新しいPostgreSQLクラスタ
はじめに最終回の今回は、現在開発中のソフトウエアであり、新しいコンセプトに基づいたデータベース・クラスタである「Postgres-XC」について紹介します。1. Postgres-XCとはPostgres-XC(XC: Extensible Cluster)は、「完全なトランザクション処理と、書き込
2010年10月26日 20:00
はじめに
最終回の今回は、現在開発中のソフトウエアであり、新しいコンセプトに基づいたデータベース・クラスタである「Postgres-XC」について紹介します。
1. Postgres-XCとは
Postgres-XC(XC: Extensible Cluster)は、「完全なトランザクション処理と、書き込み/読み込みスケール・アウトが可能な、PostgreSQLクラスタ」として現在開発が進められているソフトです(関連URL1、関連URL2)。
開発の中心は、NTTと米EnterpriseDBの2社です。開発中のコードも含め、オープン・ソースとして公開されています(開発者用のページ)。
著者は、2005年に、Think ITに「近未来データベース」を寄稿しました。ここで、データベース・クラスタによって、読み書き双方のスケール・アウトを実装できることを示しました。Postgres-XCは、この実験結果と、分散SQLの処理技術を統合したものです。
今回は、PostgreSQLのアーキテクチャ、評価、実装の現状、について解説します。
2. 書き込みスケール・アウトの難しさ
前回までに紹介したPostgreSQLのクラスタは、そのほとんどが、データベース全体のコピーを作って維持する「レプリケーション」と呼ばれる仕組みを採用しています。
レプリケーションでは、読み出しに関しては、複数サーバーで同時並列に行えます。これにより、読み出し性能は、容易にスケール・アウトします(図1)。しかし、書き込みに関しては、複数のサーバーにそれぞれ個別にデータを書き込む必要があるため、逆に性能が下がってしまう場合があります(図2)。
|
| 図1: レプリケーションによる読み出し |

|
| 図2: レプリケーションによる書き込み |
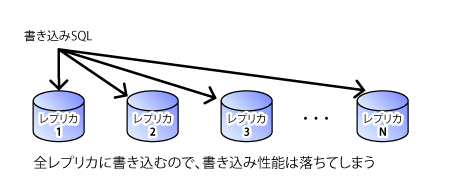
複数のデータベースへの書き込み結果を同じにすることも、簡単ではありません。特に、書き込みの時間差には注意が必要です。あるレプリカでは完了した書き込みが、隣のレプリカではまだ完了せず、結果として、読み込めるデータがレプリカの間で異なることがあります(図3)。
|
| 図3: レプリカの書き込み時間の差 |

単純なレプリケーション機能だけでは、書き込み性能をスケールさせ、なおかつ、複数のレプリカの間のデータを常に完全に同じにすることは、簡単ではないのです。
3. Postgres-XCの考え方
Postgres-XCは、単純なレプリケーションではありません。テーブルの実装方法として、テーブルのレプリカを全データベースに作成するやり方と、テーブルを各データベースに分散配置するやり方の、2種類に分けています。これらは、テーブルを作成するときに選びます。SQL文には、このための拡張を施しています。
テーブル作成時に、
CREATE TABLE ... DISTRIBUTED BY [HASH] (key);
と指定すると、このテーブルは、与えられたキー(カラム)を使って、各データベースに分散配置されます。現在、keyは整数型のカラムに限定されており、分散配置の方法はハッシュあるいはラウンドロビンが選択できます。ラウンドロビンは、キーが分かっても格納しているデータベースを特定することができないので、特殊用途です。
一方、テーブル作成時に、
CREATE TABLE ... DISTRIBUTED BY REPLICATION;
と指定すると、このテーブルは、すべてのデータベースに対して、レプリカとしてコピーされるようになります。
通常のデータベースの場合、頻繁に更新されてサイズが大きい「トランザクション・テーブル」と、比較的容量が小さくて更新頻度が少ない「マスター・テーブル」に分類されます。このため、トランザクション・テーブルを分散配置させ、マスター・テーブルをレプリカとして配置する、という選択が適しています。
こうすると、扱うデータの数が少ないトランザクション系のアプリケーションでは、1つのSQL文を1つのデータベースで処理できる場合が多くなります。結果的に、複数のデータベースで多くのトランザクションを同時並列に実行することが可能になります。これは、読み出しのSQLでも、書き込みのSQLでも、同じことです。この模様を、図4に示します。
|
| 図4: SQLの並列実行 |

このようにして、読み込み・書き込み双方のSQLを、クラスタ上の複数のデータベースで並列実行させます。これにより、読み込み・書き込みどちらのSQLの性能もスケールさせよう、というのが、Postgres-XCの考え方です。
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
