Observability Conference 2022から、イベントのスポンサーでもあるSplunkのエンジニアがOpenTelemetryの入門編として解説するセッションを紹介する。セッションを行ったのは、Splunk Services Japan合同会社のシニアセールスエンジニアである大谷和紀氏だ。
大谷氏はオブザーバビリティの基本として3つの柱、ログ、メトリクス、トレーシングが必要であることなどシステム観測の基本を説明した後、観測自体はモニタリングという名前で存在していたが、クラウドの時代に合わせてオブザーバビリティに変化してきたと説明した。そして特に何かおかしい箇所を見つけるためのモニタリングではなく、予期しない事象を見つけ、なぜそれが起こったのかを解明するためのツールとしてオブザーバビリティが隆興してきたことを説明した。
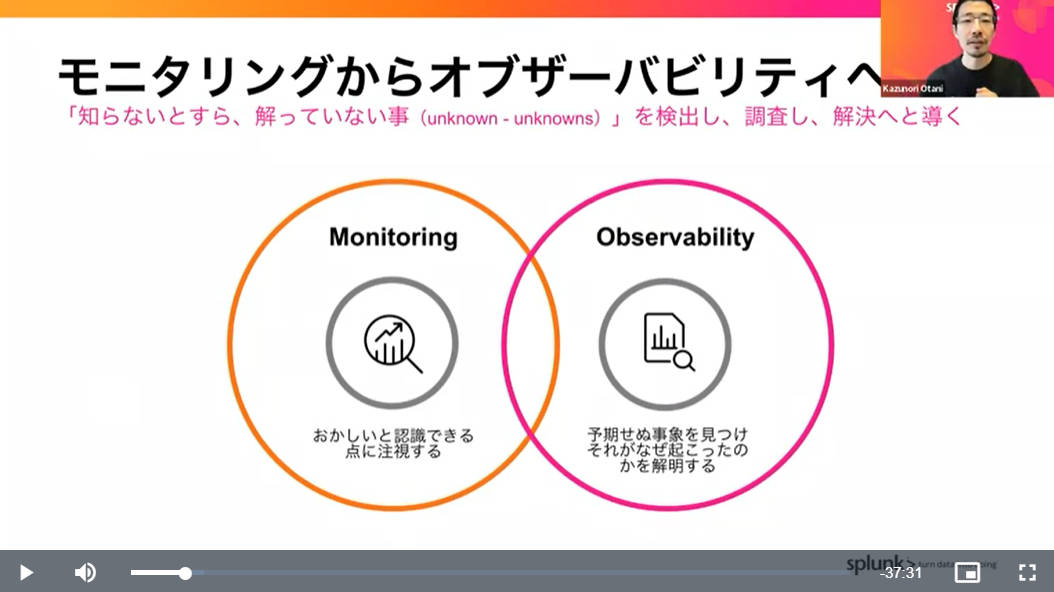
予期せぬ事象を解明するためのツールとしてのオブザーバビリティ
メトリクスは何が起きているのか知るため、ログはどんな問題が起きているのかを知るため、そしてトレーシングはどこで問題が起きているのかを知るために必要であるとして、それぞれの位置付けを解説した。

メトリクス、ログ、トレーシングの役割を説明
特にトレーシングについては、複数のプロセスが依存関係の構造を可視化することがポイントであると言える。多数の小さなプロセスで構成されるクラウドネイティブなシステムにおいては、依存関係や起動/終了などの親子関係などを時系列に整理して理解しておくことは重要だろう。
