負荷分散の条件
負荷分散の条件
負荷分散を行うことができる参照系のクエリとは、SELECT文か、COPY [テーブル名] TO STDOUT文のいずれかです。ただし、以下の条件に該当する場合は、負荷分散は行われずすべてのバックエンドに対してクエリが実行されます。
・明示的なトランザクションブロック(BEGIN;...END;)で囲まれている場合
・SELECT文がシーケンス操作関数であるsetval()、nextval()を含む場合
・SELECT INTO文またはSELECT FOR UPDATE文の場合
・SELECT文で、クエリ文字列の先頭が「SELECT」でない場合
4つ目の条件は、意図的にレプリケーションさせたい場合に有効です。例えば自作の関数update_table_func()が内部でテーブルを更新する場合などは、SELECT文であってもすべてのバックエンドで実行する必要があります。このような場合は、以下のように先頭にコメントを付けて、すべてのバックエンド上でクエリを実行させることができます。
/*REPLICATION*/SELECT update_table_func();
レプリケーションの設定
次は、レプリケーションと負荷分散の設定方法について説明します。
では実際にレプリケーションの設定を行いましょう。今回は1台のマシンで2つのPostgreSQLを起動し、レプリケーションの動作を確認します。
まず、PostgreSQLを停止しデータベースインスタンスを丸ごとコピーします。
$ su - postgres
$ cd /usr/local/pgsql
$ cp -Rp data data2
そして、起動するポート番号を変更してPostgreSQLを起動します。
$ bin/postmaster -p 5433 -D data2
「第2回:コネクションプールで接続負荷を軽減!(http://www.thinkit.co.jp/article/98/2/)」で説明したコネクションプールの設定では、pgpool.confに1つだけバックエンドを登録しました。これと同様に、pgpool.confに新しいバックエンドの追加を行います。pgpoolAdminの「pgpool.conf設定」画面から「Backends」セクションの「追加」ボタンを押し、新しいバックエンドの情報を入力します。
・「new backend_hostname」に「localhost」
・「new backend_port」に「5433」
・「new backend_weight」に「1」
次に「Replication」セクションの設定として「replication_mode」をチェックします。
次に「Health Check」セクションの設定として「health_check_user」にバックエンドに接続可能な有効なユーザー名を設定します。
health_check_userは通常、pgpool-IIがネットワーク障害などを検出するために定期的にバックエンドとの接続を確認するための設定ですが、それ以外にpgpoolAdminがノードステータスを表示する時にもこの設定を使ってバックエンドと接続を行うため、pgpoolAdminを使う場合はhealth_check_userに有効なユーザー名を指定しておくことが推奨されます。
ここまでの設定が終わったら、画面最下部の「更新」ボタンを押しましょう。
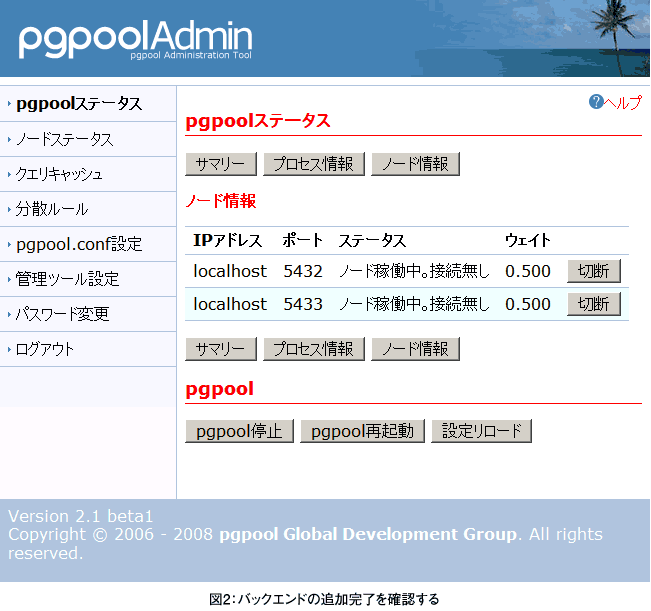
「pgpoolステータス」画面の「pgpool再起動」ボタンを押すと、図2のように追加したノードの情報が表示されます。
また、「サマリー」ボタンを押して、レプリケーションモードがオンになっているかを確認しましょう。
これでレプリケーションの設定が完了しました、psqlからpgpool-IIに接続してテーブルの作成やデータの操作を行ってみましょう。また、psqlからそれぞれのバックエンド(ポート5432とポート5433)に直接接続することで、データがレプリケーションされていることが確認できます。
次は負荷分散の設定を行います。
- この記事のキーワード
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
