レプリケーション&負荷分散!
pgpool-IIのレプリケーション 「第2回:コネクションプールで接続負荷を軽減!(http://www.thinkit.co.jp/article/98/2/)」は、pgpool-IIのコネクションプール機能を使って、接続のオーバーヘッドを減らし、性能を向上させる方法について紹介しました。
2008年7月17日 20:00
pgpool-IIのレプリケーション
「第2回:コネクションプールで接続負荷を軽減!(http://www.thinkit.co.jp/article/98/2/)」は、pgpool-IIのコネクションプール機能を使って、接続のオーバーヘッドを減らし、性能を向上させる方法について紹介しました。
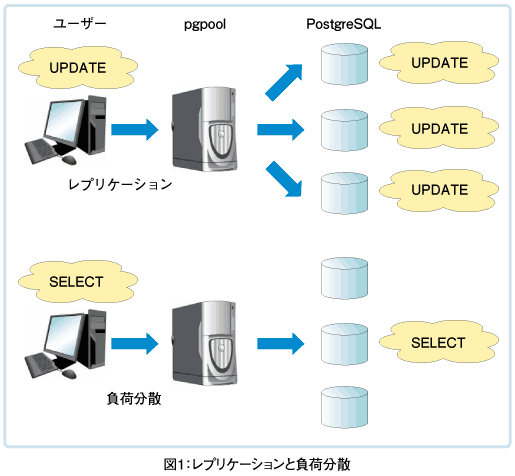
今回は、レプリケーションと負荷分散について説明します。レプリケーションは可用性を、負荷分散は性能を向上させる機能です。もちろんこれらの機能は前回紹介したコネクションプール機能と組み合わせて使うことができます。
レプリケーションとは、文字通りデータの複製(レプリカ)を複数のPostgreSQL上に作成する機能です。いずれかのサーバーに障害が発生しても、複製したデータを使って直ちに別のサーバーでサービスを継続することができるため、可用性が向上します。
pgpool-IIのレプリケーションは、クライアントから受け取ったクエリを、直ちにpgpool-IIが複数のPostgreSQLに送信することで実現しているため、各バックエンド間のデータは常に一致しています。このような、タイムラグの無いレプリケーションを「同期レプリケーション」と呼びます。
前回紹介したコネクションプールでは、pgpool.confのbackend_hostname0、backend_port0といった項目に接続先のバックエンドの情報を設定しました。レプリケーションを行う場合は同様にbackend_host1から128までのバックエンドを設定することができます。
PostgreSQLには、ほかにもSlony-Iなどのレプリケーションミドルウエアが存在します。これらの特徴については、PostgreSQLドキュメントの「第25章 高可用性、負荷分散およびレプリケーション(http://www.postgresql.jp/document/current/html/high-availability.html)」で紹介されています。
負荷分散とは
負荷分散とは、SELECT文のような参照系のクエリを複数のバックエンドの中からどれか1つに割り振り、システム全体の性能を向上させる機能です。最良の場合にはサーバー台数に比例した性能向上が見込めます。特に多数のユーザーが大量の問い合わせをするような環境で威力を発揮します。
参照系のクエリをどのサーバーが実行するかは、pgpool.confのbackend_weightで設定した比率を元にランダムに決定します。例えばbackend_weight0を2に、backend_weight1を1に設定した場合、1つ目のバックエンドには2つ目のバックエンドの2倍の割合で参照系のクエリが実行されます。
また、この参照クエリの割り振り先はクライアントからの接続時に決定します。一度接続すると、参照クエリの割り振り先は接続しなおすまで変わりません。
負荷分散の対象となる参照系クエリについては次ページで紹介します。
- この記事のキーワード
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
