一時的な障害への対応
一時的な障害への対応
図のような構成のネットワークシステムで、拠点側のユーザーから「ネットワークが遅い」というクレームが寄せられた、という状況を想定しよう。 このとき、ネットワークのトポロジー情報を踏まえて「誰がクレームを寄せているか」を考えれば問題箇所をある程度限定できるだろう。特定の拠点のユーザーのみがクレームを寄せているのであれば、その拠点のみが利用している機器で問題が発生したと想像できるが、多数の拠点から同じようにクレームが寄せられればそれら拠点で共通に使われているリソースでのトラブル発生を疑う必要がある。
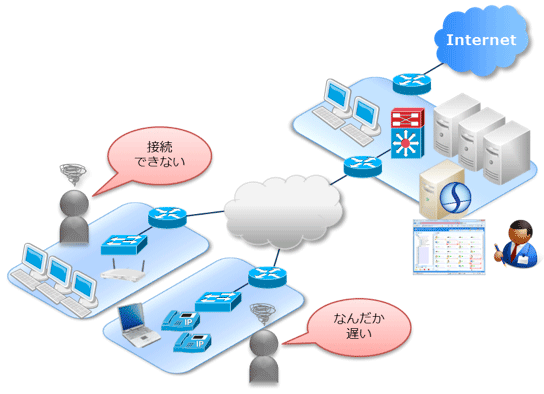
ここで、本社ネットワーク機器のレスポンス状況をグラフ表示してみると、おおよその現状がつかめ、実際にレスポンスタイムが増大傾向にあることが分かる。
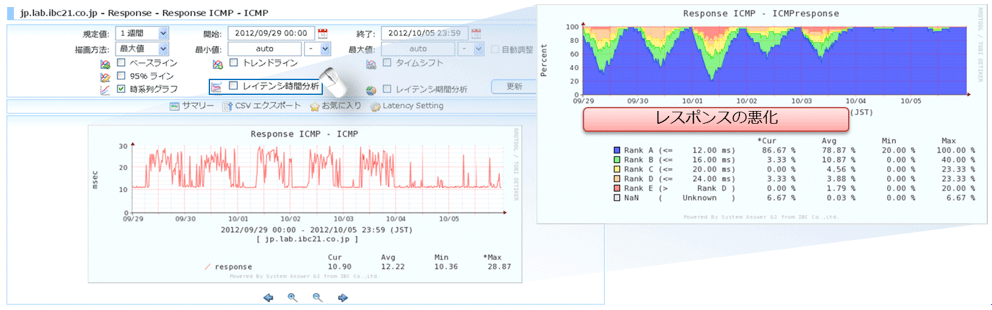
次いで「レイテンシ分析」を行ってみると、SLA基準を満たしていないことが分かり、既にトラブル発生と考えるべき状況に至っていることも分かる。このように、ツール側である程度の判断を加えた情報を視覚化してくれることで運用管理者の負担は大幅に削減され、迅速な状況把握と対処が可能になるため、インテリジェントなツールを選ぶことで効率化が達成できるはずだ。