次のスライドでは、このセッションがスポンサーセッションであることから自社製品の宣伝ということでSplunk Observabilityというクラウドサービスを紹介した。リアルタイム性、サンプリングを行わずにすべてのデータを収集することで漏れのない分析が可能であること、OpenTelemetryをベースにしていることなどを説明した。
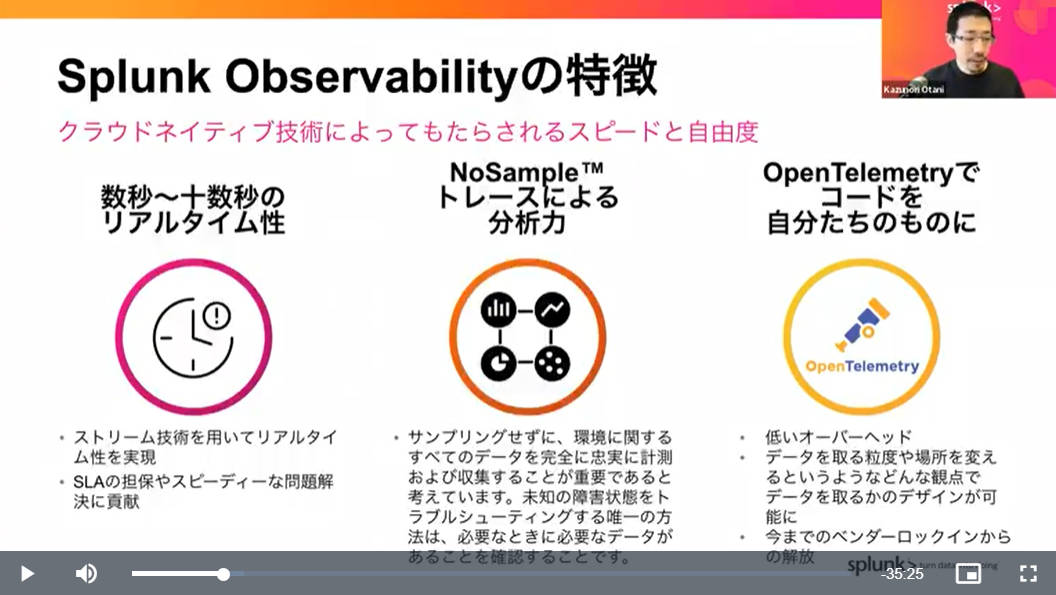
Splunkの商用オブザーバビリティサービスを紹介
ここから今回の本題であるOpenTelemetryについて解説する内容となった。
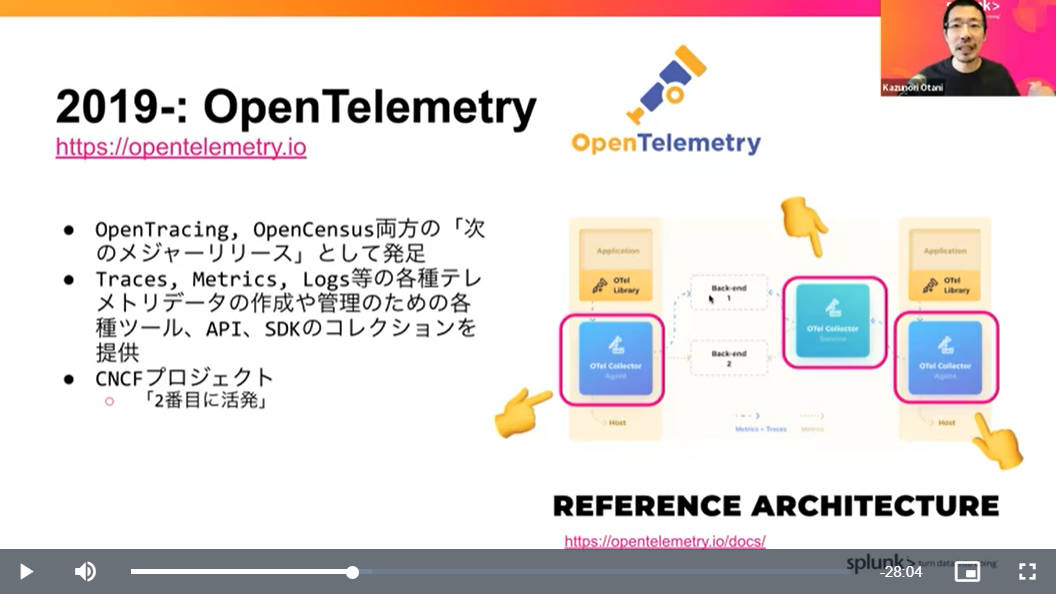
OpenTelemetryの概要。CNCFで2番目に活発なプロジェクトであるという
OpenMetricsとOpenCensusがマージされたOpenTelemetryについて、メトリクス、ログ、トレーシングを包括的に扱うためのプラットフォームであることを解説。Cloud Native Computing Foundation(CNCF)において、開発などの活発さが全体の2番目のプロジェクトであることなどを特徴として挙げた。

OpenCensusの対応プログラミング言語の一覧
このスライドでは、トレーシングを行う際にどのプログラミング言語からどのバックエンドにデータを送信できるのか? をまとめたものだ。CやGo、JavaなどからAWS、Google Cloud、Datadog、Jaeger、Zipkinなどのバックエンドにトレーシングデータが送信できるかなどを一覧できる。
