バックエンド処理に挑戦!
問い合わせが結果を得るまで これまでPostgreSQLとはどんなものかをプレスリリースと歴史に関するドキュメントから解説しました。今回は問い合わせ命令をデータベースシステムが受け取ってから、その回答を返すまでにどのような手順が踏まれているのかをおおまかに見てみたいと思います。しかし、その仕組みは
2008年7月19日 20:00
問い合わせが結果を得るまで
これまでPostgreSQLとはどんなものかをプレスリリースと歴史に関するドキュメントから解説しました。今回は問い合わせ命令をデータベースシステムが受け取ってから、その回答を返すまでにどのような手順が踏まれているのかをおおまかに見てみたいと思います。しかし、その仕組みはとても複雑で一筋縄では行きません。英語のドキュメントはどうなっているのかがテーマです。内部処理を理解する目的ではありません。
PostgreSQLは整備されたオフィシャルドキュメントをhtml形式で提供しています。日本PostgresSQLユーザ会ではこれを日本語化して公開(http://www.postgresql.jp/document/)しています。そのほかに、すべてではありませんが、ソースコードに付属するREADMEドキュメントや、Cソースの中のコメントなどがあります。このような文書類も自由に使用できる状況でダウンロード(http://www.postgresql.jp/PostgreSQL)できることをぜひ覚えておいてください。
さて、PostgreSQLはクライアントサーバ型の関係データベース管理システムです。フロントエンドと呼ぶクライアントアプリケーションが問い合わせを、バックエンドと呼ぶサーバプロセスが処理し、そして結果セットをフロントエンドに返します。psqlもフロントエンドの1つです。
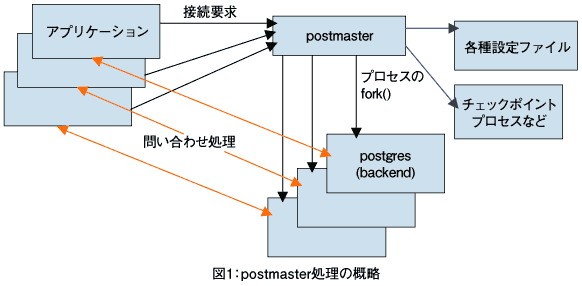
アプリケーションの問い合わせ要求に対し、その回答をサーバが返すまでのおおまかな流れは、例えばPostgreSQLに同梱(どうこん)されるpsql対話型端末を起動し、SQL文を送り、結果を画面に表示するという単純なものであっても、サーバの内部の動きはとても複雑で多様です。これらバックエンド処理のソースコードは、解凍したディレクトリの中のsrc/backendディレクトリにあります。なお、説明(図2)とおおまかな流れ(図3)を図にしたものは2ページ、3ページ目にあります。
では早速、最初のバックエンドとの接続関連を、ソースコードのsrc/backend/postmaster/postmaster.cから拾って読んでみましょう。
This program acts as a clearing house for requests to the POSTGRES system. Frontend programs send a startup message to the Postmaster and the postmaster uses the info in the message to setup a backend process.
「このプログラムはPOSTGRESシステムに対する要求に対し、交通整理的な振る舞いを行います。フロントエンドプログラムは開始メッセージをPostmasterに送り、postmasterはメッセージ内の情報をバックエンドプロセス設定に使用します。postmasterはPostgreSQLの管理・監視デーモンです」
"clearing house"は「手形交換所」ですが、上記のように意訳しました。postmasterはフロントエンド(アプリケーション)の接続要求を監視します。接続するとpostmasterは子プロセスをフォークし、子プロセスは共有メモリを確保し、バックエンド(postgres)となります。続けます。
When a request message is received, we now fork() immediately. The child process performs authentication of the request, and then becomes a backend if successful.
「要求メッセージを受け取ると、直ちにfork()を行います。子プロセスは要求の認証を実行し、成功した場合はbackendとなります」
"authentication"は「認証」で、postmasterは設定ファイルを参照し、接続要求が正規のクライアントであるかどうかを特定します。
アナライザーの役目
パーサはフロントエンドからの問い合わせを解析します。PostgreSQLのSQL文法にのっとっている限りエラーにはなりません。そして平文のSQLを内部的なパース木に変換します。次のステップのアナライザー /src/backend/parser/analyze.c のはじめを読んでみましょう。
analyze.c
transform the raw parse tree into a query tree
"raw parse tree"「生のパース木」を"query tree"「問い合わせ木」に変換する。
この段階でSQL文は文法的なチェックを受けただけなので、ここでのパース木には"raw"「生の」「加工していない」という形容詞がついています。
For optimizable statements, we are careful to obtain a suitable lock on each referenced table, and other modules of the backend preserve or re-obtain these locks before depending on the results.
「最適化できる文については、参照されるそれぞれのテーブルに対し適切なロックの取得に注意します。そして、バックエンドのそのほかのモジュールは、結果はどうなるかを別にしてこれらのロックを維持するか、再取得します」
問い合わせが最適化されるとした場合、データの整合性を保つため該当するテーブルにロックをかける必要があります。“depending on the result”は「結果に依存する」が直訳ですが、原文の趣旨は「結果としてうまく行く場合もありますが、確かではありません。だから念のため」を言いたいのです。
It is therefore okay to do significant semantic analysis of these statements. For utility commands, no locks are obtained here (and if they were, we could not be sure we'd still have them at execution).
「従って、それらの文に意義のある有効な意味解析を行うことは認められます。ユーティリティーコマンドに対しここではロックは取得されません(そして、もしロックがあったとしてもそれらロックが実行過程まで存在するかどうかわかりません)」
"semantic analysis"は「意味解析」。"statement"は「命令文」「構文」でここでは単に「文」としています。ユーティリティーコマンドとは、例えば「CREATE INDEX」「COPY」「VACUUM」など一般的な実用性の高いコマンド群を表します。
次ページでは、プラン作成と最適化について見てみましょう。
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
