検証!RACの耐障害性と拡張性
障害動作について
ここでは、障害時の動作とそのダウンタイムについて説明します。
1つ目が「インスタンス障害」です。インスタンス障害は、DBインスタンスを構成するSGA(System Global Area)、SMON(System MONiter)、DBWn、LGWRなどのバックグラウンドプロセスに障害が発生して、インスタンスが異常終了する障害です。
障害の発生したDBインスタンスが異常終了すると、Oracle Clusterwareによって障害が検知され、生存インスタンスによってインスタンスリカバリー処理が実施されます。DBインスタンスおよびASMインスタンスは、インスタンスモニターによって常時生死確認が行われています。
インスタンスモニターは障害を検出すると、Oracle Clusterwareにその状態を伝え、障害を起こしたインスタンスの再起動処理や、サービスのフェールオーバー処理、インスタンスリカバリー処理が開始されます。疑似障害を発生させる場合は、バッググラウンドプロセス(LGWRやLMSプロセスなど)を強制停止させてインスタンスを停止します。
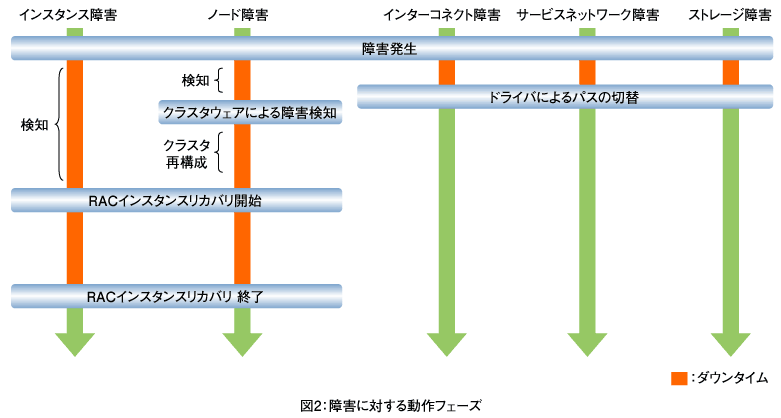
2つ目が「ノード障害」です。ノード障害は、電源やCPUなどのハードウエア障害やOS障害などの理由でサーバーが処理を継続できない状態です。ノード障害が発生すると、Oracle Clusterwareによる一定期間のハートビート処理によって障害を検知します。そして生存ノード上で、Oracle Clusterwareの再構成とインスタンスリカバリー処理、障害ノードのVIPのフェールオーバが実施されます。ノード障害の場合、図2の流れでリカバリー処理が実施されます。
切り替え処理による障害回復
3つ目が「インターコネクト障害」です。インターコネクト障害(1重)は、インターコネクトを構成するNIC、LANケーブル、ネットワークスイッチに障害が発生して、1経路が遮断する障害です。SolarisのIPMPやLinux/Windowsのチーミングによって冗長化すると、インターコネクト障害(1重)が発生しても即座にスタンバイの経路に切り替わります。このため、Oracle Clusterwareやインスタンスに対する影響なく処理も続けることができます。
4つ目が「サービスネットワーク障害」です。サービスネットワーク障害(1重)は、サービスネットワークを構成するNIC、LANケーブル、ネットワークスイッチに障害が発生して、1経路が遮断する障害です。インターコネクトと同様、IPMPやチーミングなどのOS機能によってRACに影響なく処理を続けることができます。
5つ目が「ストレージ障害」です。ストレージ障害(1重)は、DBサーバーとストレージを結ぶ経路を構成するホストバスアダプター(NAS構成の場合はネットワークカード)、ファイバー(NAS構成の場合はLANケーブル)、スイッチに障害が発生して、1経路が遮断する障害、あるいはストレージ自身の冗長化された構成部分(例:コントローラなど)の障害になります。パス障害については、マルチパスドライバーによる切り替え機能、コントローラ障害については、製品の持つフェールオーバ機能によって、これもRACに影響なく処理を続けることができます。
それぞれの障害に対する動作フェーズは図2のようになります。






