: 264.804 ms
Execution Time: 264.428 mstest3: 売上を商品別に集計
testdb=# SELECT okashi, sum(amount_sold) FROM arrow_uriage1 GROUP BY okashi;
okashi | sum
-----------+------------
Icecream | 2526466530
Candy | 2523868990
Chocolate | 2524402970
Cookie | 2525721290
(4 rows)
testdb=# EXPLAIN ANALYZE SELECT okashi, sum(amount_sold) FROM arrow_uriage1 GROUP BY okashi;
...
Execution Time: 719.197 ms
Execution Time: 536.548 ms
Execution Time: 536.005 msGPUDirect Storageが利用できるようなエンタープライズグレードなNVIDIAのGPUと高速なストレージを組み合わせて使うと、OSS版のPG-StromでSQLクエリーによっては2倍高速だったものが、さらに5倍から10倍以上の速度で検索できるようになります(クエリーやデータの特性によります)。
OSS版のPG-StromではNVMe SSDを1つだけ使えますが、商用版では複数のNVMe SSDを使うことができます。高速なストレージを複数束ねた領域にデータを置き、GPUコアとメモリがたくさん載ったGPUと組み合わせることで集計演算を効率化し、データの読み込み、ランダムアクセスの速度をさらに上げられるようになった結果、高速な処理を実現できるというわけです。
実際に同じクエリーをNVIDIA A100とLocal NVMe SSD×4枚+GPUDirect Storageが利用可能な環境で実行すると、次のようになります。
//test1
testdb2=# EXPLAIN ANALYZE SELECT sum(amount_sold) FROM arrow_uriage1 WHERE okashi='Icecream';
...
Execution Time: 91.038 ms
Execution Time: 90.831 ms
Execution Time: 89.886 ms
//test2
testdb2=# EXPLAIN ANALYZE SELECT sum(amount_sold) FROM arrow_uriage1 WHERE name='Alice';
...
Execution Time: 60.314 ms
Execution Time: 62.816 ms
Execution Time: 62.469 ms
//test3
