BigTableの実装
BigTableの実装
データベースであるBigTableでは、前述のデータモデルに基づくテーブルを幾つかに区分して複数のコンピューターに分散させて管理しています。この区分されたテーブルの断片をタブレット(tablet)と呼びます。このような方式を採用するとテーブル管理の負荷を複数のコンピューターに分散させることできデータ検索も並列的に実行できるメリットがあります。
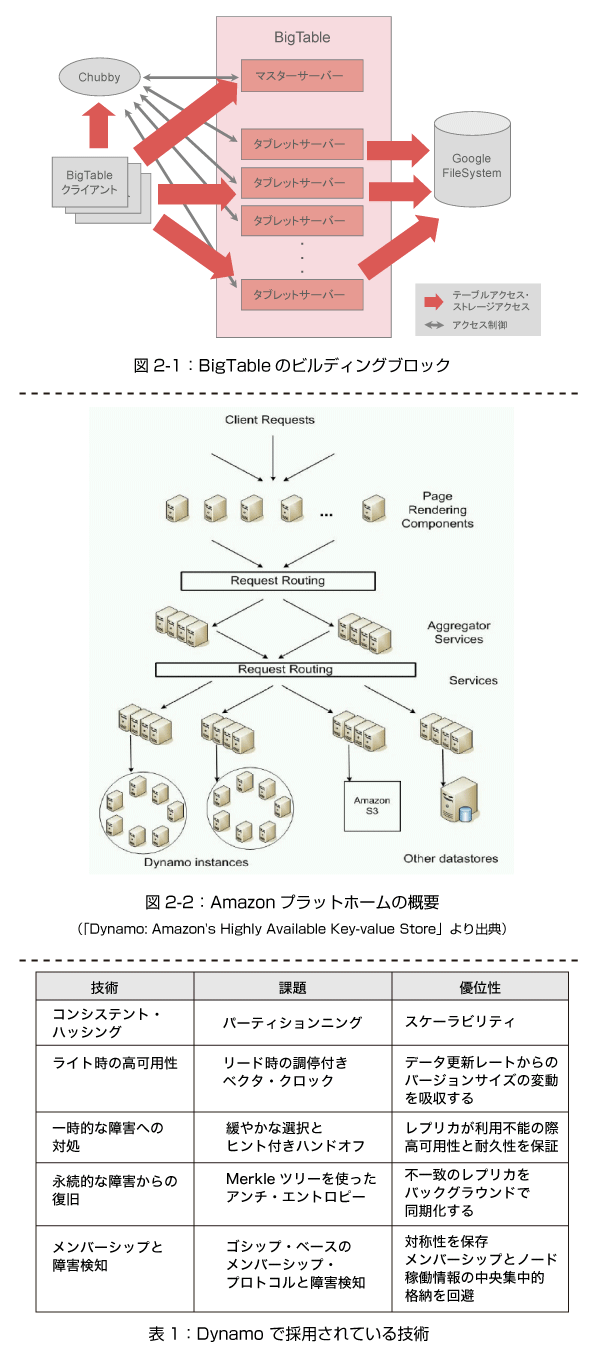
実際のBigTableの実装ではGoogle File System(GFS)[1]やChubby [2]といったGoogleのほかのコンポーネントと連動して動作します。図2-1はBigTableのビルディングブロックを示したものですが、稼働ログやデータなど稼働時にBigTableが使用するファイルはGFSに格納されます。
すなわちGFSはBigTableの下位に位置するストレージとして機能します。一方、分散ロックマネージャであるChubbyはBigTableで発生するさまざまなアクセス競合を調停する目的で使用されています。
BigTable自体はマスターサーバー、タブレットサーバーおよびアクセスライブラリをリンクしたクライアントの、3つのコンポーネントにより動作します。
マスターサーバーは常に1台だけが稼働し、タブレットサーバーへのタブレットの割り当て、タブレットサーバーの稼働状態の監視や負荷分散、BigTableの動作によってGFSに残されるゴミファイルの回収(ガベージ・コレクション)を担当します。
一方タブレットサーバーはマスターサーバーから割り当てられた、複数のタブレットの管理を行い、BigTableの負荷状態に応じて動作する台数を増減させることが可能です。
アクセスライブラリをリンクしたクライアントは、利用しているテーブルを構成するタブレットの配置(格納しているタブレットサーバー)に関する情報をキャッシュしているので、マスターサーバーとはほとんど通信を行うことはありません。
クライアントがマスターサーバーと通信を行うのは、利用しようとしているテーブル(タブレット)の配置情報をキャッシュしていない場合、あるいはタブレットサーバーの異常停止などによってキャッシュしている配置情報に誤りがある場合などに限られます。したがってマスターサーバーに負荷が集中することはめったにありません。
Amazon Dynamo
GoogleのBigTableでは、サーチエンジンを始め、Googleが公開するさまざまなアプリケーションが必要とするデータ・リポジトリを実現するために開発されました。
これは、ウェブページのクローリングなどから得た大量データの解析から新たな価値を見つけ出すことを目的としているGoogleのサービスを支えるために、大量のデータを高速にスキャンできるリポジトリが不可欠だったからです。
バッチ処理的に実行される解析ソフトウエアの実行時間を短縮するため、必然的にハイスループットのデータストレージが求められます。
「大容量データはGFSで大量データはBigTableで対応する」というのがGoogleの基本的な技術戦略と言えるでしょう。
AmazonのDynamoは、こういったGoogleのBigTableとは対照的なデータベースと言えるかもしれません。これは両者が開発された背景の違いに起因すると思われます。
Eコマースの事業者であるAmazonにとっては、商品をオーダーする顧客への速やかな応答が最重要課題です。ハイスループットよりもローレイテンシーを重視する彼らの姿勢は、Dynamoに関する論文[3]でも強調されています。
図2-2はDynamoを開発する上での前提となるAmazonプラットホームの概要です。この図からは、Amazonプラットホームはサービス指向アーキテクチャーを採用するウェブサイトそのものであることや、一般的なデータセンターのアーキテクチャーと共通するところが多々見られます。
Dynamoは図中の最下段左端に位置し、その隣にS3のサーバー群が書かれていることから、Amazon Web Service(AWS)を担うシステムとして開発されたわけではないことが分かります。
DynamoはEコマースでは必須の、トランザクション処理をスケールアウトするクラスタにおいて実現する、技術的困難度の高い野心的な試みであり、Amazon 自身の Service Level Agreement(SLA)を慎重に吟味することによりシステムが保証する範囲を実用性が確保できるレベルまで緩和する現実的なアプローチにより開発されました。
表1にDynamoに用いられている技術を列挙します。技術の詳細は[3]の解説をご覧いただくとして、全体的に概観すると自律分散システムの研究成果を総動員することで、開発者が言う“zero-hop DHT”(ゼロ・ホップでノード探索が可能な分散ハッシュテーブル)が実現されていることが分かります。
[1] Bigtable: A Distributed Storage System for Structured Data(http://research.google.com/archive/bigtable-osdi06.pdf)(アクセス:2009.09)
[2] The Google File System(http://labs.google.com/papers/gfs.html)(アクセス:2009.09)
[3] Dynamo: Amazon's Highly Available Key-value Store(http://s3.amazonaws.com/AllThingsDistributed/sosp/amazon-dynamo-sosp2007.pdf)(アクセス:2009.09)
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
