はじめに
HPC業界と言えば、GPUとサーバークラスのCPUを組み合わせた構造が花盛りですが、「いつまでもこの状態が続くことはない」と、もやもやを感じている方々も多いと思います。その「もやもや」を解消すべく、FPGA屋から見たHPCについてエッセンスを紹介していきます。
HPC業界の現状と未来予想
2年前のAMD社によるXilinx社買収報道が大きく取り上げられました。FPGAの専門家を旗印にしていることもあり、銀行員、証券会社、アナリスト、居酒屋の顔なじみ、親戚や明らかに関係のなさそうな方々まで解説を求めてくる時期があり、FPGA注目度の急上昇を実感しました。日本のHPC業界ではCPUとGPUだけで十分で、FPGA屋はお帰りくださいと言われる時代もありましたが、報道の力による急変には驚愕しました。
長年にわたりFPGAと関わり続け、現状のような時代は必ず来ると予測していましたし、同じことを考えていたFPGA屋も多くいます。しかし、いざそうなると指数関数的に様々な課題が持ち込まれるようになりました(図1)。未来Aは保守的、未来Bが最も現実的、未来Cは可能性ゼロではない未来です。こう考えるとCPUはなくならないと予測されるので、Intel/AMDがFPGAベンダーを買収する意義が判ります。
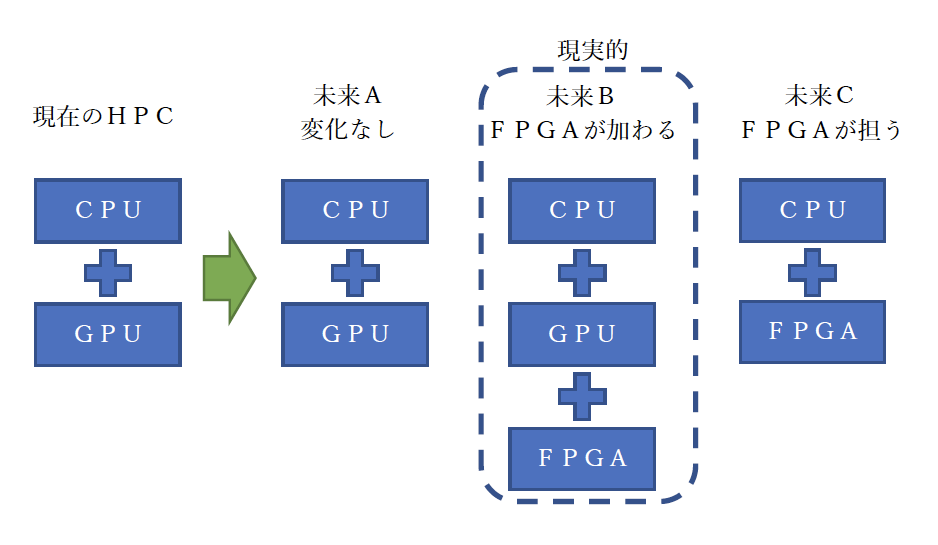
図1:未来予想図
FPGA屋を称するエンジニアは組み込み分野が活躍の場でしたが、Intel(Altera)やAMD(Xilinx)の啓蒙活動でHPC分野へ進出できるようになり、FPGAを活用したシステムの可能性に気付いたシステムベンダーなども増えてきました。そのためか、FPGAで高度な画像処理を低遅延で実現したいなどの相談や依頼が増えています。適用範囲が広く、運用中でも改良がしやすいのがFPGAの特徴ですが、実装難易度が高いのが問題点です。しかし、FPGAベンダーの弛まぬ改良と、ハイパフォーマンス志向のFPGA屋が溜めてきた経験と技術に注目が集まり、HPC分野での活用が活発化しています。
適用範囲は様々ですが、FEMに代表される科学技術系シミュレーションやリアルタイムVR映像・8K映像などに代表される高解像度の映像システムなどが多いです。それに伴い、低遅延ネットワークやストレージシステムの構築需要も増えていくと思われ、SmartNIC*1やSmartSSD*2と呼ぶ分野も登場しています。
*1:CPUで処理をしていたパケット処理を外部のデバイスに処理をさせる装置で、PCI型の基板でFPGAの適用が期待されている分野
*2:フラッシュメモリそのものを計算ストレージとして使用し、CPUを経由したアクセス時間節約を目的としたデバイス
Xilinx社が公開している資料を見ると、一時的な落ち込みはあるものの、DCG(データセンター向け)が2020年から拡大傾向であることが分かります。データセンター向け製品である同社の「ALVEO」は2019年以前に発売済みなので、ターニングポイントは2020年Q2であろうと推測しています。AMDによるXilinx社の買収も同年10月に発表がありました(表1)。