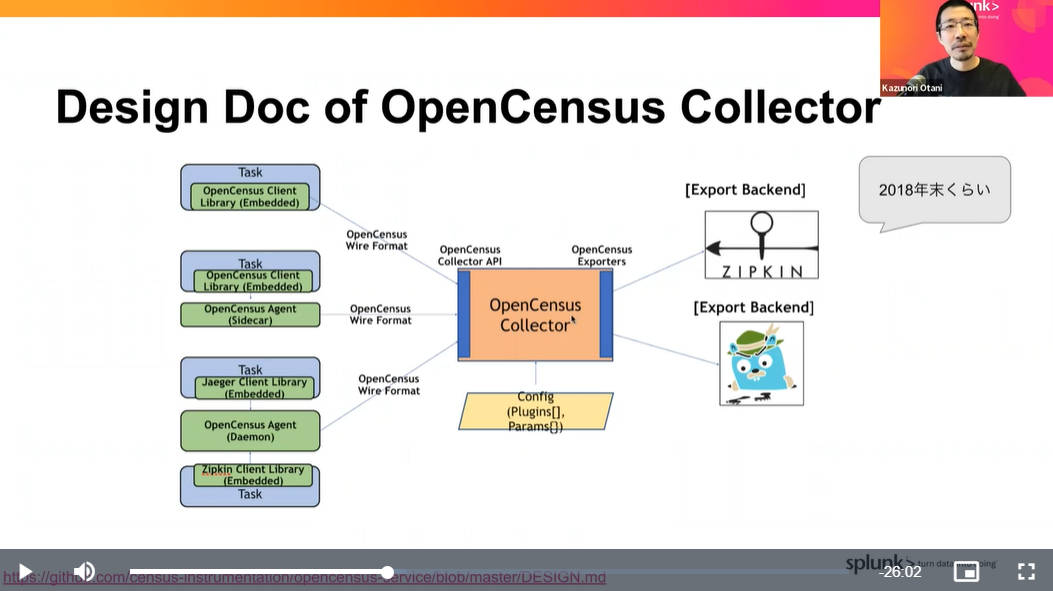
OpenCensusのデータ収集の仕組みを解説
この図表はOpenCensusの公式GitHubからの引用だ。以下がそのリンクとなる。
参考:https://github.com/census-instrumentation/opencensus-service/blob/master/DESIGN.md
各アプリケーションからトレーシングデータを収集するためには、アプリケーション自身がバックエンドとなるPrometheusやJaeger、Zipkinなどにデータを送るか、Collectorと呼ばれるエージェントを介してデータを送信する必要がある。そのどちらの方法を選択するか? についてはケースバイケースだろうが、Collectorを使う場合のメリットについても解説を行っている。

OpenCensus Collectorを使うメリット
ここで紹介された、バックエンドの切り替えを実施する際にアプリケーションを変更する必要がないというのは大きなメリットだろう。またアプリケーションが使う認証鍵の管理についても、個々のアプリケーションごとに管理を行う煩雑さを考えれば、Collector側に集中させることでその部分の管理かを切り離せることもメリットとして解説している。
