はじめに
Kubernetes 1.18(以降、1.18)が2020年3月24日にリリースされました。ここではリリースノートで紹介された5つの注目機能に加えて、筆者が注目するHorizontalPodAutoscalerのspec.behaviorフィールドの追加、ノードローカルDNSキャッシュ、Pod StartupProbeを紹介し、最後にStartupProbeを試していきます。
Kubernetes 1.18注目の新機能
最初に1.18リリースノートにおける5つの注目機能について、それぞれ解説します。
Topology Manager(ベータ)
Topology Managerは、NUMA(Non-Uniform Memory Access、ヌマ)の環境において、コンテナの使用するCPUとデバイスの同一ソケット(NUMAノード)への割り当てを可能にします。Topology Manager(トポロジマネージャ)は1.18でベータに昇格し、デフォルトで使用できるようになりました。
NUMAアーキテクチャは、図1のように複数のCPUから構成されるアーキテクチャで、各ソケット(NUMAノードと呼ぶ)それぞれが自身のCPU、メモリ、PCIデバイスを持ちます。CPUは他のソケットのメモリやI/Oデバイスにアクセスできますが、自身の持つメモリやデバイスに対するアクセスと比較して性能に影響があります。
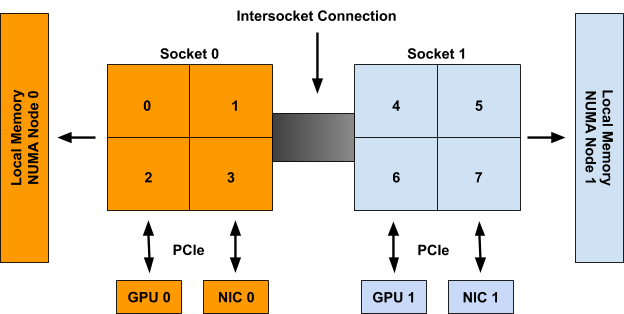
2ソケットでそれぞれ4CPU、2GPU、2NICという2つのNUMAノードを持つシステムの例
(https://kubernetes.io/blog/2020/04/01/kubernetes-1-18-feature-topoloy-manager-beta/から引用)
Kubernetesには、特定のCPUコアの専有(CPU Pinning)を実現するためのCPU ManagerとGPUやSR-IOVといった拡張デバイスの割り当てを実現するためのDevice Managerがあります。しかし、それらはリソースの割り当てを互いに独立して行っているため、NUMAアーキテクチャにおいて要求されたリソースが異なるソケットへ割り当てられ、性能に影響が出る可能性がありました。今後はTopology Managerにより、できる限り同一のNUMAノードに割り当てるといったコンテナのNUMAアウェアなリソースの割り当てが可能になります。
そのほか、1.18時点でのTopology Managerには次のような制約があります。
- Topology Managerが許容するNUMAノードのサイズは最大で8
- Kubernetesスケジューラはトポロジを認識しないため、スケジュールされたあとに実行に失敗する可能性がある
- Topology Managerをサポートするのは現時点でCPU ManagerとDevice Managerのみで、メモリとHugeページは考慮されない
Topology Managerの具体的な使用方法や関連するより詳しい情報は、次のドキュメントを参照してください(※すべて英文サイトです)。
・Kubernetes Topology Manager Moves to Beta - Align Up!