次の問題は、このレスポンス悪化がなぜ起こっているのか原因を探ることだ。今回は、ネットワーク機器のさまざまなリソースの性能情報を並列的に比較することでレスポンス悪化と関連がありそうな項目を探してみることにした。このように、複数の情報を総合して判断を下す必要がある、という場面は意外に多い。今回はレスポンスの悪化とほぼ同期してCPU使用率が上昇していることが確認できた。 導入時点に比べて負荷が上昇したことで機器の性能が限界に達していると判断できるので、機器のリプレースを検討する必要があるということも分かってくる。
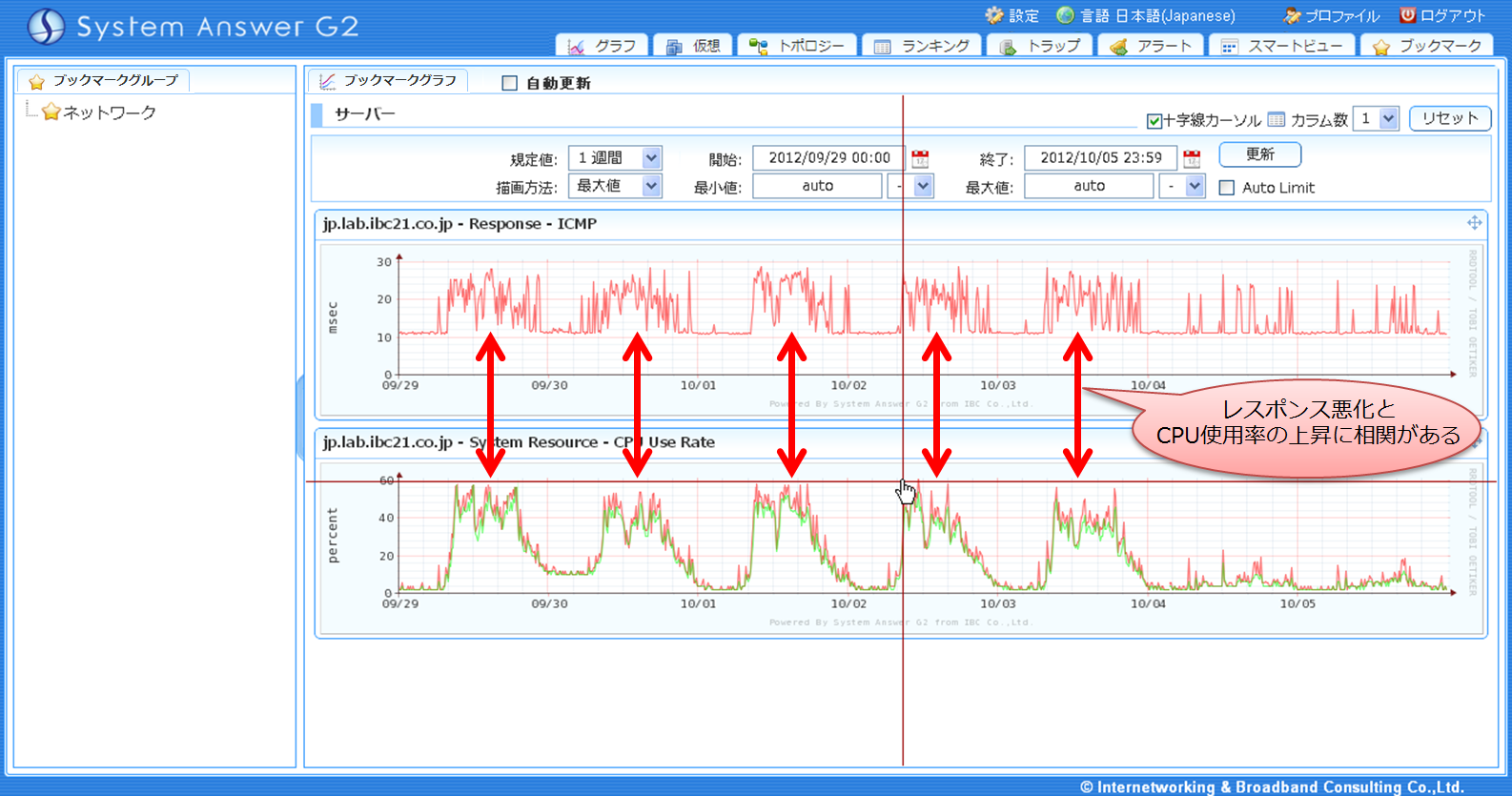
IT予算の削減や投資効率の向上が企業経営の重要な課題となっている現状で、「新しい機器が必要だ」というには相応の根拠を示す必要があるだろうが、今回得られた性能情報からは機器の処理能力不足が明確になっており、説得力のある根拠として示すことができるだろう。このように、性能監視情報を活用することで投資判断を確実にし、迅速な対応を実現することもできるのである。
一時的に発生する障害や不定期に生じるパフォーマンス低下などは、連絡を受けて調査を開始した時点では既に問題が自然に解消されてしまっていることも珍しくなく、運用管理側で状況を的確につかむことは困難であり、原因の究明も難しい。しかし、長期的な性能監視データが収集されていれば、パフォーマンスの変動状況を把握することができ、問題の解決に取り組むための重要な手がかりを得ることができる。
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