表1:四半期別の売上/DCG推移
| 四半期別 | 四半期別売上 | DCG売上額 |
|---|---|---|
| 2019年度Q4 | 828百万ドル | 41百万ドル |
| 2020年度Q1 | 850百万ドル | 42百万ドル |
| 2020年度Q2 | 833百万ドル | 83百万ドル ← ターニングポイント |
| 2020年度Q3 | 723百万ドル | 65百万ドル |
| 2020年度Q4 | 756百万ドル | 75百万ドル ← 買収発表 |
| 2021年度Q1 | 727百万ドル | 86百万ドル |
| 2021年度Q2 | 767百万ドル | 106百万ドル |
| 2021年度Q3 | 803百万ドル | 58百万ドル |
| 2021年度Q4 | 851百万ドル | 78百万ドル |
| 2022年度Q1 | 879百万ドル | 85百万ドル |
現代のFPGAは進化が目覚ましく、ライバルと称されるGPUとは大よそ下記のような異なる特徴を持っています。
- ハードウェア・パイプライニング = 超低遅延
- 必要な機能だけ実装する = 低消費電力
- メモリ管理を自由に無駄なく最小化できる = メモリリソース節約
これらを念頭にFPGA屋からHPCについて見ると、花盛りの分野と言えばAIが真っ先に思いつきますが、ビックデータ分析やストレージサービスなども含まれます。これらにもFPGAが入り込みつつありますが、普段はGPUで開発しているソフトウェアエンジニアから見ると「制御不能な機能」となります。FPGA屋から見れば「力の見せ所」となり、具体的には「ハードウェア・パイプライニング」を作り上げることになります。
ハードウェア・パイプライニング
CPUを使用する場合、Ethernetから送られてくるパケットをソフトウェアで処理しますが、必ずと言ってよいほどOS管理の下、メインメモリに転送→CACHEメモリを通過→TCP/IPのスタックプロトコル処理が実行されます(図2)。

図2:パイプライニングの考え方が違う
用途によりますが、組み込み分野ではFPGA向けにTCP/IPスタックプロトコルがハードウェア化されており、「TCP/IPオフロードエンジン=TOE」と呼ばれる技術が確立されています。日本でもIPを提供するベンダーが数社存在し、FPGA内部に実装されているCPUに頼らなくても10~100GbEの伝送を続けることが可能です。
HPC関連のベンチマーク結果を見ると、100GbEを使い切るためにサーバークラスのx86CPUで複数スレッドを立ち上げて100GbEの容量を使い切る結果が多数公表されています。一方でFPGAはTOEで実現されており、HPC業界でも低遅延・低レイテンシーを要求される処理に広く適用され、400GbEのTOEも登場間近であろうと予測しています。