・Control Topology Management Policies on a node
・Control CPU Management Policies on the Node
・Device Plugins
・CPU Manager(KEP)
・Device Manager(KEP)
・Topology Manager(KEP)
Server-side Apply(ベータ)
Server-side Apply(サーバサイドアプライ)は、
おそらくKubernetesを利用する方が最も使用するコマンドであり、リソースを宣言的に定義するために使用する
- Kubernetesオブジェクトの各フィールドが誰またはどのコンポーネントによって定義および変更されたのかが分からず、手順によっては変更が失われるケースがある
- リソースの適用に使用されるKubernetes独自のマージアルゴリズムであるStrategic merge-patch(ストラテジック マージパッチ)がクライアント(kubectl)に実装されていたことで、ライブラリとして使用したい場合にkubectlのGoコードをインポートするか、シェルからkubectlを呼び出す必要がある
- Strategic merge-patchのパッチ形式が様々なバージョンのKubernetes APIサーバとの互換性を維持し続けることや一部の新機能はクライアント側に実装していくことが困難だった
Server-side Applyは、Kubernetesリソースの各フィールドが誰(人間もKubernetesコンポーネントもここでは同等)によって管理されているかを記録し、もし管理者(フィールドマネージャと呼ぶ)以外がフィールドを変更しようとするとコンフリクトとして扱い、forceオプションを使用しない限り変更されません。これにより、他の管理者が管理しているフィールドを誤って変更してしまうことを防ぎます。
1.18でServer-side Applyを試すには、kubectl applyコマンドに明示的に--server-sideオプションを指定する必要があります。このオプションは将来的にはデフォルトになるでしょう。そのほか、関連するオプションとして、フィールドの変更がコンフリクトした場合に強制的に解決する
Server-side Applyにより、これまで以上に安全に宣言的にオブジェクト管理ができるようになります。また、これまで自身で開発したツールで
Server-side Applyに関するより詳しい情報は、次のドキュメントを参照してください。
・Kubernetes 1.18 Feature Server -side Apply Beta 2(英語)
・Apply(KEP)(英語)
・Kubernetes 1.14: Server -side Apply(alpha)
・An example of using dynamic client of k8s.io/client-go(英語)
Ingress APIの改善(GA)
一向にGAを迎えないIngress APIに3つの大きな改善が行われました。
- Ingressパスのマッチ方法を指定できる
pathType フィールドの追加 - どのIngressコントローラを使用するかを指定する
IngressClass リソースの追加 - ホスト名に対するワイルドカードのサポート
(1)の
(2)の
apiVersion: networking.k8s.io/v1beta1
kind: IngressClass
metadata:
name: external-lb
annotations:
ingressclass.kubernetes.io/is-default-class: "true"
spec:
controller: example.com/ingress-controller
parameters:
apiGroup: k8s.example.com/v1alpha
kind: IngressParameters
name: external-lb
(3)のホスト名に対するワイルドカードのサポートは
なお、これらの新しい機能を使用できるかは、使用するIngressコントローラがサポートしているか次第です。そのため、クラスタのバージョンを1.18以上にアップグレードしてもこれらの機能が使えるとは限りません。自身の利用するクラスタがどのIngressコントローラを使用しており、そのコントローラが新しい機能をサポートしているかを確認してください。マネージドKubernetesサービスを使用している場合は、パブリッククラウドが出す変更内容を確認しましょう。自身でクラスタを構築している場合は、クラスタの運用者に確認すると良いでしょう。
最後にIngressはコントローラの実装依存な部分が多く、Kubernetesのなかでは異質なリソースです。今回のパスタイプやホスト名のワイルドカードといった機能もコントローラの実装次第で仕様通りに機能するかは分かりません。今後Ingress APIのGAに向けてコンフォーマンステストの提供が予定されているため、将来的には仕様に定義されている機能については挙動が統一されていくことが期待できます。
Ingress APIに関するより詳しい情報は、次のドキュメントを参照してください。
・Improvements to the Ingress API in Kubernetes 1.18(英語)
・Ingress(KEP)(英語)
【TIP】アルファ、ベータ、GAってなに?
