| ||||||||||||||||||
| 前のページ 1 2 | ||||||||||||||||||
| postgresql.confの設定を見直そう | ||||||||||||||||||
PostgreSQLの設定ファイルであるpostgresql.confには性能に関する項目がいくつかあります。まずはこれらについて見直しましょう。 | ||||||||||||||||||
| shared_buffers | ||||||||||||||||||
shared_buffersには、PostgreSQLのデータベースエンジン(バックエンド)が使用する共有メモリ上のバッファ領域を指定します。shared_buffersは大きすぎても小さすぎても性能が低下します。初期状態ではinitdbの自動設定機能により、1000程度に設定されていると思いますが、できれば8000〜10000程度まで引き上げた方がよいでしょう。これ以上の値を指定すると、バッファ管理のオーバーヘッドにより逆に性能が低下します。 shared_buffersを大きくするとpostmasterが立ち上がらないことがあります。その場合はOSの共有メモリ領域を拡張します。共有メモリの拡張方法の詳細は、PostgreSQLマニュアルの「16.5.1. 共有メモリとセマフォ」をご覧ください。 ところで、「メモリが空いているようなのでそれをPostgreSQLで有効に使いたい」という質問に対して「shared_buffersをできるだけ多く取ってください」というような回答を目にすることがよくありますが、前述のようにそれは間違いです。PostgreSQLでは、むしろ余ったメモリをOSにバッファ領域として使ってもらった方がトータルでの性能が向上します。 | ||||||||||||||||||
| deadlock_timeout | ||||||||||||||||||
PostgreSQLは自動的にデッドロックを検出する仕掛けを持っています。PostgreSQLで採用されているのは、トランザクションが直接/間接にロックを待っている状態をグラフにし、その中に閉ループが含まれているかどうかを調べる方式です。閉ループが含まれていれば、デッドロックが発生します。たとえば、トランザクションT1、T2がテーブルt1、t2に次のような順序でロックをかけると、図1のようなロック状態になり、デッドロック発生と判断されます。 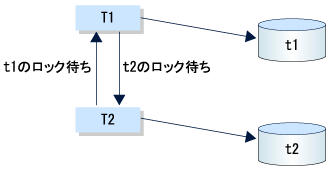 図1:デッドロック状態 | ||||||||||||||||||
T1: LOCK TABLE t1; | ||||||||||||||||||
データベースシステムの中には、実際にロック取得を試みて、一定時間経過してもロックが取得できない場合にデッドロックと判断するシステムもあるようですが、これでは単に処理が遅いだけなのか、本当にデッドロックが発生しているのか区別がつかず、誤った判定をする可能性があります。それに比べてPostgreSQLではきちんとデッドロックを検出しているため、このような誤動作の心配がありません。 ただ、デッドロック検出は比較的重い処理であるため、PostgreSQLではロック取得を試みてすぐではなく、一定時間経ってもロックが取得できない場合のみデッドロック検出処理を行います。この「一定時間」に相当するのが「deadlock_timeout」パラメータです。 デッドロック検出処理はデータベースセッションごとに行われます。負荷が高い場合はdeadlock_timeoutで指定した時間が経過してもロックが取得できないことが多いので、同時セッション数が多いとより短い間隔でデッドロック検出処理が実行されるようになり(たとえば100セッション存在するときは、最悪、deadlock_timeout/100ごとに検出処理が発生する)、その結果、ますますシステム負荷が高くなるという悪循環に陥ってしまいます。 この問題を回避するには、deadlock_timeoutを長めに設定します。デフォルトは1000ミリ秒(すなわち1秒)ですが、これに同時セッション数を乗じた値にするとよいでしょう。たとえば同時セッション数が100ならば100000にします。 deadlock_timeoutを長くすると当然デッドロックの検出が遅れるようになりますが、そもそもデッドロックが発生すること自体が問題なのです。デッドロックが発生しなければ、deadlock_timeoutを長くしても実用上支障ありません。 | ||||||||||||||||||
| 前のページ 1 2 | ||||||||||||||||||
| ||||||||||||||||||
| ||||||||||||||||||
| ||||||||||||||||||
-
人気記事ランキング
-
-
連載


新着記事
NVIDIAら37社が「Open Secure AI Alliance」設立――AIエージェントのセキュリティは重みの非公開では守れない 6:20 【クラウドネイティブ会議】厳格な統制と開発者体験を両立する、Wiz Baseにおけるゴールデンパスの実践 6:00 その「ソーシャルログイン」は大丈夫? OAuth/OIDC実装の3つの落とし穴 7月29日 6:30 KubeCon Europe 2026、新興のオブザーバビリティ企業Hygroundの製品責任者にインタビュー。生成AIの使用を前提にした新世代オブザーバビリティとは 7月29日 6:00 障害発生時でも継続運用を実現する「MySQL」と「PostgreSQL」の「高可用性構成」を理解する 7月28日 6:30