TOEを適用しているサービスは実際に運用されており、HFT(High Frequency Trading)分野などに代表される金融分野はTOE+FPGAなくしては利益が確保できないほど過激な状況になっています。これらはFPGAが持つ低遅延を実現できる特徴を生かしています。それ以前のHFTは相場情報をまずTCP/IPの処理をサーバークラスのCPUで処理をしてから次に売買の処理を行い、そしてTCP/IPの処理を行って取引所に送信していました。現在はこれらすべてを「ハードウェア・パイプライニング」で処理を行い、μ秒単位で取引を行うことが可能になりました。これでは初心者投資家がこれに対抗して超短期の売買を繰り返しても利益を上げることが困難になります。
必要な機能だけ実装する
HPC業界を含め電子機器全般に言えることですが、低消費電力化について厳しい要求が突き付けられています。しかし、FPGAは低消費電力と言われていますが、「本当だろうか?」と疑念を持たれている方々も多いかと思います。その仕組みは簡単で「無駄がないから」です。GPUやCPUは休んでいる回路群にも最小限の給電を続けなければならない構造ですが、FPGAは必要ない機能を実装しなければ良いだけです。必要になれば、その機能を含めたデザインを作りリコンフィグレーションをすることで機能を達成できます。同じ機能・処理であればFPGAは無駄が少ないため消費電力が低いと言えるのです(図3)。もし、FPGAをGPUやCPUと同じトランジスタ数、同じ周波数で動作させれば、消費電力は全く変わらないでしょう。
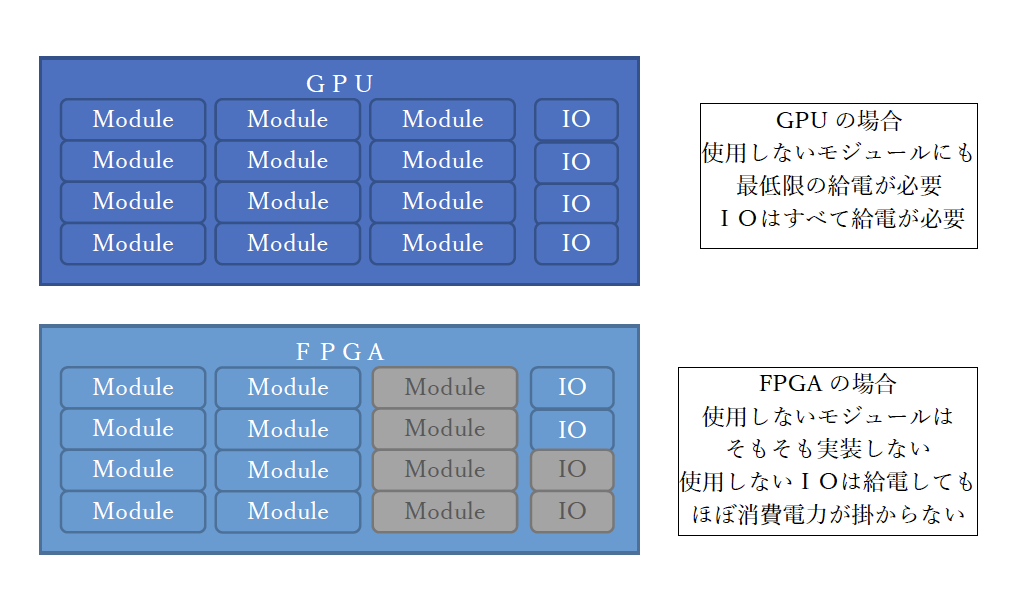
図3:消費電力の考え方の違い
また、外部バスの代表格であるDDR4-DRAMやPCI-Expressなどの消費電力はGPU、CPU、FPGAで大差ありません。消費電力を下げるためには半導体プロセスの進化に頼ることが多いですが、回路規模を縮小して動作周波数を下げる方法も同時に行われます。FPGA屋は周波数を上げることをとても嫌い、目的を達成できる「最適」な動作周波数を考えます。PCI-Expressなどの規格バスは指定されたリンク速度で通信をする必要がありますが、FPGA間の高速シリアルリンクはとても簡単なプロトコルで通信でき、消費電力を抑えることができます。
HPC分野でも消費電力削減を求められていますが、FPGA同士であれば規格バスを規格通りに動作させる必要がありません。例えば、1リンク当たり25Gbpsなど消費電力が最大になるようなリンク速度が必要ない場合は、リンク速度を落として消費電力を減らすことができます。基板上に搭載されているリファレンスクロックによる粒度の限度はありますが、おおよそ自由にリンク速度を決定でき、アプリケーション別に変更をすればHPC分野でも消費電力削減に役立ちます。
FPGAのシリアルリンクには、もう1つ利点があります。前文でも触れましたが、「簡単なプロトコル」が規定できることです。シリアルリンク全体を見るとシリアルーパラレル変換のパイプラインが最も時間コストが大きいですが、数十メートル程度の光ケーブルであれば150[ns]程度の遅延で伝送できます。PCI-Expressなどは、ソフトウエア処理でOSの介在もあり通常二けた上の遅延が発生しますが、FPGA間に限ってはシステム全体のレイテンシー改善が可能になります。さらに、高速シリアルリンクの出入口にハードウェア・パイプライニングで処理をする回路群と組み合わせれば、低消費電力かつ超低遅延な装置が実現できます。