Kubernetesの機能紹介で、よく「この機能はベータです」といった記述があります。Kubernetesでは機能のステージとしてアルファ(Alpha)、ベータ(Beta)、GA(General Availability、安定版)があり、アルファから始まり、ベータを経てGAに至るという流れになっています。
アルファステージの機能は実験的なもので、ベータ昇格時に破壊的変更が入ったり、その後機能自体が削除されることがあるため、基本的に本番では利用しないほうが良いでしょう。デフォルトで無効になっているため、利用するには明示的にフィーチャーゲート(feature-gate*1)で有効にする必要があります。
ベータステージの機能はデフォルトで有効になります。十分にテストを行い、利用しても問題ないレベルと判断されると昇格します。そのあとの昇格で互換性のない変更が入る可能性もありますが、マイグレーションパスが用意されることになっています。このステージの機能を利用されたくない場合は明示的に無効化できます。
GAステージの機能はデフォルトで有効になり、無効化はできません。
今後、Kubernetesのドキュメントでアルファ、ベータ、GAの単語を見かけたら上記を思い出してみてください。より詳細な機能ステージの説明は、次のドキュメントを参照してください。
*1:フィーチャゲートは特定機能を有効/無効にするフラグのことで、各コンポーネントの
kubectl alpha debug(アルファ)
これまで、実行中のPodをデバッグしたいときには
使い方はとても簡単で、次のようにデバッグの対象となるPodとデバッグコンテナで使用するイメージを指定するだけです。この例は、デバッグ対象のPodが
$ kubectl alpha debug nginx -it --image=busybox
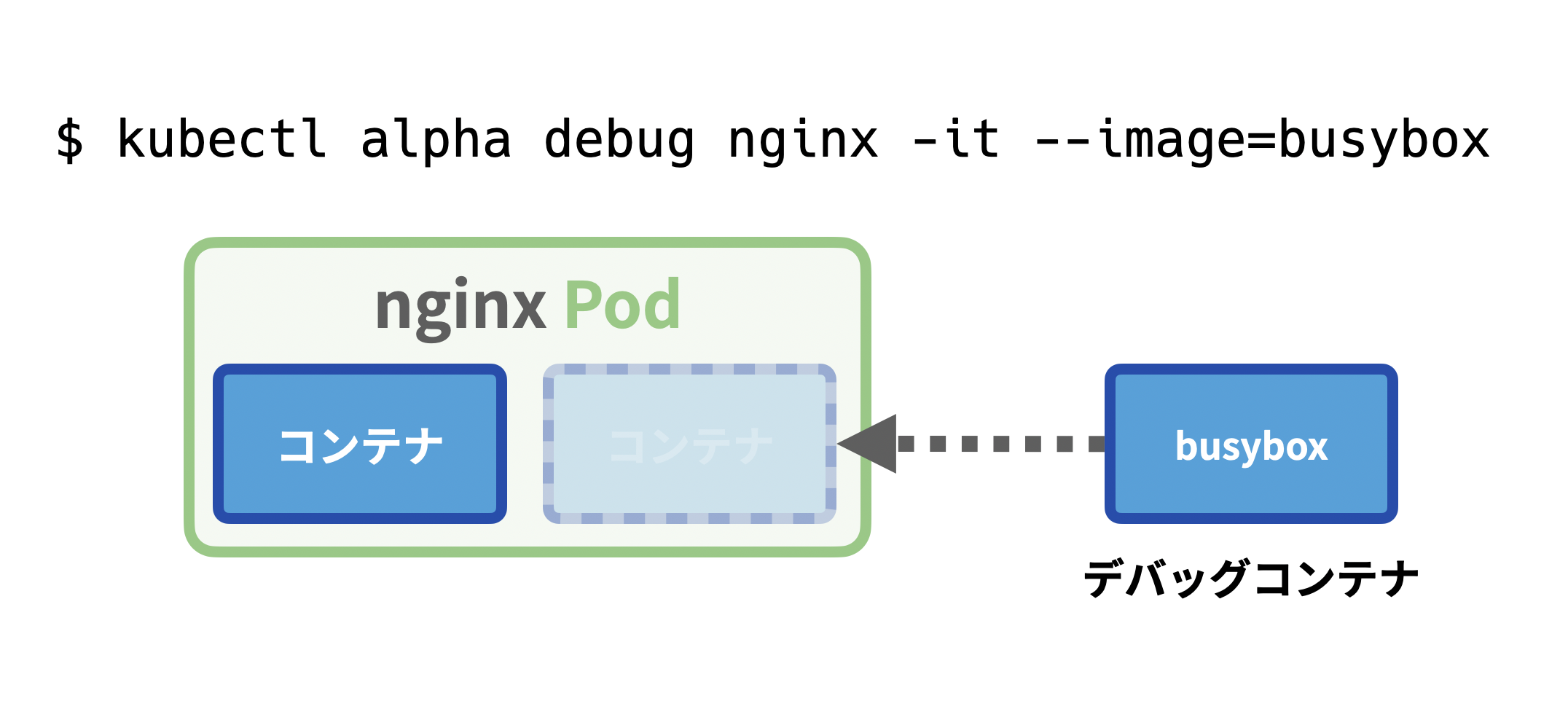
nginx Podにbusyboxをデバッグコンテナとして追加実行する
デバッグコンテナからはアプリケーションコンテナで実行されている
$ kubectl alpha debug nginx -it --image=busybox --target=nginx
ここまでで、デバッグコンテナを使用すれば、あとからサイドカーコンテナを追加するなど「デバッグ用途以外にも便利に使えそうだ」と思った方もいるかもしれません。しかし、Podに対する大きな機能追加は影響が大きくなりすぎる可能性があることから、現時点で次のような制約があります。
- デバッグコンテナをPodの新規作成時から設定しておくことはできない
- デバッグコンテナは再起動されない
-
livenessProbe やreadinessProbe 、lifecycle などの機能が使えない
・Ephemeral Containers(英語)
・kubectl debug(KEP)(英語)
・Ephemeral Containers(KEP)(英語)
・Kubernetes 1.16: Ephemeral Containers(alpha)
・Kubernetes 1.16 アルファ機能を先取り! エフェメラルコンテナ
実際に
・Kubernetes 1.18でkubectl alpha debugを使ってPodをデバッグする
Windows CSIサポート(アルファ)
1.18でWindows向けのCSIプロキシがアルファストレージで提供されました。これにより、WindowsクラスタにおいてCSIドライバが使用できるようになります。
