次世代CUDAアーキテクチャ"Fermi"の登場
次世代CUDAアーキテクチャ"Fermi"の登場
|
|
| 図3: CUDA向けGPUはFermi世代に移行(クリックで拡大) |

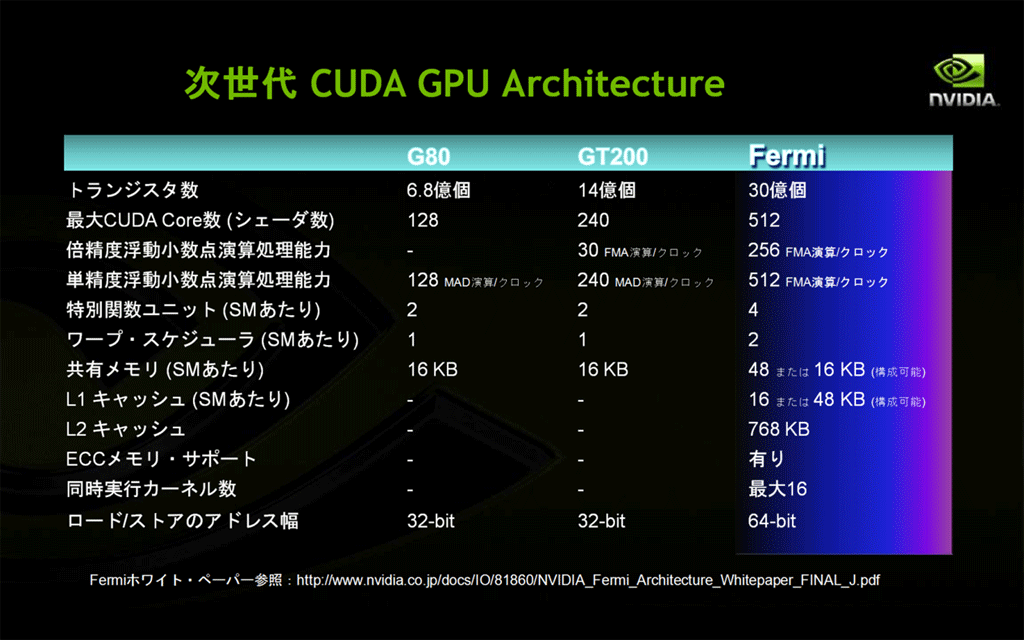
NVIDIAのGPUとして最初に倍精度浮動小数点演算機能をサポートしたのは、GT200世代のGPUです。HPC分野では不可欠だったこの機能をサポートしたことが、GPUコンピューティングが本格的に研究・開発分野で利用されはじめるきっかけとなりました。
処理能力としては、カード製品の「C1060」の場合で77.8GFLOPSです。CPUとの比較では十分な数字でしたが、C1060自身の単精度性能である933GFLOPSと比べると8%程度に過ぎません。このため、より高性能を求める声が徐々に出始めました。
GPUの利用が広がるにつれて需要が大きくなってきた、もう1つの改善要求は、ECCメモリー機能(誤り検出・訂正機能)による信頼性の向上です。この機能は、HPCやデータ・センター、ミッション・クリティカルなビジネスなど、高い信頼性が求められる使用目的に耐えるために必要です。
これら2つの大きな要請にこたえ、GPUコンピューティングのさらなる高機能、高性能化、および使いやすさの向上を満たすために考案されたのが、次世代CUDAアーキテクチャ"Fermi" でした。
とはいっても、Fermiは、GT200の単なる後継というわけではありません。
これまでのGPUがグラフィックス処理の高速化や効率化を設計の出発点としていたのに対して、Fermiアーキテクチャは、GPUの役割や目的、持つべき能力を根底から考え直すことによって、新たに生まれたものです。
