クラウド向け分散データベースの事例
はじめに 本連載ではクラウドコンピューティングで利用される分散データベースの技術について紹介しています。第1回はクラウドコンピューティングの技術について概説し、その環境に対応するための新たな分散データベースの必要性について述べました。
2009年9月11日 20:00
はじめに
本連載ではクラウドコンピューティングで利用される分散データベースの技術について紹介しています。第1回はクラウドコンピューティングの技術について概説し、その環境に対応するための新たな分散データベースの必要性について述べました。
今回はクラウド向け分散データベースの具体的な事例として、Googleの「BigTable」とAmazonの「Dynamo」について紹介したいと思います。少し耳慣れない言葉も出てくるかと思いますが、最後までお付き合いいただけると幸いです。
一般にハイスループット(高効率)とローレイテンシー(低遅延)がトレードオフの関係にあることはよく知られていますが、クラウドシステムもその例外ではありません。これらは最近でも、クラウド技術のシステム特性を理解する上で欠かせないトピックですが、分散データベースに関しては、ハイスループット重視のBigTableに対し、ローレイテンシー重視のDynamoと、両者を対比してとらえられることが多いようです。
Google BigTable
GoogleのBigTableはクラウド向け分散データベースの草分け的存在とも言えますが、Google自身はこのシステムをデータベースではなく「構造化されたデータを管理するための分散ストレージ」と説明しています。
つまり、先に開発されたGoogle File Systemが大容量ファイルの格納に最適化されたファイルシステムなのに対し、BigTableでは大量の小容量データの格納・管理を担うストレージシステムの実現を目指していたと推測されます。
さらに加えるなら、膨大なデータコレクションから望むデータを容易に見つけ出すために、データベースに似た検索機能をサポートする必要があったのでしょう。
このようなストレージはリレーショナルモデルに基づく既存のデータベースシステムでも容易に実現できます。しかし前回説明したRDBMSのスケーラビリティ問題(http://thinkit.jp/article/1020/2/)を重視したGoogleは、既存のRDBMSを廃して新たに独自のシステムを開発した。それがBigTableの開発経緯だったように思います。
この選択は既存RDBMSを極限まで活用しようとするSalesForceのシステムとは対照的で、非常に興味深い考え方です。
■BigTable のデータモデル
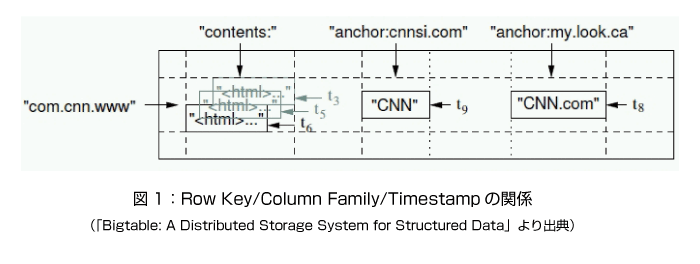
BigTable の特徴はRow Key/Column Family/Timestampで定義されるデータモデルにも現れています。
図1はRow Key/Column Family/Timestampの関係を図で示したものです。おのおの細かな定義の説明はページ下部のリンク[1]に譲りますが、これはウェブページを表現した事例です。このエントリ例は“com.cnn.www”のページを表現していて、そのページ内容、“cnnsi.com”からこのページを参照する際のアンカー“my.look.ca”から、このページを参照する際のアンカーが格納されています。
これをBigTableのデータモデルで表現すると、“contents”と“anchor”の、2つのColumn Familyが定義されており、“anchor”Column Familyには、“anchor:cnnsi.com”と“anchor:my.look.ca”の2つのColumが追加されています。
このようにBigTableではColum Familyはあらかじめ定義する必要がありますが、Colum Familyに含まれる個々のColumnは動的に追加することができます。
さらにRow Keyが“com.cnn.www”のエントリ“contents”Column Familyにはフェッチ時間がおのおのt3/t5/t6の3世代分のページ内容が格納され、Column“anchor:cnnsi.com”には“CNN”がColumn“anchor:my.look.ca”には“CNN.com”が格納されます。
留意すべきポイントは、timestampを使って時系列的にデータを格納できる点です。さらにBigTableが扱うすべてのデータは原則として任意のバイト列であり、クライアントに対してこれらバイト列へのシリアライズ、デシリアライズ方法を定義する手段を提供するものの、BigTable自体はデータの構造や型を解釈しないことが挙げられます。
Googleによれば「一般的なデータベースよりも単純なデータモデル」と説明されていますが、BigTableはデータベース・エンジンを簡略化することにより大きなスケーラビリティを達成しています。
利用者の視点では、BigTableは既存のRDBMSよりも機能が少ない、よりデータストレージ的なデータベースに見えるでしょう。しかしながら今日のウェブアプリケーションなどでは、もともとバックエンドデータベースをストレージ的に活用する利用法が定着しているので、こういったニーズにはBigTableはフィットすると思われます。
[1] Bigtable: A Distributed Storage System for Structured Data(http://research.google.com/archive/bigtable-osdi06.pdf)(アクセス:2009.09)
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