CSI(Container Storage Interface、コンテナストレージインターフェイス)は、Kubernetesのようなコンテナオーケストレータで任意のストレージシステムでのボリュームの作成/削除やアタッチ/デタッチなどの操作を標準化するために策定された仕様です。それまでのKubernetesでは、サードベンダが新しいボリュームプラグインを追加するにはin-tree(Kubernetes本体のコード)で開発する必要があり、プラグインのリリースがKubernetesのリリースサイクルに縛られる、Kubernetes本体のセキュリティの問題を引き起こす可能性があるなどの課題がありました。KubernetesのCSIサポートにより、サードベンダはCSIに準拠したドライバをKubernetesの外で開発し提供することで、独自のリリースサイクルを取れるようになりました。今後、Kubernetes 1.21までに全てのin-treeのボリュームプラグインのCSIへの移行が予定されています。
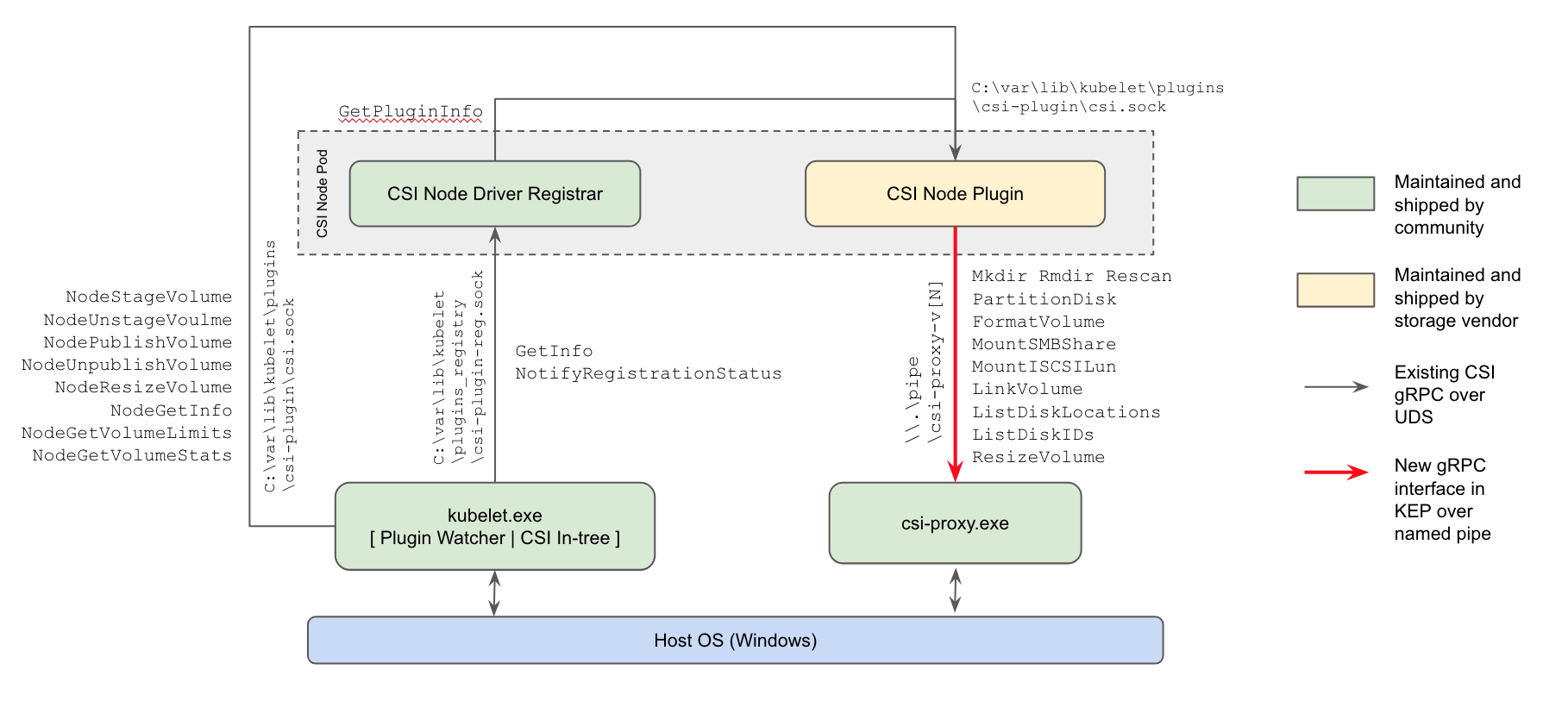
csi-proxy.exeは、すべてのWindowsノード上で実行され、Podで実行されるCSIノードプラグインからgRPCで命令を受け取り代理として特権が必要なストレージの操作を行う(https://kubernetes.io/blog/2020/04/03/kubernetes-1-18-feature-windows-csi-support-alpha/からの引用)
このリリースでは、WindowsクラスタでCSIドライバが使用できるようになりました。KubernetesのCSIドライバはコントローラプラグインとノードプラグインの2つから成っています。コントローラプラグインはKubernetes APIや外部のストレージシステムを操作するため、Windowsクラスタでも問題なく使用できていました。一方でノードプラグインは一般に全てのノードにDaemonSetで実行され、ボリュームのフォーマットやマウント/アンマウントやフォーマットなどを行うため、ホストに直接アクセスし、特権コンテナとして実行させる必要があります。しかし、現時点でWindowsは特権コンテナの実行をサポートしていないため、ノードプラグインが機能しませんでした。そこで、Windowsノードのホスト上で直接実行され、ノードプラグインに代わってストレージの操作を実行するCSIプロキシが開発されました。これにより、CSIプロキシがホストを操作することでノードプラグインが特権コンテナとして実行される必要がなくなり、CSIドライバがWindowsクラスタで使用できるようになります。
CSIプロキシは1.18時点でアルファです。AzureとGoogle Cloud Platformのクラウドプロバイダがアルファでサポートしています。今後使用が見込まれる方は検証環境で使用し、問題があればフィードバックするなどしましょう。より詳しいCSIプロキシに関する情報は、次のドキュメントを参照してください。
・Introducing Windows CSI support alpha for Kubernetes(英語)
・kubernetes-csi/csi-proxy: CSI Proxy utility to enable CSI Plugins on Windows(英語)
・Introduction - Kubernetes CSI Developer Documentation(英語)
・Support for CSI Plugins on Windows Nodes(KEP)(英語)
・KubernetesにおけるContainer Storage Interface(CSI)の概要と検証
筆者の注目機能