testdb2=# EXPLAIN ANALYZE SELECT okashi, sum(amount_sold) FROM arrow_uriage1 GROUP BY okashi;
...
Execution Time: 145.073 ms
Execution Time: 146.095 ms
Execution Time: 144.506 ms「GDSなし」は厳密には一般的な構成のPCとGPUの組み合わせでPG-StromのOSS版を使った構成で、「GDSあり」はPG-Stromの商用版ライセンスがあり、NVIDIA A100 GPUと推奨する構成のマシンにNVMe SSD4枚をRAID0で束ねたストレージをPGDATA領域として構成した環境で比較しています。
本来はGPUも含めて同じハードウェア実装した環境で比較すべきかもしれませんが、一般家庭にNVIDIA A100があるのは極めて稀なので、とりあえずゲーミング用のPC環境で動かしてみたときと、理想的な環境でクエリー実行したときの性能差を表すことにしました。同じArrowデータを使ってクエリーを実行した場合の速度比較をすると、おおよそ次のような結果になります。
| 比較 (単位:ミリ秒) | test1 | test2 | test3 |
|---|---|---|---|
| GDSなし | 324.36 | 316.78 | 597.25 |
| GDSあり | 90.59 | 61.87 | 145.22 |
| 速度比較(倍) | 3.58 | 5.12 | 4.11 |
今回用意したデータの容量は512MB程度なので、十分GPUのメモリーに載るサイズです。データサイズが大きくなればなるほど、この速度差は大きくなります。
色々なソフトウェアからPG-Stromにつなぐ
PG-StromはPostgreSQLの拡張機能として動作します。それは裏を返せばPostgreSQL Serverをバックエンドに使えるソフトウェアであれば、 PG-StromのArrow toolsを使うことで、さまざまなデータをArrow形式でノードに取り込み、さまざまなアプリケーションからデータ分析に利用できることにもなります。
例えば、次のように、PostgreSQLに対応するBIツールで分析も可能です。TableauやGoogleのLooker、MicrosoftのPowerBIなど、代表的なBIツールに対応*4しています。
Tableau
Google Looker
MS PowerBI
RからPG-Stromに蓄積したデータを使って*5データ分析に利用することもできます。
VSCodeのR拡張機能を使ってコーディング
RStudioにも対応
DBIとPython+Pandasの組み合わせでも利用が可能です。例えば、JupyterLabなどを使ってPostgreSQLデータを使ったデータ分析にもPG-Stromを利用できます。
