サービスの安定稼働を阻むサイレント障害
クラウド活用に対する“耐障害性への不安感”第1回では、企業がクラウド活用を進める上での阻害要因として、“耐障害性への不安感”があることを紹介しました。クラウド・サービスを利用する側から見ると、サービスの内容ももちろん重要ですが、品質面での評価も満足できるものでなければ活用に踏み切ることは難しいでしょ
2009年12月10日 20:00
クラウド活用に対する“耐障害性への不安感”
第1回では、企業がクラウド活用を進める上での阻害要因として、“耐障害性への不安感”があることを紹介しました。クラウド・サービスを利用する側から見ると、サービスの内容ももちろん重要ですが、品質面での評価も満足できるものでなければ活用に踏み切ることは難しいでしょう。特に、基幹システムのようなミッション・クリティカル性が求められる業務については、かなり高いレベルのサービス品質が必要とされます。
このようなサービス品質を示す指標を一般的に「サービス・レベル」と呼び、具体的には、サービス提供の継続性や、サービスの応答時間(レスポンス・タイム)、障害回復時間(MTTR)、障害通知時間などで表現されます。当然、クラウドへ移行した場合も、これらのサービス・レベルを従来と同等、あるいはそれ以上に保つことが求められます。
クラウド・サービスの基盤となるデータセンターにおいてサービス・レベルを低下させる原因としては、アクセス集中によるトラフィック増加や、サーバー・リソースのキャパシティ不足によるサービス応答時間の遅延などが挙げられます。これらの課題に対しては、運用前のシステム・キャパシティの見積もりや運用後のリソース増強によって、計画的に回避することができます。
しかし、キャパシティの見積もりやリソース増強だけでは回避できず、システム・ダウンにつながるような異常の場合は、いかに迅速な対応でダウン・タイムを最小化できるかが、サービス・レベルの低下を防ぐ重要ポイントになります。
このように、“耐障害性への不安感”を取り除くためには、利用者視点で一定のサービス・レベルが維持できているかを常時監視し、異常発生時には迅速に復旧できる運用体制を示してくことが大切です。
サービス・レベル維持に不可欠なシステム監視ソフト
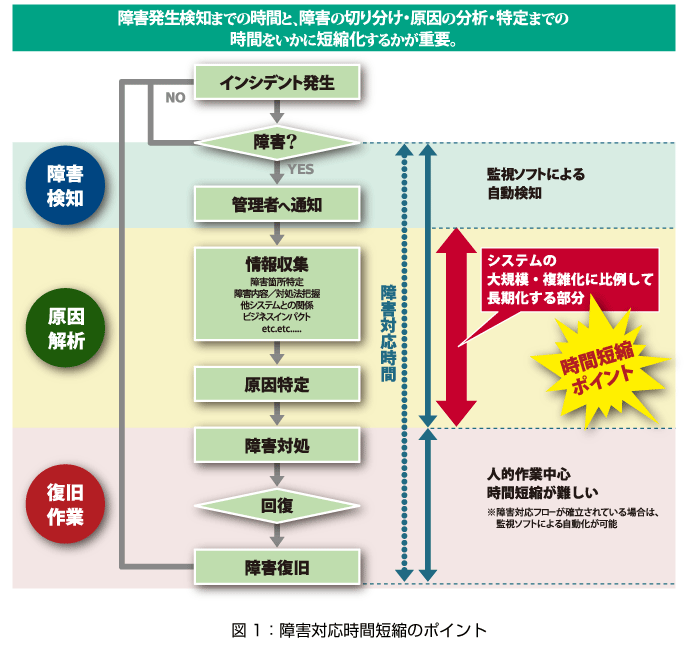
障害発生時の対応時間を短縮するためにはどのような備えが必要かを示す前に、まず、障害対応作業の流れについて詳しく見てみることにしましょう。図1で示すように、障害対応は、(1)「障害検知」、(2)「原因解析」、(3)「復旧作業」と大きく3つのフェーズに分類できます。
この中で、(3)「復旧作業」については障害の内容により対処時間が異なるため、一律に迅速化が期待できる方法は存在しません。つまり、障害対応時間は、(1)の障害発生検知までの時間と、(2)の障害の切り分け/原因の分析/特定までの時間をいかに短縮化するかに左右されることになります。
特に、(2)「原因解析」のフェーズは、障害個所の特定から他システムとの関係など、分析に必要な情報収集が必要になるため、クラウド指向データセンターのように大規模/複雑化した環境下では、分析にかかる時間も長期化する傾向にあります。したがって、データセンターの運用においては、原因解析の迅速化が障害対応時間の短縮化を実現する鍵になると言っても過言ではないでしょう。
障害検知から原因解析までの運用作業を効率化するには、システム監視ソフトの導入が有効です。障害発生を自動検知でき、管理者へのメッセージ通知で障害個所の特定と原因の絞り込みが迅速に行えるため、障害復旧までの期間を短縮化することが可能となります。
こうした理由から、ミッション・クリティカル性が要求されるシステムにおいて一定のサービス・レベルを維持するために、システム管理ソフトが必要不可欠な存在になっています。しかし、障害の中には、従来のシステム監視ソフトでは検知できない、あるいは見落としてしまう障害が存在することをご存じでしょうか。
次ページからは、こうした、従来のシステム監視ソフトでは検知することが困難な障害について解説します。
- この記事のキーワード
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