ここからは、筆者の1.18注目機能として、HorizontalPodAutoscalerの
autoscaling/v2beta2 HorizontalPodAutoscalerの
spec.behaviorフィールドの追加
autoscaling/v2beta2のHorizontalPodAutoscalerに
これまではスケールダウンの速度をクラスタレベルで設定できるだけのチューニングしか行なえませんでした。この機能が追加されたことで、アプリケーションの性質により個々にスケールアップ/スケールダウンの設定をチューニングできます。
なお、この機能は
$ kubectl explain hpa.spec.behavior --api-version=autoscaling/v2beta2 | head
KIND: HorizontalPodAutoscaler
VERSION: autoscaling/v2beta2
RESOURCE: behavior この機能に関する詳細は、次のドキュメントを参照してください(いずれも英語)。
・Horizontal Pod Autoscaler
・Configurable scale up/down velocity for HPA(KEP)
NodeLocal DNSCache(GA)
NodeLocal DNSCache(ノードローカルDNSキャッシュ)は、DNSのキャッシュサーバをDaemonSetとして各ノード上で実行させることで、クラスタDNSのパフォーマンスと信頼性を向上するアドオンです。この機能は1.13ではアルファ、1.15ではベータで提供されていましたが、このリリースでGAに昇格しました。
KubernetesはServiceによるサービスディスカバリなどのために、クラスタのなかでDNSサーバ(CoreDNS)を実行しています。このDNSサーバのデプロイにDeploymentを使用していることで、他のノード上で実行されているDNSサーバにクエリすることとなり、パフォーマンスに影響があるケースがありました。またDNSパケットの送信にUDPを使用していることで、conntrackテーブルが溢れることもありました。
NodeLocal DNSCacheを使用するとPodは自身が実行されているノード上にあるDNSキャッシュエージェントにクエリできるようになり、パフォーマンスが向上します。また、DNSキャッシュエージェントからメインのDNSサーバへの問い合わせにはTCPが使用されます。TCPのconntrackエントリはUDPとは異なりタイムアウトを待つ必要がなく接続が閉じられると削除できるため、conntrackテーブルが溢れにくくなります。
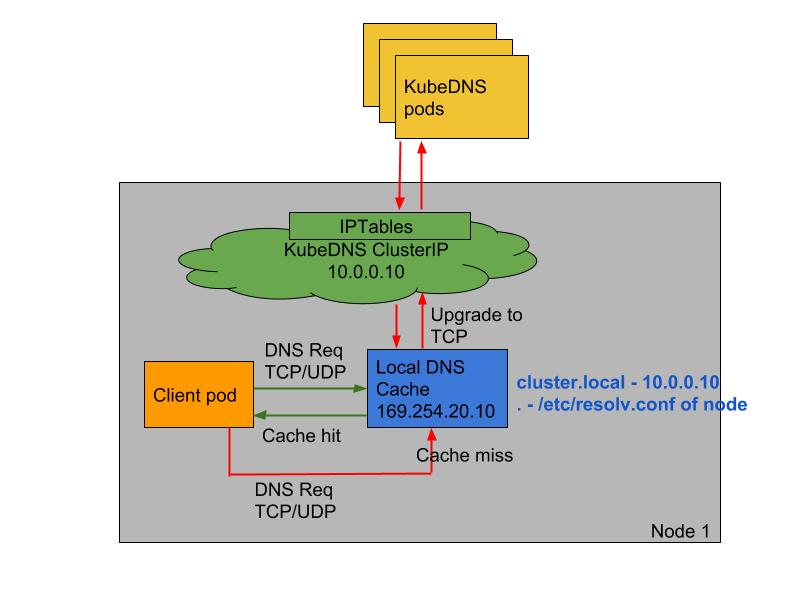
NodeLocal DNSCacheのクエリパス
(https://kubernetes.io/docs/tasks/administer-cluster/nodelocaldns/からの引用)
最後にDNSキャッシュエージェントのキャッシュとネガティブキャッシュのTTLは、デフォルトでそれぞれ30秒と5秒に設定されています。この値は必要であればクラスタによりチューニングできます。
NodeLocal DNSCacheに関する詳細は、次のドキュメントを参照してください(すべて英語)。
・Using NodeLocal DNSCache in Kubernetes clusters
・kubernetes/cluster/addons/dns/nodelocaldns
・NodeLocal DNSCache(KEP)
Pod StartupProbe(ベータ)