したがって、「本業はグラフィックスでコンピューティングは副業」というニュアンスは完全になくなりました。「どちらも本業」、言い換えれば「グラフィックス処理にも適したハイ・パフォーマンス並列プロセッサ」となりました。
|
|
| 図4: 初期のG80からFermiに至るCUDA GPUの進化(クリックで拡大) |
アーキテクチャとしての"Fermi"は、2009年9月に米国サンノゼで開催されたNVIDIA GPU Technology Conferenceの中で発表されました。実際のGPUコンピューティング用の製品としては、カード・タイプの「Tesla C2050」が2010年5月に出荷されました。1Uサーバー・タイプ(4GPU)の「S2050」や、OEM供給によるサーバー組み込みタイプの「M2050」が、間もなく出荷される予定です。これらのGPUは、すべて448コアとGDDR5メモリー3GBを実装しています。
|
|
| 図5: Fermi世代GPU製品「Tesla T20」のラインアップ(クリックで拡大) |

Fermiアーキテクチャの概要
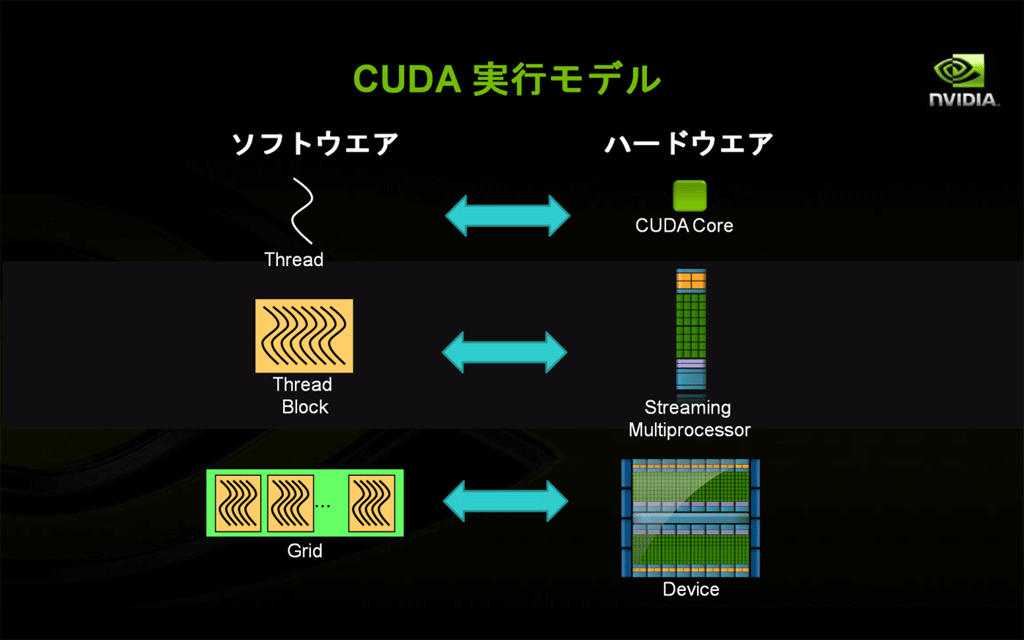
Fermiの概要を説明する前に、CUDAプログラミングの基本概念となる言葉の整理を兼ねて、CUDA実行モデルにおけるソフトウエアとハードウエアの関係について簡単に触れておきます。
CUDAプログラミングでは、並列処理を効率よく行うために、同時に多数のスレッド(Thread)を実行させる必要があります。1つのスレッドは、GPUのハードウエア上の1つのCUDAコアに対応し、その上で実行されます。CUDAコアは、OpenGLやDirectXなどのグラフィックス処理に利用される場合は以前の名称であるシェーダ(あるいは統合シェーダ)と呼ばれますが、実体は同じものです。