例を挙げると、10GbE〜100GbEのラインレートでバックアップしたいファイルや画像を圧縮するハードウェア・パイプライニングを実現できます。圧縮されたデータ群をFPGAで作成されたストレージシステムに保存が可能となれば、さらに強力なデータロガーが実現できます。
上記のようなストレージシステムが完成し、ラインレートの画像保存が担保されると生産工場などのAI推論による不良品検査も大幅な性能向上が見えてきます。ソフトウェアとの大きな違いは、わざわざメモリに保存してから転送などを挟む必要がなく、カメラから送られてくる映像をそのまま検査用のAIを通しても良いわけです。
メモリ管理を自由に無駄なく
最小化できる
FPGAにはGPUにもCPUにもできない芸当が1つあります。それは「分散型内蔵SRAM」です。Xilinx社のデータシートではBlockRAM/UltraRAMと呼んでいます。Xilinx社のALVEO U55CにはBlockRAMが2,016個、UltraRAMが960個内蔵されています。1個のBlockRAMは、36bit幅x2で書き込みと読み出しが同時に実行可能なDual port SRAM構造です。さらにUltraRAMは容量288kbitで72bit幅のポートを持ち、BlockRAMと同じく書き込みと読み出しが同時にできます。これが2,016個同時に制御可能で、400MHz*3などで動作します。
*3:AC特性としては550MHzなどもっと高速ですが、ここでは控えめに計算しています
BlockRAMの性能を試算すると、
4Byte(36bitを32bitで換算) x 2,016 x 400MHz = 3,225,600MByte/sec ≒ 3.2TByte/sec
UltraRAMは、
8Byte(72bitを64bitで換算) x 960 x 400MHz = 3,072,000Mbyte/sec ≒ 3TByte/sec
合計で6TByte/secで書き込み・読み出しを同時実行できると考えれば2倍の12TByte/secの能力があると言えます。この莫大なメモリバンド幅の状態で1クロックも無駄なく制御できる優れものです(図4)。さらにU55CにはHBM2メモリが搭載されており、460GByte/secの性能が担保されています。GPUとHBM2だけで比較するとGPUが2倍以上の能力がありますが、HBM2から読み出したデータを直接処理できません。FPGAは直接処理することも、内蔵SRAMに一時保存して処理することもできます。
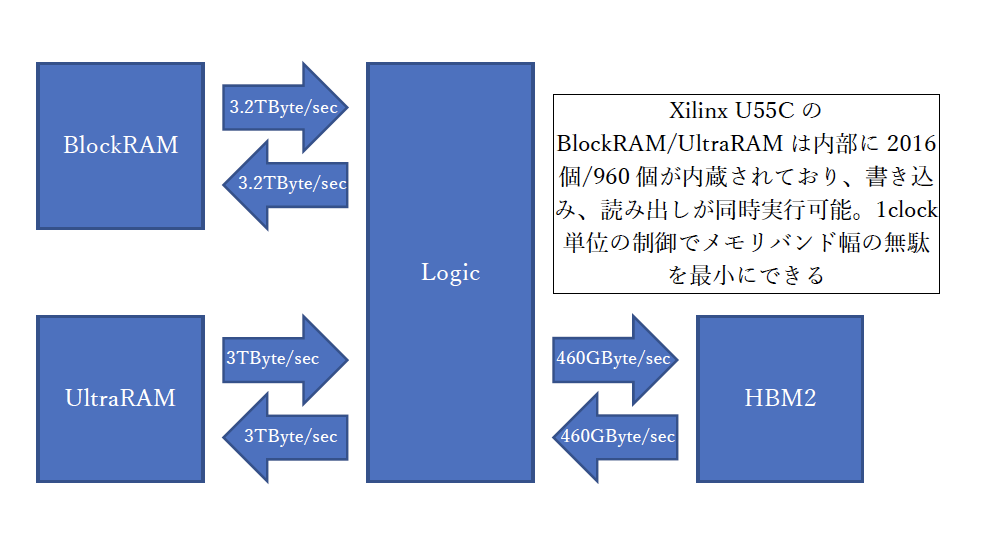
図4:FPGAのメモリ環境
「分散型内蔵SRAM」は、FPGAの性能を担保する根幹的な部分と言っても良いでしょう。この技術を使用したAI推論性能で圧倒的な結果が次々と公表されています。
対して、強化学習・深層学習はx86CPUやGPUが圧倒的に強い分野です。理由は膨大な学習データを扱い、演算精度を単精度浮動小数点、倍精度浮動小数点などのFPGAでは高速化が難しい分野だからです。CPUやGPUは構造上、必ず1次CACHEメモリに格納しないと演算できません。局所性のない莫大なデータ量を扱うとCACHEに格納する動作が邪魔になり、演算器が遊んでしまいます。