データの追加については、実行しているホストに関するデータを追加することで、KubernetesのようにどこでPodが実行されるのかを制御しづらい場合にも確実にメトリクスやトレーシングデータを捕捉できるメリットがあるという。またパフォーマンスという意味では、全データを取らずにサンプリングする設定によって性能に負担を掛けずに計測が行えると説明した。Goで書かれているOpenTelemetry Collectorはそれ自体のProfileを取れたり、ログやメトリクスを出力できたりするように実装されているとして、データ測定のためのプログラムとしてリファレンスモデルとなるように開発されている点についてもメリットとして紹介された。
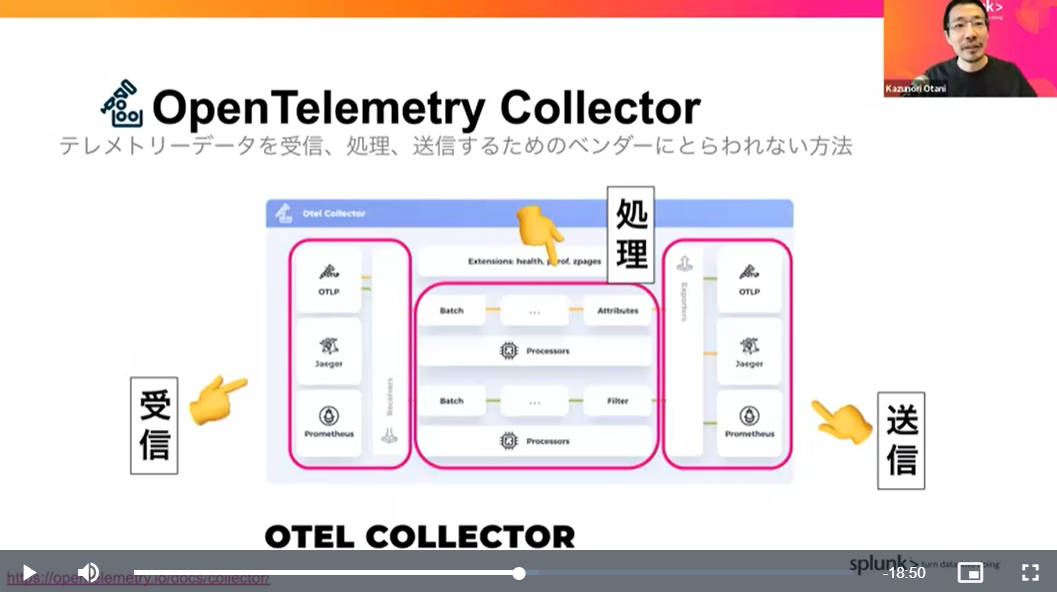
OpenTelemetry Collectorの概要
ここでOpenTelemetry Collectorの概要を紹介。テレメトリーデータを処理する際に、ベンダーロックインされない形で実装ができるという部分を強調している。
ここからはOpenTelemetryのGitHubで公開されているJavaScriptベースのサンプルアプリケーションを使って、トレーシングデータの送信、Collectorでの処理、バックエンド(今回はSplunk Observability)への送信などをデモを、交えて紹介した。
大谷氏が使ったサンプルアプリケーションは以下から入手できる。
参考:https://github.com/open-telemetry/opentelemetry-js
ターミナルへログを出しながらデモを実施
デモの設定はこのスライドで解説されているが、JavaScriptのアプリからバッチで実行されるCollector内部のパイプラインに従ってログの形で出力を行うというものだ。