同様に、スレッドの集まりであるブロック(Block)はストリーミング・マルチプロセッサ(SM)に対応します。プログラムで定義されたブロックの数に応じて、使用されるストリーミング・マルチプロセッサの数が決まります。
さらに、ブロックの集合体であるグリッド(Grid)は、デバイス(Device)に対応しています。
|
|
| 図6: CUDA実行モデル(スレッドとコアの対応)(クリックで拡大) |
では、Fermiアーキテクチャの概要と特長について説明します。
|
|
| 図7: Fermiアーキテクチャの概要(クリックで拡大) |

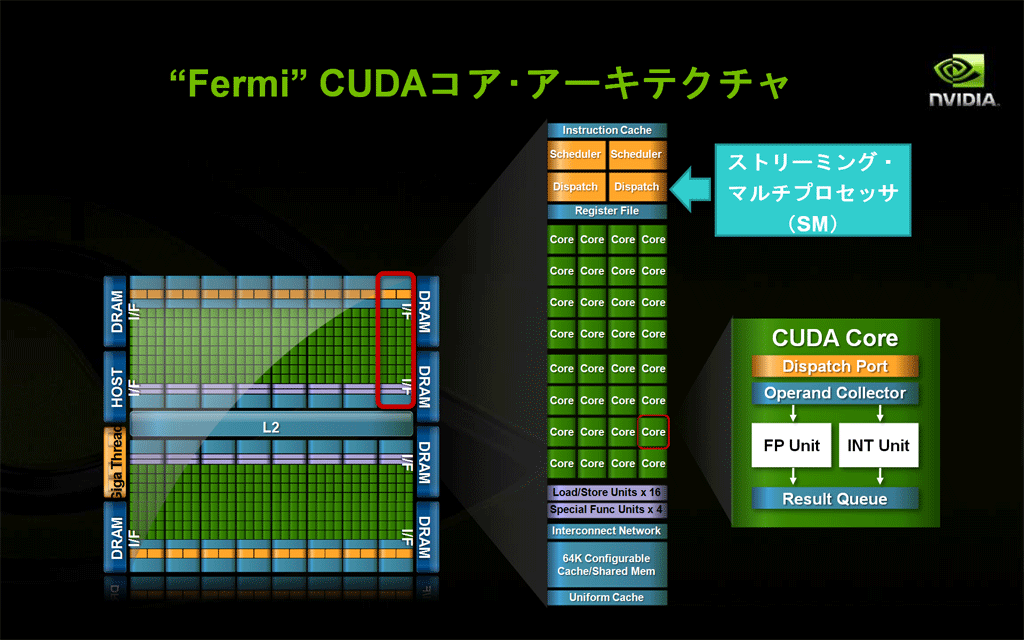
- 第3世代のストリーミング・マルチプロセッサ(SM)
- SMあたり32個のCUDAコアを搭載し、スレッドを並列処理する効率を上げています(GT200の4倍)。
- 倍精度浮動小数点演算への対応能力が大幅に向上し、HPC分野や金融業界など高精度の計算が必要となる分野への適用範囲が広がりました(GT200の6倍以上)。
- 32スレッド(1ワープ)を1クロックあたり2つスケジューリングしてディスパッチできる、デュアル・ワープ・スケジューラにより、並列処理の効率化がさらに進みました。
- トータル64KBのオンチップRAMが用意され、共有メモリーとL1キャッシュに分割して構成できるようになりました(どちらか一方が16KBで、他方が48KBになります。GT200の場合は、共有メモリーが16KBで、L1キャッシュはありませんでした)。
- GPUとして初めてECCメモリー機能(エラー検出・訂正機能)をサポートしました(ECC機能稼働時は、グラフィックス・メモリーの一部がECCの計算に使用されるため、グラフィックス・メモリーの利用可能サイズは10%強程度減少します)。