データの流れを追うと、根元のデータはSSDやNVMeなどのストレージデバイスに格納されており、ストレージ速度以上の結果は得られず、消費電力と結果の比は余り良くありません。それならばストレージデバイスと律速する演算器だけを用意すれば良いことになります。FPGA屋が考える方法は「ストレージ+演算器」となり、FPGAと大量のFlashメモリを接続した構造とし、ストレージ速度に合わせた非CACHE型の演算規模を実装することで消費電力が最適化されます。
これらの莫大なビックデータと呼ばれる学習データなどを扱う場合に問題となるのはメモリ管理の方法です。ストレージシステムは莫大な空間を扱う必要がありますが、FPGAはほぼ自由に規定できます。もちろん、64bitなどのアドレス空間は不要ですが、加えてOSやファイルシステムなどの介在も無視できます。
メモリの内容を参照できるようにバックドア構造を追加することも可能ですが、「ハードウェア・パイプライニング」を邪魔しない構造が理想的です。FPGAを使ったそのような装置は「きっと誰かが作るだろう」と容易に予測できます。
しかし、FPGAにも不得意なことがあります。GPU・CPUは潤沢なライブラリ群があり、システムが稼働するまでの開発工数がとても少なく済みます。FPGAは実現するまでの開発工数がかかりますが、短縮するためにはまずGPU・CPUで動作する物を作り、それを土台にFPGA化をするという開発方法が一般的になりつつあります。これからのHPCはGPU・CPUでサービスを開始し、需要が拡大する前にFPGA化することが一般化すると予測しています。
おわりに
近年、HPCサービスを利用している側からすると、その大きな目的は「低遅延」「低料金」「環境にやさしい」の3つと言えます。この3つの目的を実現するためには「低遅延」が解決法の1つとなります。連想ゲームのようですが「遅延が少なる⇒同じ設備体積で処理能力向上⇒消費電力削減⇒低料金で環境にやさしい」と考えています。
まとめると、次のようになります。
- ソフトウェア・オーバーヘッドを減らして超低遅延化
- 密結合化やシンプルな通信に置き換え無駄を排除して消費電力の最適化
- 処理高速化の為にシンプルなメモリ管理へ
筆者が目標としているのは「ゼロ遅延社会の実現」です。物理現象としてのゼロ遅延を実現することは難しいですが、FPGAが社会インフラをより良くするため既にHPC分野に適用され始めており、好む好まざるに拘らず拡大していくことになります。FPGAを使った「ハードウェア・パイプライニング」は組み込み分野からHPCの分野へ拡大することで「超低遅延、低消費電力でコンパクトなマシン」を可能とし、「超低遅延社会」を実現する必須のデバイスとなるでしょう。
この記事をシェアしてください
バックナンバー
この記事の筆者

Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
