PostgreSQLクラスタの動向
はじめに今回は、代表的なOSSデータベースである「PostgreSQL」を用いたデータベース・クラスタの、これまでの経緯と現状を解説します。1. 最初はシングル・マスターのレプリケーション最初に登場した"PostgreSQLクラスタ"は、「Slony」と呼ぶ、シングル・マスターのレプリケーション・ソ
2010年10月12日 20:00
はじめに
今回は、代表的なOSSデータベースである「PostgreSQL」を用いたデータベース・クラスタの、これまでの経緯と現状を解説します。
1. 最初はシングル・マスターのレプリケーション
最初に登場した"PostgreSQLクラスタ"は、「Slony」と呼ぶ、シングル・マスターのレプリケーション・ソフトでした。レプリケーションとは、データベース全体のコピーのことです。これを高可用性(HA)の確保や性能の向上に用いることができます。
Slonyのバージョン1.0がリリースされたのは2004年です。6年も前になります。Slonyは、トリガーの機構を使ってデータベースの変更を検出し、これを複数のスレーブに転送します。これにより、1つのマスターを利用して複数のスレーブにデータベースのコピーを置くことができるようになっています。図1に、その概要を示します。
|
| 図1: Slony-1の概要 |
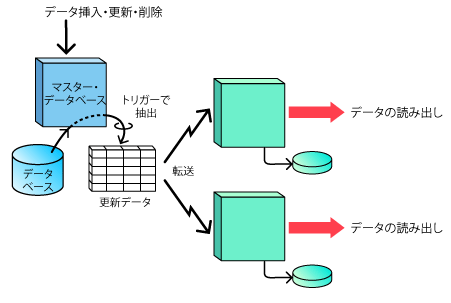
Slonyの特徴は、原理が単純な点で、PostgreSQL本体への改造も不要であり、かつ、各スレーブに対して参照用のSQLを発行できることです。クラスタ全体の整合性が問題にならないのであれば、スレーブで独自にデータを更新することも可能です。
マスターからスレーブへのデータ転送が非同期に行われるため、マスターがクラッシュして元のデータベースの更新情報が失われると、スレーブでも同じことが起こってしまいます。こうした制約があるものの、手軽に使えるため、現在でもレプリケーションを必要とする多くのアプリケーションで使われています。
2. その後、続々とクラスタが出現
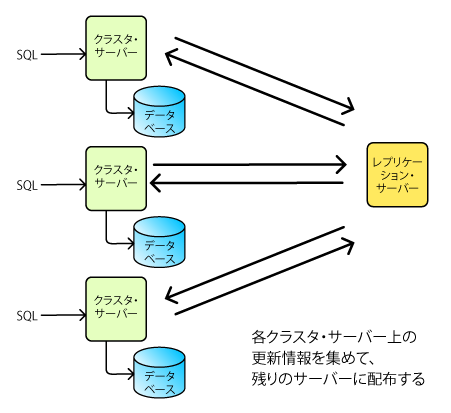
Slony-1と前後して、マルチマスター型のクラスタである「PGCluster」がリリースされました(図2)。その後、pgpool-IIが、同じくマルチマスター型のクラスタとしてリリースされました。この間には、Slonyを同期マルチマスター化する試みも行われたりしています。
|
| 図2: PG Clustorの概要 |
- この記事のキーワード
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