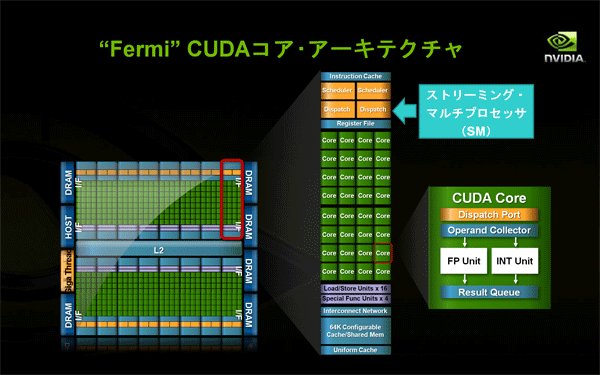
図8: Fermi世代ストリーミング・マルチプロセッサの構成(クリックで拡大) - NVIDIA GigaThreadデータ転送エンジン
- アプリケーション・コンテキストの切り替え速度が10倍に向上しました。
- 2つのDMA転送エンジンにより、パイプライン処理が可能になりました。DMA転送エンジンの一方は、CPUからGPUへの計算用データのDMA転送を受け持ちます。もう一方は、計算終了後に計算結果をGPUからCPUにDMA転送するために使います。

図9: CPU-GPU間のデータ転送エンジンの仕組み(クリックで拡大) - NVIDIA GigaThreadスケジューラ
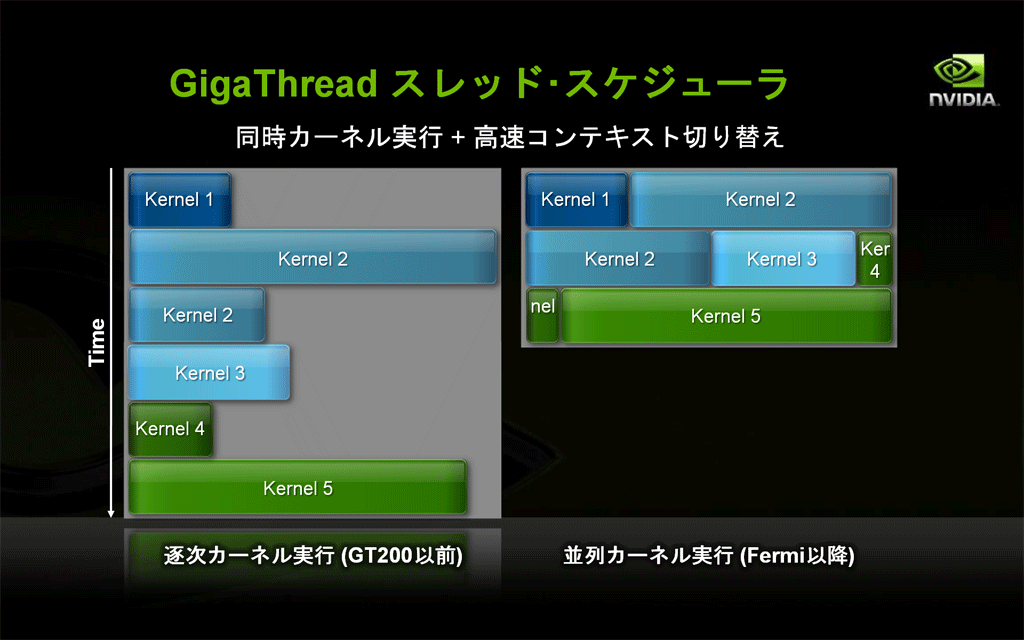
- GT200世代までは、1つのカーネル(GPUサブルーチン)がGPUのすべてのコアを占有していました。このため、スレッド数が実際のコア数より少ない場合は、アイドル状態のコアが存在してしまいました。Fermi世代からは、スレッド・スケジューラによって、複数カーネルの同時実行が可能になりました。
- スレッド・ブロックの実行順位最適化が自動で行われます。
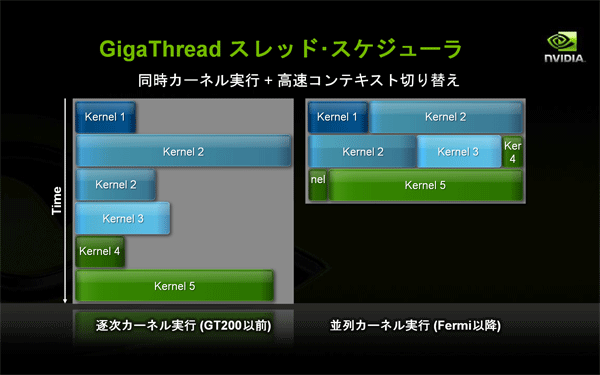
図10: すべてのコアを使って並列にカーネルを実行する(クリックで拡大) - 改良されたメモリー・サブシステム
- L1キャッシュと統合L2キャッシュからなるNVIDIA Parallel DataCacheが新たに登場しました。
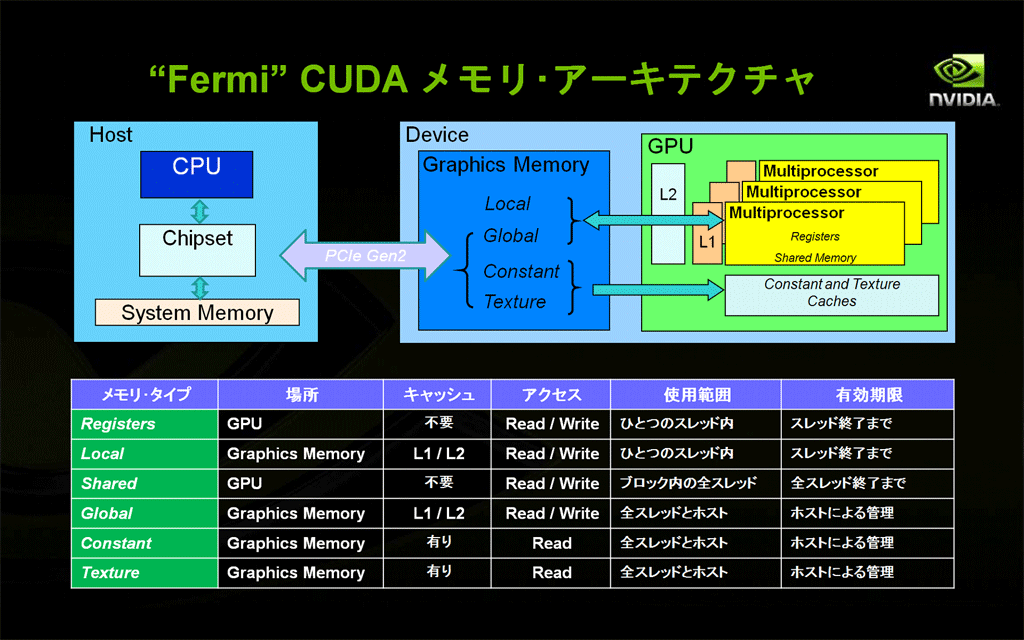