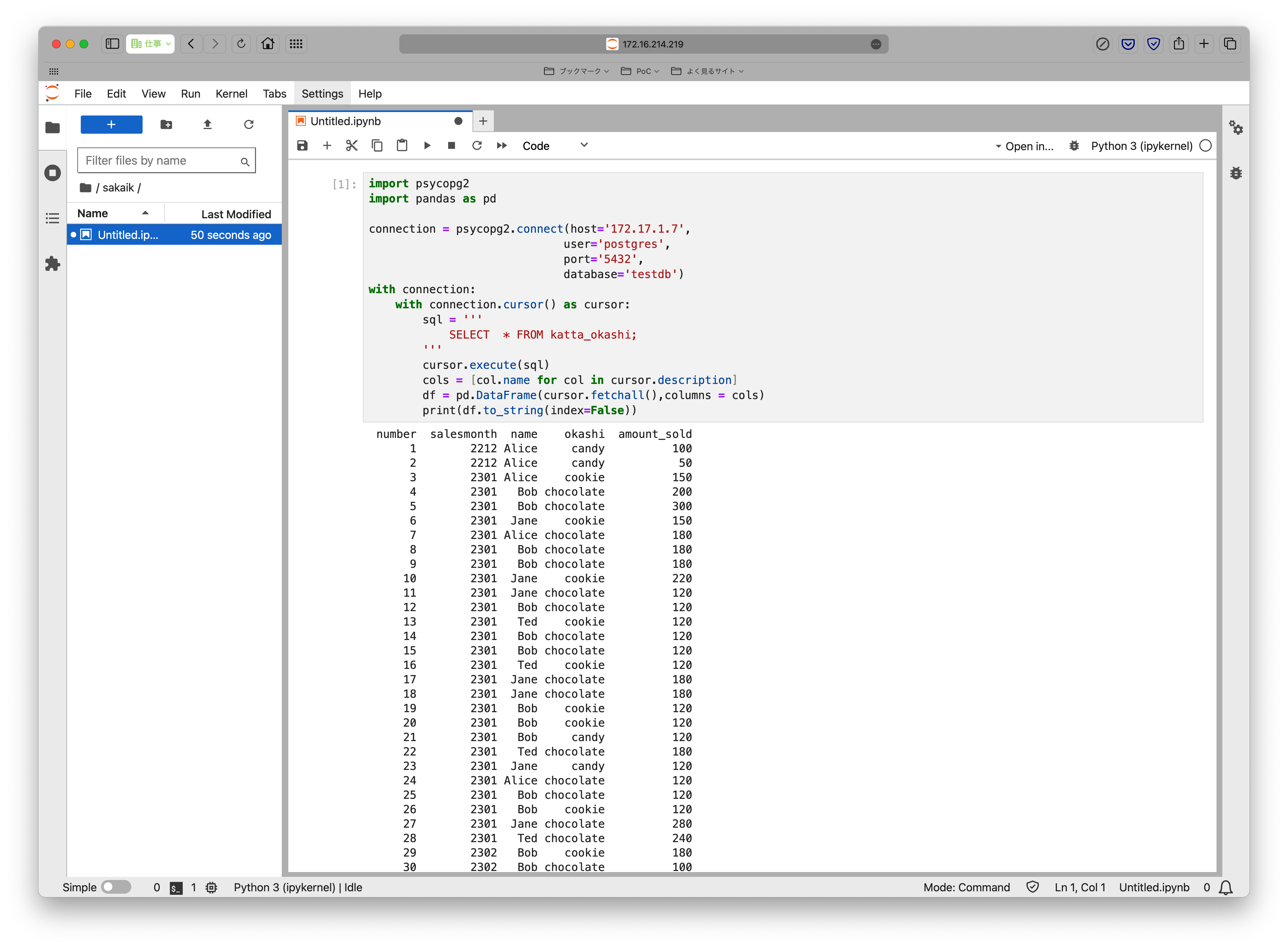
Jupyter notebookやJupyterLabからも利用できる
ログなどの集計にもPG-Stromを利用できます。PG-StromにはFluentd連携用のプラグインが用意されており、これとFluentdを組み合わせることでリアルタイムのログをArrowデータに流し込み、そのデータを使ってPG-Stromで分析するといったことが可能になっています。
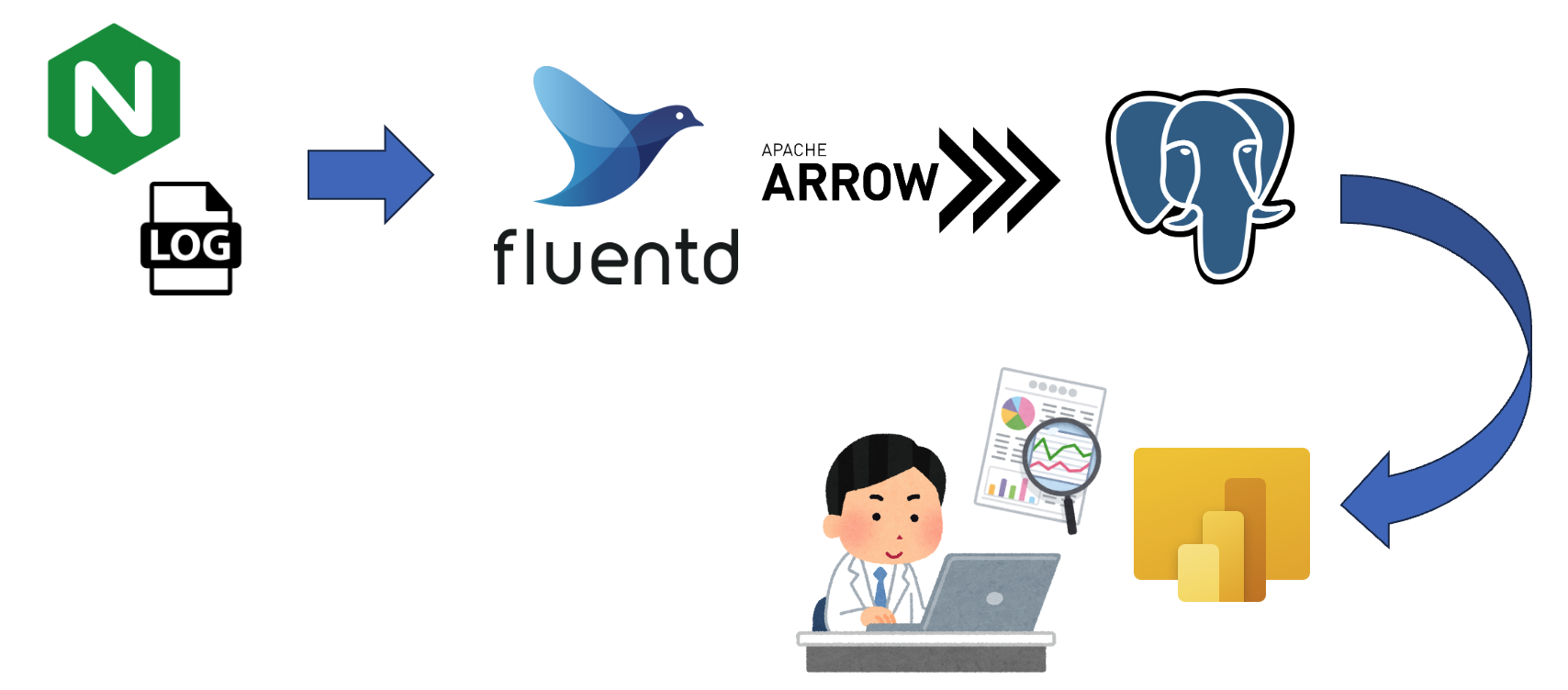
Fluentdを使ったリアルタイムログ分析
このように、PG-StromにはいくつかのApache Arrowをサポートするインターフェイスが備わっています。最初に紹介したpg2arrow、今回紹介しませんでしたが、そのMySQL対応バージョンであるmysql2arrow、Fluentdのプラグインfluent-plugin-arrow-fileなどなど、これらを使うことでPG-Stromがデータ分析基盤になります。
データはPostgreSQLテーブルデータとして認識されるため、SQLクライアントを介してアクセスできるほか、PostgreSQLデータベースをデータとして利用できるようなクライアント、例えばBIツールのようなものを使ってデータ分析などに利用することも可能です。
より本格的に、より大規模なデータを処理対象としたい場合はPG-Stromの商用版ライセンスと推奨される構成を満たす必要はあるものの、今回紹介したように、PG-StromはLinuxとNVIDIA GPU、PostgreSQLがあれば簡単に導入できます。
おわりに
今回は、AlmaLinux+CUDAの環境で、PG-Stromを活用したPostgreSQLの爆速化について解説しました。今回の記事を読んでいただいたのをきっかけに、ぜひPG-Stromを使い、皆さんご自身でその効果を体験してみてください。
- この記事のキーワード
この記事をシェアしてください
関連記事
スローログの集計に便利な「pt-query-digest」を使ってみよう
2016年4月25日 0:00
performance_schemaをsysで使い倒す!
2016年7月21日 0:00
WSLでUbuntuの最新LTSリリース「Ubuntu 26.04 LTS」を動かしてみよう
5月14日 6:30
ビッグデータ処理基盤に対応したFDWの紹介とhdfs_fdwの設計・構築の紹介
2018年8月3日 6:00
Ansibleのインストールとサンプルコードの実行
2016年3月8日 18:51
「WSL」を使って、話題の生成AI「Ollama」をWindowsで簡単に動かしてみよう
2025年7月8日 6:30
バックナンバー
この記事の筆者

Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