デモの設定を紹介
単にログとして標準出力に送るだけではなく、Splunkが提供するクラウドサービス、Splunk Observabilityにデータを送るという設定変更も実施して、実際にダッシュボードでクラウド側にデータが送信されている部分を確認した。

クラウドサービス側にデータを送るように設定を変更
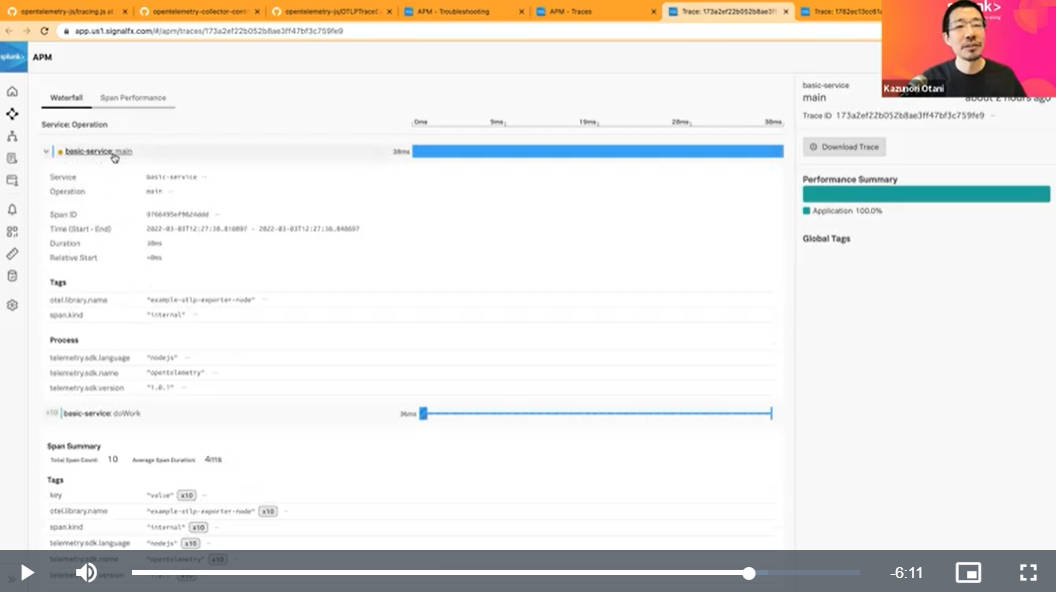
Splunk Observabilityのダッシュボードで確認
Collcetorの紹介でも解説されたデータを追加するという部分については、AWSのインスタンスの情報を追加するデモを実施。
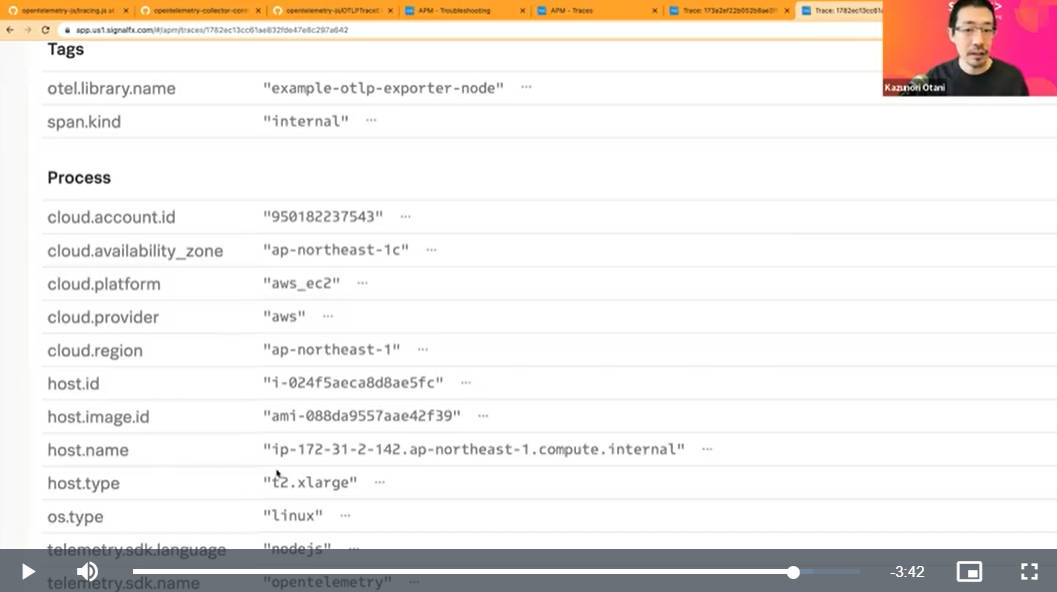
AWS EC2のインスタンスに関するデータが追加された
この部分はコアの機能ではなくContribという形で、ベンダーなどが提供する連携部分のコードを使っているということになる。
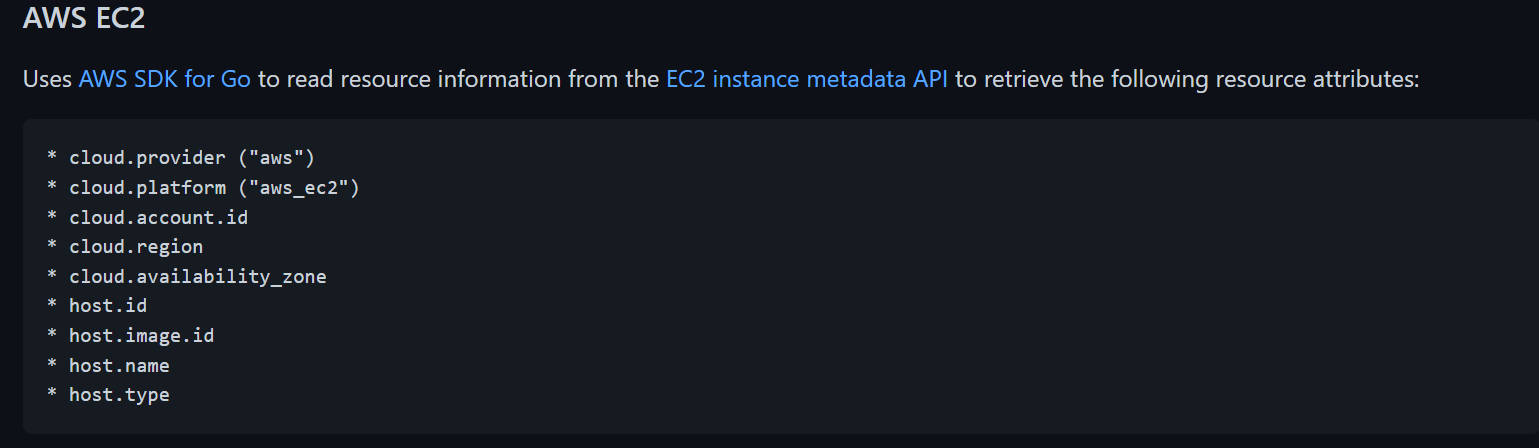
AWS SDK for Goを使ってEC2のデータを取得できる
詳細は以下を参照されたい。
最後にOpenTelemetryの現状が紹介された。トレーシングについてはGAということで安定状態にはなっているが、メトリクスについては機能の確定が行われているだけでコード自体の安定化はこれから、さらログについてはまだベータにも到達していないということがわかる。ObservIQが開発していたFluentd/Fluentbitを代替するログエージェントであるStanzaを統合するまでには、まだ時間がかかりそうだ。
オブザーバビリティデータの管理をどうするのか? については、毎日大量に発生するデータをオンプレミスで処理するのか、安価で使い勝手が良いパブリッククラウドで処理するのか、というのは悩ましい問題だろう。データ自体に個人情報などが含まれる場合なども考慮せざるを得ないし、データをマスクする手間も必要だ。それらのコストを勘案すると、Splunkが提供するオブザーバビリティに特化したパブリッククラウドサービスは検討に値する選択肢かもしれない。Splunk Observabilityの詳細に関しては以下を参照されたい。
- この記事のキーワード
バックナンバー
この記事の筆者

筆者の人気記事
SASEのCato Networks、CEOによるセミナーとインタビューを紹介
2020年4月16日 6:00
Rustのエコシステムの拡がりを感じるデスクトップアプリのためのツールキットTauriを紹介
2022年12月16日 6:00
Zabbix式オープンソースの秘密に迫る
1月31日 6:00
WebAssemblyとRustが作るサーバーレスの未来
2020年4月21日 6:00
エンタープライズLinuxを目指すSUSE、Red Hatとの違いを強調
2015年2月3日 19:00
RustとWASMで開発されKubernetesで実装されたデータストリームシステムFluvioを紹介
2022年12月23日 6:00
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