- オフチップ・メモリー(グラフィックス・メモリー)へのアクセス時間は、クロック数にして数百クロック以上必要です。このアクセス時間を高速化するため、GT200まではキャッシュしていなかったローカル・メモリーやグローバル・メモリーがL1/L2キャッシュでカバーされるようになりました。以前から専用キャッシュを持つコンスタント・メモリーやテクスチャ・メモリーを含め、オフチップ・メモリー全体がキャッシュ可能になりました。
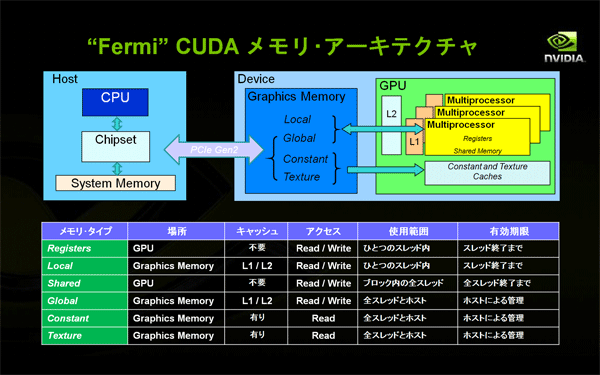
図11: CUDAにおけるGPUのメモリー制御(クリックで拡大) - IEEE 754-2008準拠のFMA演算
- コンピュータ・グラフィックスや線形代数、科学的計算では、2つの数字を掛けあわせ、その答えに第3の数字を足すという、D = A × B + Cという計算がよく行われます。従来のGPUでは、単精度浮動小数点用に、乗算と和算の2つの演算を1クロックで行えるMAD (Multiply-Add)命令を用意して計算を高速化していました。MAD命令では、まず切り捨て方式で乗算を行い、最近隣の偶数に丸めるかたちで加算を行います。これに対してFermiでは、単精度浮動小数点と倍精度浮動小数点の両方について、新しくFMA (Fused Multiply-Add)命令を実装しました(GT200は、倍精度についてのみFMAをサポートしていました)。FMA演算は中間段階で精度を落とすことがないため、MAD命令よりも高い精度で計算を行うことができます。

図12: Fermi世代で利用可能なFMA(Fused Multiply-Add)命令(クリックで拡大)


- この記事のキーワード
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
