クラウドの力を引き出す分散データベース

アーキテクチャの概要
Cassandraの機能のうち、レプリケーション・データをどのノードに配置するのかを決定する方法、Gossipアルゴリズムによる情報の取得方法、データの読み書き方法について紹介します。
レプリケーション・データの配置方法
最初のレプリカは、キーを基に計算されたレンジ(範囲)ごとに、それぞれのレンジを担当するノードに配置されます。残りのレプリカは、指定されたレプリケーション方法に従って分散されます。
Cassandraでは、ネットワーク構成や要件に合わせて柔軟に対応できるように、RackUnaware、RackAware、DatacenterShardの3つのレプリケーション方法を用意しています。
- RackUnaware
- もっとも単純なレプリケーション方法です。名前の通り、データ・センターやラックの位置といった場所を一切意識することなく、近隣のノードに配置します。
|
|
| 図2: RackUnaware |
- RackAware
-
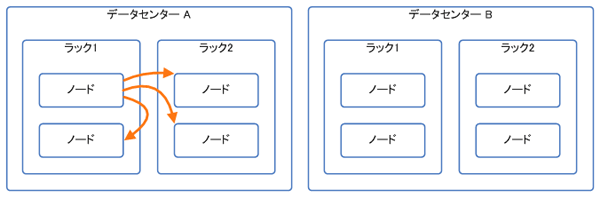
Cassandraクラスタが複数のデータ・センターにまたがって収容されている場合に使用されます。
この方法では、2番目のレプリカを、最初のノードとは異なるデータ・センターに配置します。続く3番目以降のレプリカは、同一データ・センター内の異なるラックに配置します(図3)。
ラックやデータ・センターの判別としては、図4に示した3種類の方法が用意されています。
|
|
| 図3: RackAware |

|
|
| 図4: ラック/データ・センターの判別方法 |

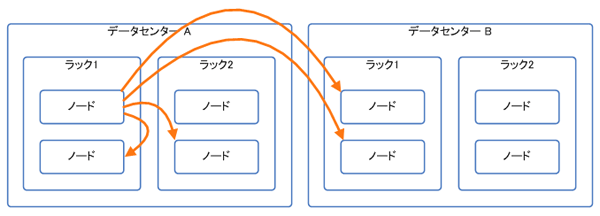
- DatacenterShard
- 基本的にはRackAwareと同じ方法ですが、RackAwareよりも均等にデータを配置します(図5)。ラック/データ・センターの判別方法も、RackAwareと同じです。
|
|
| 図5: DatacenterShard |
Gossipアルゴリズムによる情報の取得
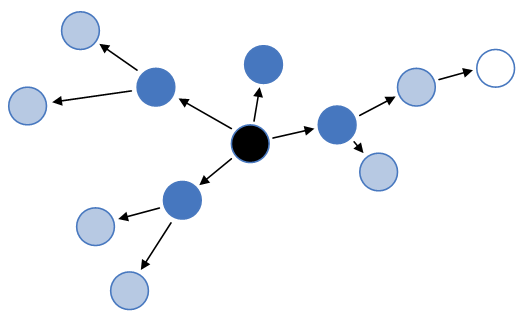
Gossipアルゴリズムは、ノード間の情報を、近隣のノードから徐々に伝播させていきます。これにより、クラスタ内のすべてのノードが個々のノードの状態を把握できるようにします。
Cassandraでは、このアルゴリズムを用いて結果整合性を確保しています。世代とバージョンを基にデータの鮮度を判断し、自ノードに保存しているデータよりも新しいデータがどこに存在しているかを、近隣のノードを経由して徐々に伝播させて確認、取得します。
|
|
| 図6: Gossipアルゴリズムによる情報の取得 |
このアルゴリズムを用いると、情報が徐々に伝播していくため、ノードが増えた場合でもトラフィック量が大幅に増えることはありません。しかし、全ノードに情報が反映されるまでに時間がかかる場合があります。
データの読み書き
クライアントから入力されたデータは、メモリー上のMemtable、ディスク上のCommitLog、SSTableに保存されます。
データの書き込み
書き込みプロセスですが、最初にCommitLogに書き込み、その後にメモリー上のMemtableに保存され、Memtableが一杯になったら、非同期でSSTableへの書き込み(Flushing)を行う、というプロセスになっています。
|
|
| 図7: データの書き込み処理 |
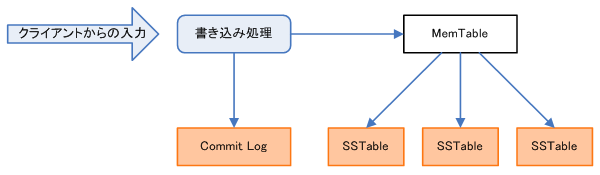
Flushingは自動で行われますが、バックアップ・データの取得時などに手動で実行することもできます。
データの読み込み
データを保持しているノードからのデータの読み込みは、Memtable、SStableの両方から行われます。
|
|
| 図8: データの読み込み処理 |
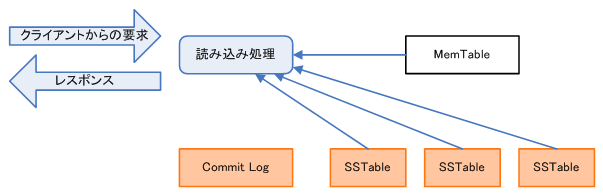
読み込みは、MemtableとSSTableの両方から必要なデータを探すことから、若干速度が遅くなります。この対策として、BloomFilterやキャッシュを使って読み込み速度を向上させる仕組みを用意しています。