“障害発生前の解決”をどうやって実現するか
データセンター環境で“監視”といえば、まず思い浮かぶのは「死活監視」だろう。文字通り、サーバが「生きている(稼働している)か、死んでいる(停止している)か」を見極める簡便な手法だ。これだけで用が足りる場合ももちろんあるが、それだけでは複雑化する現在のシステム構成には対応しきれないという課題が明らか
2012年6月20日 20:00
データセンター環境で“監視”といえば、まず思い浮かぶのは「死活監視」だろう。文字通り、サーバが「生きている(稼働している)か、死んでいる(停止している)か」を見極める簡便な手法だ。
これだけで用が足りる場合ももちろんあるが、それだけでは複雑化する現在のシステム構成には対応しきれないという課題が明らかになってきている。
今回は、死活監視の限界と、これから欠かせない存在となるサーバ性能監視のポイントについて考える。
死活監視の限界
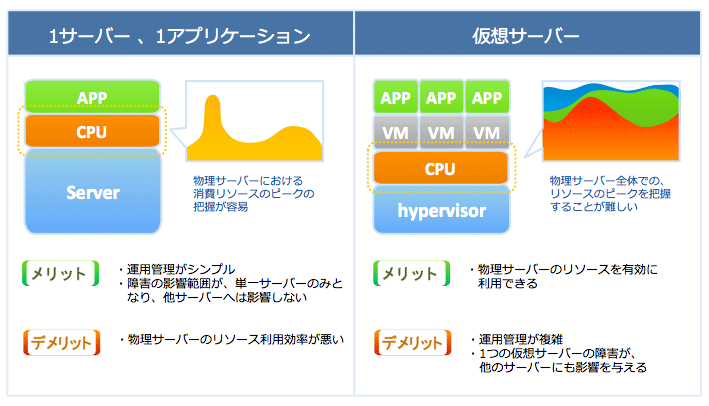
物理サーバの処理能力を無駄なく使うには
死活監視は、端的に言ってしまえば「1サーバ、1アプリケーション」構成を前提とした、ごく簡便な監視手法である。
Webサーバでは、現在でも1Uラックマウントサーバをラック一杯に詰め込み、それぞれのサーバでは必要最小限の構成のOSとWebサーバ・ソフトウェアだけが稼働している、といったシステムが使われるが、こうした使い方なら、死活監視は簡便でありながら最低限の確認ができる手法と評価できる。少なくとも、「やらないよりはマシ」ということにはなるだろう。
だが、単一のワークロードが物理サーバを占有するという構成は、運用管理をシンプルにし、障害の影響が他のワークロードに波及することを未然に防ぐという観点からは優れているといえるが、物理サーバのリソースを効率的に利用するという観点からは極めて無駄が多い使い方でもある。
最近のサーバはプロセッサのマルチコア化が進んでいることもあって、単一のワークロードでその処理能力を使い切ることは難しくなっている。物理サーバの処理能力を無駄なく使い切るためには、複数のワークロードを共存させる必要がある。
|
| 図1:サーバー構成での比較(クリックで拡大) |
仮想サーバーのリソース消費量が問題に
こうした状況を受けて、現在ではサーバを仮想化し、複数の仮想サーバで1台の物理サーバを共用する構成が一般的になってきている。この場合、個々の仮想サーバの単位で見れば“OS上で稼働しているワークロードは1つだけ”というシンプルな構成を維持しつつ、物理サーバ上で複数の仮想サーバが同時に稼働するため、ハードウェアの処理能力を有効に活用できる。
しかし、リソース利用の効率化のためにはサーバ仮想化はまさに理想的なソリューションといえるが、運用管理に関しては従来の手法のままでは対応できない部分が出てくる。
典型的な例は、ある仮想サーバがリソースを過大に消費してしまったせいで、他の仮想サーバの動作に影響が及ぶ場合である。この時、物理サーバが生きているか死んでいるかを判定するだけでは、状況を正しく把握することはできない。仮想サーバごとに「どのくらいのリソースを確保できているか」「どのくらいの性能で処理が実行できているか」といった詳細な情報がないと判断できないことになる。
実利用レベルでチェックすればいいかというと、そんなに単純な話ではない
また、死活監視では障害が起きているものの一見しただけではわかりにくい、いわゆる“サイレント障害”を見逃してしまうリスクもある。例えば、“死んではいないが息も絶え絶え”という状況でも、pingなどのネットワークコマンドには応答が返ってくることもあり、この場合は「生きている」と判定して終わりになってしまうだろう。
pingに限らないが、死活監視では通常ごく小さなパケットのやりとりに基づいてサーバの生き死にを判断するため、何らかの障害によって処理性能が低下していても見逃してしまうことが珍しくない。
では、アプリケーションレベルで実際にアクセスしてみれば良いかというと、そう単純な話でもないところに運用監視の難しさがある。例えば、Webサーバの稼働状況を知るためには、実際にWebブラウザでアクセスしてみればよいというものではないのだ。
なぜかというと、監視のためにアクセスがサーバに余分な負荷を与えてしまい、本来のユーザーアクセスのレスポンスを低下させてしまうおそれがあるからだ。仮に、Webページがなかなか表示されないといったトラブルの兆候がつかめたとしても、その根本原因がサーバの処理性能が逼迫(ひっぱく)しているためなのか、あるいは途中のネットワークに何か障害が発生しているのかなど、即座に分かるわけではないという問題もある。
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