Pod の新しいプローブであるStartupProbe(スタートアッププローブ)がベータステージに昇格し、デフォルトで使用できるようになりました。
PodにはこれまでLivenessProbe(ライブネスプローブ)とReadinessProbe(レディネスプローブ)の2つがありました。LivenessProbeはコンテナの死活監視を行い、このプローブが失敗するとrestartPolicy(リスタートポリシ)によっては対象のコンテナが再起動されます。ReadinessProbeはコンテナがアクセスを受ける準備ができているかを確認します。このプローブが失敗するとKubernetes Serviceのルーティング対象から除かれ、アクセスされなくなります。

LivenessProbe と ReadinessProbe
StartupProbeは、コンテナの起動時のみに使用される新しいプローブです。これまで起動にある程度時間がかかるコンテナではLivenessProbeの設定調整が難しく、もし

StarttupProbeに成功すると他の2つのプローブが開始される
次の例では、StartupProbe の
startupProbe:
httpGet:
path: /healthz
port: 8080
failureThreshold: 30
periodSeconds: 10
livenessProbe:
httpGet:
path: /healthz
port: 8080
failureThreshold: 1
periodSeconds: 10
StartupProbeが失敗した場合は、LivenessProbeと同様にコンテナが強制終了され、restartPolicyの設定によってはコンテナが再起動されます。
細かい機能ですが、これまでLivenessProbeの説明では必ずと言っていいほど
StartupProbeのより詳しい情報は、次のドキュメントを参照してください(いずれも英語)。
・Configure Liveness, Readiness and Startup Probes
・StartupProbe(KEP)
Pod StartupProbeを使ってみよう
ここからは、実際にPod StartupProbeの挙動を確認してみます。手元で試してみたい方はMinikubeやKindで1.18のクラスタをご用意ください。
$ kubectl version
Client Version: version.Info{Major:"1", Minor:"18", GitVersion:"v1.18.2", GitCommit:"52c56ce7a8272c798dbc29846288d7cd9fbae032", GitTreeState:"clean", BuildDate:"2020-04-16T11:56:40Z", GoVersion:"go1.13.9", Compiler:"gc", Platform:"darwin/amd64"}
Server Version: version.Info{Major:"1", Minor:"18", GitVersion:"v1.18.2", GitCommit:"52c56ce7a8272c798dbc29846288d7cd9fbae032", GitTreeState:"clean", BuildDate:"2020-04-16T11:48:36Z", GoVersion:"go1.13.9", Compiler:"gc", Platform:"linux/amd64"}
例えば、ここで次のようなDeploymentがあるとします。
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp
spec:
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- name: busybox
image: busybox
command:
- /bin/sh
args:
- -c
- sleep 15 && touch /tmp/healthy && tail -f /dev/null
livenessProbe:
exec:
command:
- test
- -f
- /tmp/healthy
failureThreshold: 1
periodSeconds: 5
このDeploymentから作成されるPodsは、健全と判断されるまでに15秒かかるようになっています。また、LivenessProbeの設定は
これを
$ kubectl apply -f myapp.yaml作成されたPodを見ると再起動を繰り返していき(
$ kubectl get po -l app=myapp -w
NAME READY STATUS RESTARTS AGE
myapp-d7f798f44-nzpvg 0/1 CrashLoopBackOff 4 3m37s
これは、このPodが健全になるまでに15秒かかることで、LivenessProbeの確認が常に失敗する状況になってしまっているためです。このような状況では、これまで
そこでStartupProbeの出番です。ここでは
args:
- -c
- sleep 15; touch /tmp/healthy; tail -f /dev/null
+ startupProbe:
+ exec:
+ command:
+ - test
+ - -f
+ - /tmp/healthy
+ failureThreshold: 30
+ periodSeconds: 3
livenessProbe:
exec:
command:
変更後のマニフェストを再度クラスタに適用します。
$ kubectl apply -f myapp.yaml作成されたPodを見ると、今度は再起動されずに正常に実行されていることが確認できます。
$ kubectl get po -l app=myapp
NAME READY STATUS RESTARTS AGE
myapp-77dd84657c-vp7x7 1/1 Running 0 2m22s
これは、Podが起動するまでに3秒間隔で30回まで失敗できるStartupProbeが、ここでは4回目以降のプローブの実行で成功し、そこからLivenessProbeの実行が開始されるためです。
以上のように、これまでの起動までに時間がかかるPodにはLivenessProbeの
【TIP】新マイナーバージョン、どのパッチバージョンから使うべき?
Kubernetesのマイナーバージョンがリリースされたら、どのバージョンから使うべきでしょうか。少なくとも最初のバージョン(1.18の場合は1.18.0)は避けることをお勧めします。
例えば、1.18.0では
この2つのバグはKubernetes 1.18.1で修正されています。
*2:https://github.com/kubernetes/kubectl/issues/845
*3:https://github.com/kubernetes/kubectl/issues/852
おわりに
ここでは、Kubernetes 1.18の注目機能を紹介しました。今後役に立ちそうな機能はあったでしょうか。筆者のイチオシは
- この記事のキーワード
バックナンバー
この記事の筆者

Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
